Model Ensembles Are Faster Than You Think
November 10, 2021
Posted by Xiaofang Wang, Intern and Yair Alon (prev. Movshovitz-Attias), Software Engineer, Google Research
Quick links
When building a deep model for a new machine learning application, researchers often begin with existing network architectures, such as ResNets or EfficientNets. If the initial model’s accuracy isn’t high enough, a larger model may be a tempting alternative, but may not actually be the best solution for the task at hand. Instead, better performance potentially could be achieved by designing a new model that is optimized for the task. However, such efforts can be challenging and usually require considerable resources.
In “Wisdom of Committees: An Overlooked Approach to Faster and More Accurate Models”, we discuss model ensembles and a subset called model cascades, both of which are simple approaches that construct new models by collecting existing models and combining their outputs. We demonstrate that ensembles of even a small number of models that are easily constructed can match or exceed the accuracy of state-of-the-art models while being considerably more efficient.
What Are Model Ensembles and Cascades?
Ensembles and cascades are related approaches that leverage the advantages of multiple models to achieve a better solution. Ensembles execute multiple models in parallel and then combine their outputs to make the final prediction. Cascades are a subset of ensembles, but execute the collected models sequentially, and merge the solutions once the prediction has a high enough confidence. For simple inputs, cascades use less computation, but for more complex inputs, may end up calling on a greater number of models, resulting in higher computation costs.
 |
| Overview of ensembles and cascades. While this example shows 2-model combinations for both ensembles and cascades, any number of models can potentially be used. |
Compared to a single model, ensembles can provide improved accuracy if there is variety in the collected models’ predictions. For example, the majority of images in ImageNet are easy for contemporary image recognition models to classify, but there are many images for which predictions vary between models and that will benefit most from an ensemble.
While ensembles are well-known, they are often not considered a core building block of deep model architectures and are rarely explored when researchers are developing more efficient models (with a few notable exceptions [1, 2, 3]). Therefore, we conduct a comprehensive analysis of ensemble efficiency and show that a simple ensemble or cascade of off-the-shelf pre-trained models can enhance both the efficiency and accuracy of state-of-the-art models.
To encourage the adoption of model ensembles, we demonstrate the following beneficial properties:
- Simple to build: Ensembles do not require complicated techniques (e.g., early exit policy learning).
- Easy to maintain: Ensembles are trained independently, making them easy to maintain and deploy.
- Affordable to train: The total training cost of models in an ensemble is often lower than a similarly accurate single model.
- On-device speedup: The reduction in computation cost (FLOPS) successfully translates to a speedup on real hardware.
Efficiency and Training Speed
It’s not surprising that ensembles can increase accuracy, but using multiple models in an ensemble may introduce extra computational cost at runtime. So, we investigate whether an ensemble can be more accurate than a single model that has the same computational cost. We analyze a series of models, EfficientNet-B0 to EfficientNet-B7, that have different levels of accuracy and FLOPS when applied to ImageNet inputs. The ensemble predictions are computed by averaging the predictions of each individual model.
We find that ensembles are significantly more cost-effective in the large computation regime (>5B FLOPS). For example, an ensemble of two EfficientNet-B5 models matches the accuracy of a single EfficientNet-B7 model, but does so using ~50% fewer FLOPS. This demonstrates that instead of using a large model, in this situation, one should use an ensemble of multiple considerably smaller models, which will reduce computation requirements while maintaining accuracy. Moreover, we find that the training cost of an ensemble can be much lower (e.g., two B5 models: 96 TPU days total; one B7 model: 160 TPU days). In practice, model ensemble training can be parallelized using multiple accelerators leading to further reductions. This pattern holds for the ResNet and MobileNet families as well.
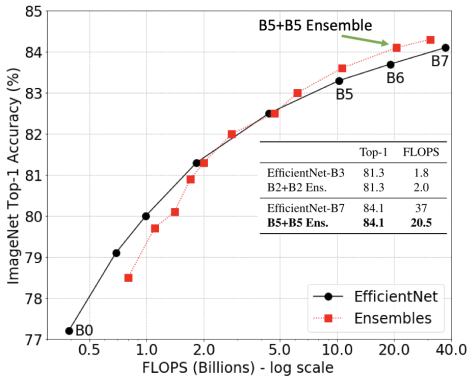 |
| Ensembles outperform single models in the large computation regime (>5B FLOPS). |
Power and Simplicity of Cascades
While we have demonstrated the utility of model ensembles, applying an ensemble is often wasteful for easy inputs where a subset of the ensemble will give the correct answer. In these situations, cascades save computation by allowing for an early exit, potentially stopping and outputting an answer before all models are used. The challenge is to determine when to exit from the cascade.
To highlight the practical benefit of cascades, we intentionally choose a simple heuristic to measure the confidence of the prediction — we take the confidence of the model to be the maximum of the probabilities assigned to each class. For example, if the predicted probabilities for an image being either a cat, dog, or horse were 20%, 80% and 20%, respectively, then the confidence of the model's prediction (dog) would be 0.8. We use a threshold on the confidence score to determine when to exit from the cascade.
To test this approach, we build model cascades for the EfficientNet, ResNet, and MobileNetV2 families to match either computation costs or accuracy (limiting the cascade to a maximum of four models). By design in cascades, some inputs incur more FLOPS than others, because more challenging inputs go through more models in the cascade than easier inputs. So we report the average FLOPS computed over all test images. We show that cascades outperform single models in all computation regimes (when FLOPS range from 0.15B to 37B) and can enhance accuracy or reduce the FLOPS (sometimes both) for all models tested.
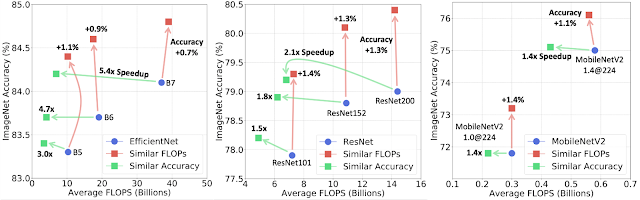 |
| Cascades of EfficientNet (left), ResNet (middle) and MobileNetV2 (right) models on ImageNet. When using similar FLOPS, cascades obtain a higher accuracy than single models (shown by the red arrows pointing up). Cascades can also match the accuracy of single models with significantly fewer FLOPS e.g., 5.4x for B7 (green arrows pointing left). |
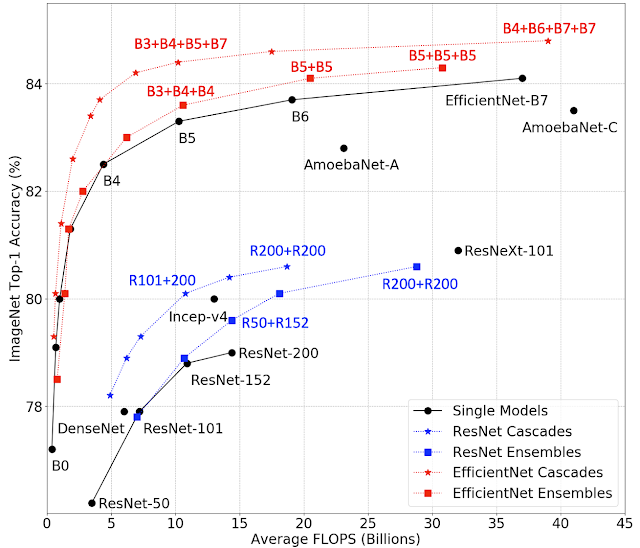 |
| Summary of accuracy vs. FLOPS for ensembles and cascades. Squares and stars represent ensembles and cascades, respectively,, and the “+” notation indicates the models that comprise the ensemble or cascade. For example, ”B3+B4+B5+B7” at a star refers to a cascade of EfficientNet-B3, B4, B5 and B7 models. |
In some cases it is not the average computation cost but the worst-case cost that is the limiting factor. By adding a simple constraint to the cascade building procedure, one can guarantee an upper bound to the computation cost of the cascade. See the paper for more details.
Other than convolutional neural networks, we also consider a Transformer-based architecture, ViT. We build a cascade of ViT-Base and ViT-Large models to match the average computation or accuracy of a single state-of-the-art ViT-Large model, and show that the benefit of cascades also generalizes to Transformer-based architectures.
 |
| Cascades of ViT models on ImageNet. “224” and “384” indicate the image resolution on which the model is trained. Throughput is measured as the number of images processed per second. Our cascades can achieve a 1.0% higher accuracy than ViT-L-384 with a similar throughput or achieve a 2.3x speedup over that model while matching its accuracy. |
Earlier works on cascades have also shown efficiency improvements for state-of-the-art models, but here we demonstrate that a simple approach with a handful of models is sufficient.
Inference Latency
In the above analysis, we average FLOPS to measure the computational cost. It is also important to verify that the FLOPS reduction obtained by cascades actually translates into speedup on hardware. We examine this by comparing on-device latency and speed-up for similarly performing single models versus cascades. We find a reduction in the average online latency on TPUv3 of up to 5.5x for cascades of models from the EfficientNet family compared to single models with comparable accuracy. As models become larger the more speed-up we find with comparable cascades.
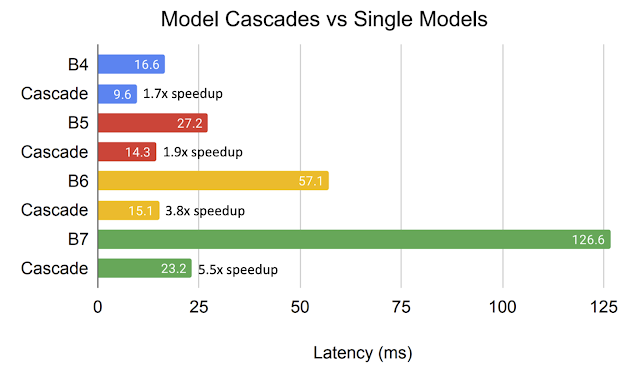 |
| Average latency of cascades on TPUv3 for online processing. Each pair of same colored bars has comparable accuracy. Notice that cascades provide drastic latency reduction. |
Building Cascades from Large Pools of Models
Above, we limit the model types and only consider ensembles/cascades of at most four models. While this highlights the simplicity of using ensembles, it also allows us to check all combinations of models in very little time so we can find optimal model collections with only a few CPU hours on a held out set of predictions.
When a large pool of models exists, we would expect cascades to be even more efficient and accurate, but brute force search is not feasible. However, efficient cascade search methods have been proposed. For example, the algorithm of Streeter (2018), when applied to a large pool of models, produced cascades that matched the accuracy of state-of-the-art neural architecture search–based ImageNet models with significantly fewer FLOPS, for a range of model sizes.
Conclusion
As we have seen, ensemble/cascade-based models obtain superior efficiency and accuracy over state-of-the-art models from several standard architecture families. In our paper we show more results for other models and tasks. For practitioners, this outlines a simple procedure to boost accuracy while retaining efficiency using off-the-shelf models. We encourage you to try it out!
Acknowledgement
This blog presents research done by Xiaofang Wang (while interning at Google Research), Dan Kondratyuk, Eric Christiansen, Kris M. Kitani, Yair Alon (prev. Movshovitz-Attias), and Elad Eban. We thank Sergey Ioffe, Shankar Krishnan, Max Moroz, Josh Dillon, Alex Alemi, Jascha Sohl-Dickstein, Rif A Saurous, and Andrew Helton for their valuable help and feedback.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
