MobileNetV2: The Next Generation of On-Device Computer Vision Networks
April 3, 2018
Posted by Mark Sandler and Andrew Howard, Google Research
Quick links
Last year we introduced MobileNetV1, a family of general purpose computer vision neural networks designed with mobile devices in mind to support classification, detection and more. The ability to run deep networks on personal mobile devices improves user experience, offering anytime, anywhere access, with additional benefits for security, privacy, and energy consumption. As new applications emerge allowing users to interact with the real world in real time, so does the need for ever more efficient neural networks.
Today, we are pleased to announce the availability of MobileNetV2 to power the next generation of mobile vision applications. MobileNetV2 is a significant improvement over MobileNetV1 and pushes the state of the art for mobile visual recognition including classification, object detection and semantic segmentation. MobileNetV2 is released as part of TensorFlow-Slim Image Classification Library, or you can start exploring MobileNetV2 right away in Colaboratory. Alternately, you can download the notebook and explore it locally using Jupyter. MobileNetV2 is also available as modules on TF-Hub, and pretrained checkpoints can be found on github.
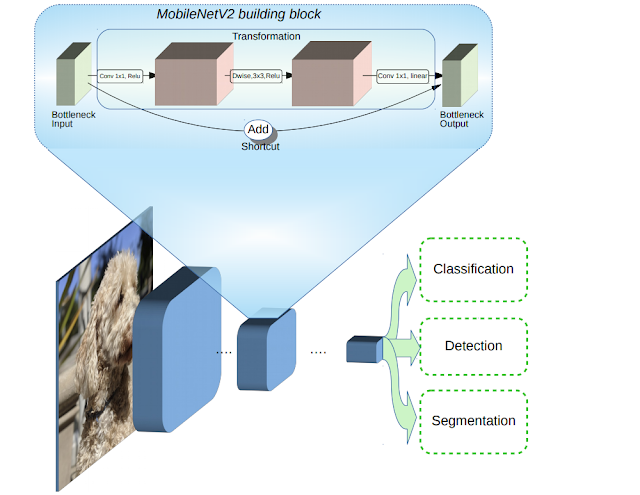
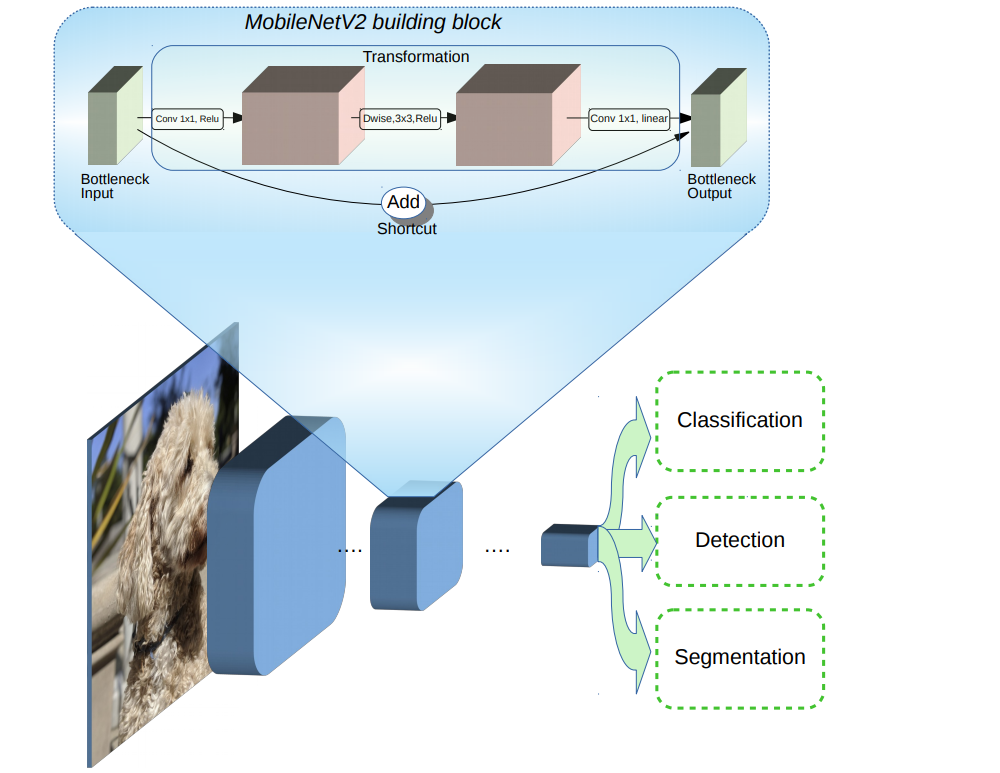
MobileNetV2 builds upon the ideas from MobileNetV1 [1], using depthwise separable convolution as efficient building blocks. However, V2 introduces two new features to the architecture: 1) linear bottlenecks between the layers, and 2) shortcut connections between the bottlenecks1. The basic structure is shown below.
 |
| Overview of MobileNetV2 Architecture. Blue blocks represent composite convolutional building blocks as shown above. |
How does it compare to the first generation of MobileNets?
Overall, the MobileNetV2 models are faster for the same accuracy across the entire latency spectrum. In particular, the new models use 2x fewer operations, need 30% fewer parameters and are about 30-40% faster on a Google Pixel phone than MobileNetV1 models, all while achieving higher accuracy.
 |
| MobileNetV2 improves speed (reduced latency) and increased ImageNet Top 1 accuracy |
Model | Params | Multiply-Adds | mAP | Mobile CPU |
MobileNetV1 + SSDLite | 5.1M | 1.3B | 22.2% | 270ms |
4.3M | 0.8B | 22.1% | 200ms |
To enable on-device semantic segmentation, we employ MobileNetV2 as a feature extractor in a reduced form of DeepLabv3 [3], that was announced recently. On the semantic segmentation benchmark, PASCAL VOC 2012, our resulting model attains a similar performance as employing MobileNetV1 as feature extractor, but requires 5.3 times fewer parameters and 5.2 times fewer operations in terms of Multiply-Adds.
Model | Params | Multiply-Adds | mIOU |
MobileNetV1 + DeepLabV3 | 11.15M | 14.25B | 75.29% |
2.11M | 2.75B | 75.32% |
As we have seen MobileNetV2 provides a very efficient mobile-oriented model that can be used as a base for many visual recognition tasks. We hope by sharing it with the broader academic and open-source community we can help to advance research and application development.
Acknowledgements:
We would like to acknowledge our core contributors Menglong Zhu, Andrey Zhmoginov and Liang-Chieh Chen. We also give special thanks to Bo Chen, Dmitry Kalenichenko, Skirmantas Kligys, Mathew Tang, Weijun Wang, Benoit Jacob, George Papandreou, Zhichao Lu, Vivek Rathod, Jonathan Huang, Yukun Zhu, and Hartwig Adam.
References
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, Howard AG, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T, Andreetto M, Adam H, arXiv:1704.04861, 2017.
- MobileNetV2: Inverted Residuals and Linear Bottlenecks, Sandler M, Howard A, Zhu M, Zhmoginov A, Chen LC. arXiv preprint. arXiv:1801.04381, 2018.
- Rethinking Atrous Convolution for Semantic Image Segmentation, Chen LC, Papandreou G, Schroff F, Adam H. arXiv:1706.05587, 2017.
- Speed/accuracy trade-offs for modern convolutional object detectors, Huang J, Rathod V, Sun C, Zhu M, Korattikara A, Fathi A, Fischer I, Wojna Z, Song Y, Guadarrama S, Murphy K, CVPR 2017.
- Deep Residual Learning for Image Recognition, He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. arXiv:1512.03385,2015
1 The shortcut (also known as skip) connections, popularized by ResNets[5] are commonly used to connect the non-bottleneck layers. MobilenNetV2 inverts this notion and connects the bottlenecks directly.↩
Quick links
Other posts of interest
-

March 12, 2026
Protecting cities with AI-driven flash flood forecasting- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets
×
❮
❯

