MnasNet: Towards Automating the Design of Mobile Machine Learning Models
August 7, 2018
Posted by Mingxing Tan, Software Engineer, Google Brain Team
Quick links
Convolutional neural networks (CNNs) have been widely used in image classification, face recognition, object detection and many other domains. Unfortunately, designing CNNs for mobile devices is challenging because mobile models need to be small and fast, yet still accurate. Although significant effort has been made to design and improve mobile models, such as MobileNet and MobileNetV2, manually creating efficient models remains challenging when there are so many possibilities to consider. Inspired by recent progress in AutoML neural architecture search, we wondered if the design of mobile CNN models could also benefit from an AutoML approach.
In “MnasNet: Platform-Aware Neural Architecture Search for Mobile”, we explore an automated neural architecture search approach for designing mobile models using reinforcement learning. To deal with mobile speed constraints, we explicitly incorporate the speed information into the main reward function of the search algorithm, so that the search can identify a model that achieves a good trade-off between accuracy and speed. In doing so, MnasNet is able to find models that run 1.5x faster than state-of-the-art hand-crafted MobileNetV2 and 2.4x faster than NASNet, while reaching the same ImageNet top 1 accuracy.
Unlike in previous architecture search approaches, where model speed is considered via another proxy (e.g., FLOPS), our approach directly measures model speed by executing the model on a particular platform, e.g., Pixel phones which were used in this research study. In this way, we can directly measure what is achievable in real-world practice, given that each type of mobile device has its own software and hardware idiosyncrasies and may require different architectures for the best trade-offs between accuracy and speed.
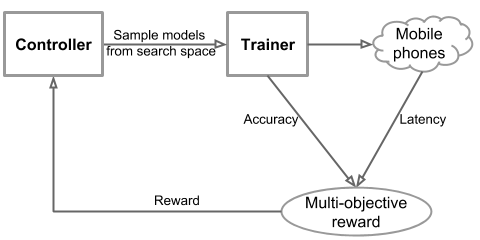
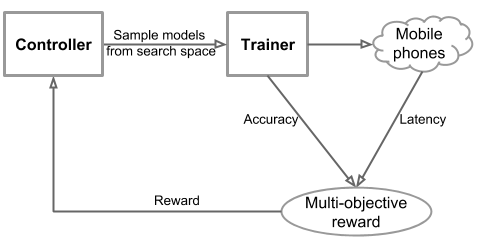
The overall flow of our approach consists mainly of three components: a RNN-based controller for learning and sampling model architectures, a trainer that builds and trains models to obtain the accuracy, and an inference engine for measuring the model speed on real mobile phones using TensorFlow Lite. We formulate a multi-objective optimization problem that aims to achieve both high accuracy and high speed, and utilize a reinforcement learning algorithm with a customized reward function to find Pareto optimal solutions (e.g., models that have the highest accuracy without worsening speed).
 |
| Overall flow of our automated neural architecture search approach for Mobile. |
 |
| Our MnasNet network, sampled from the novel factorized hierarchical search space,illustrating the layer diversity throughout the network architecture. |
 |
| ImageNet Accuracy and Inference Latency comparison. MnasNets are our models. |
We are pleased to see that our automated approach can achieve state-of-the-art performance on multiple complex mobile vision tasks. In the future, we plan to incorporate more operations and optimizations into our search space, and apply it to more mobile vision tasks such as semantic segmentation.
Acknowledgements
Special thanks to the co-authors of the paper Bo Chen, Quoc V. Le, Ruoming Pang and Vijay Vasudevan. We’d also like to thank Andrew Howard, Barret Zoph, Dmitry Kalenichenko, Guiheng Zhou, Jeff Dean, Mark Sandler, Megan Kacholia, Sheng Li, Vishy Tirumalashetty, Wen Wang, Xiaoqiang Zheng and Yifeng Lu for their help, and the TensorFlow Lite and Google Brain teams.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
×
❮
❯