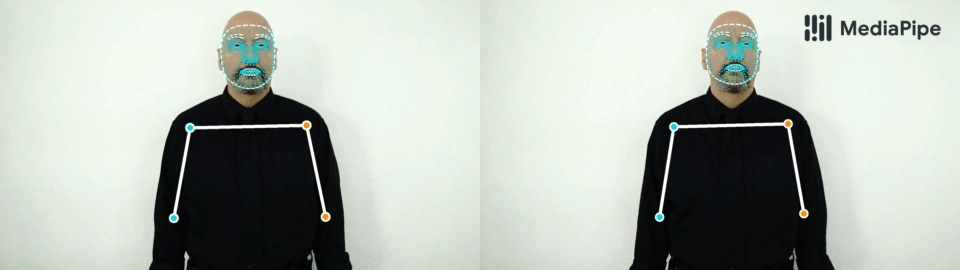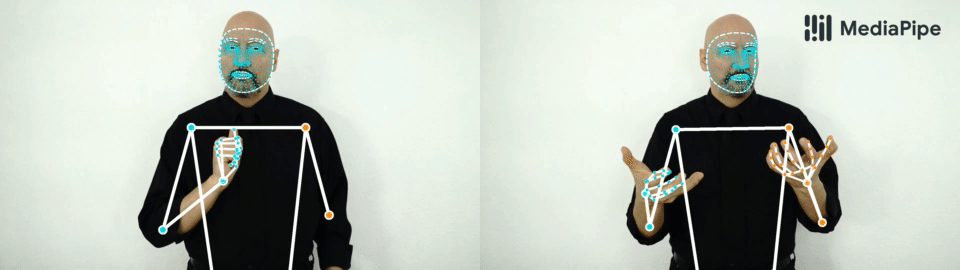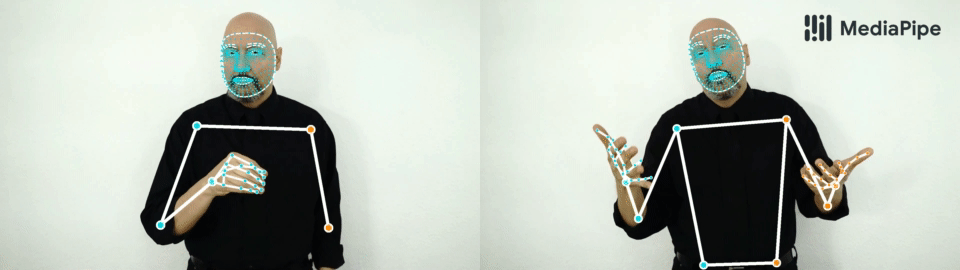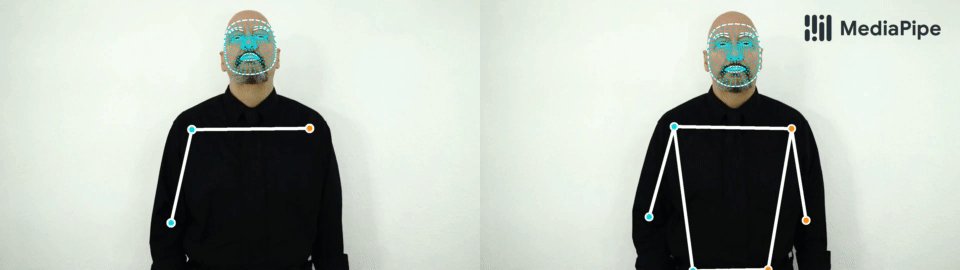MediaPipe Holistic — Simultaneous Face, Hand and Pose Prediction, on Device
December 10, 2020
Posted by Ivan Grishchenko and Valentin Bazarevsky, Research Engineers, Google Research
Quick links
Real-time, simultaneous perception of human pose, face landmarks and hand tracking on mobile devices can enable a variety of impactful applications, such as fitness and sport analysis, gesture control and sign language recognition, augmented reality effects and more. MediaPipe, an open-source framework designed specifically for complex perception pipelines leveraging accelerated inference (e.g., GPU or CPU), already offers fast and accurate, yet separate, solutions for these tasks. Combining them all in real-time into a semantically consistent end-to-end solution is a uniquely difficult problem requiring simultaneous inference of multiple, dependent neural networks.
Today, we are excited to announce MediaPipe Holistic, a solution to this challenge that provides a novel state-of-the-art human pose topology that unlocks novel use cases. MediaPipe Holistic consists of a new pipeline with optimized pose, face and hand components that each run in real-time, with minimum memory transfer between their inference backends, and added support for interchangeability of the three components, depending on the quality/speed tradeoffs. When including all three components, MediaPipe Holistic provides a unified topology for a groundbreaking 540+ keypoints (33 pose, 21 per-hand and 468 facial landmarks) and achieves near real-time performance on mobile devices. MediaPipe Holistic is being released as part of MediaPipe and is available on-device for mobile (Android, iOS) and desktop. We are also introducing MediaPipe’s new ready-to-use APIs for research (Python) and web (JavaScript) to ease access to the technology.
 |
| Top: MediaPipe Holistic results on sport and dance use-cases. Bottom: “Silence” and “Hello” gestures. Note, that our solution consistently identifies a hand as either right (blue color) or left (orange color). |
Pipeline and Quality
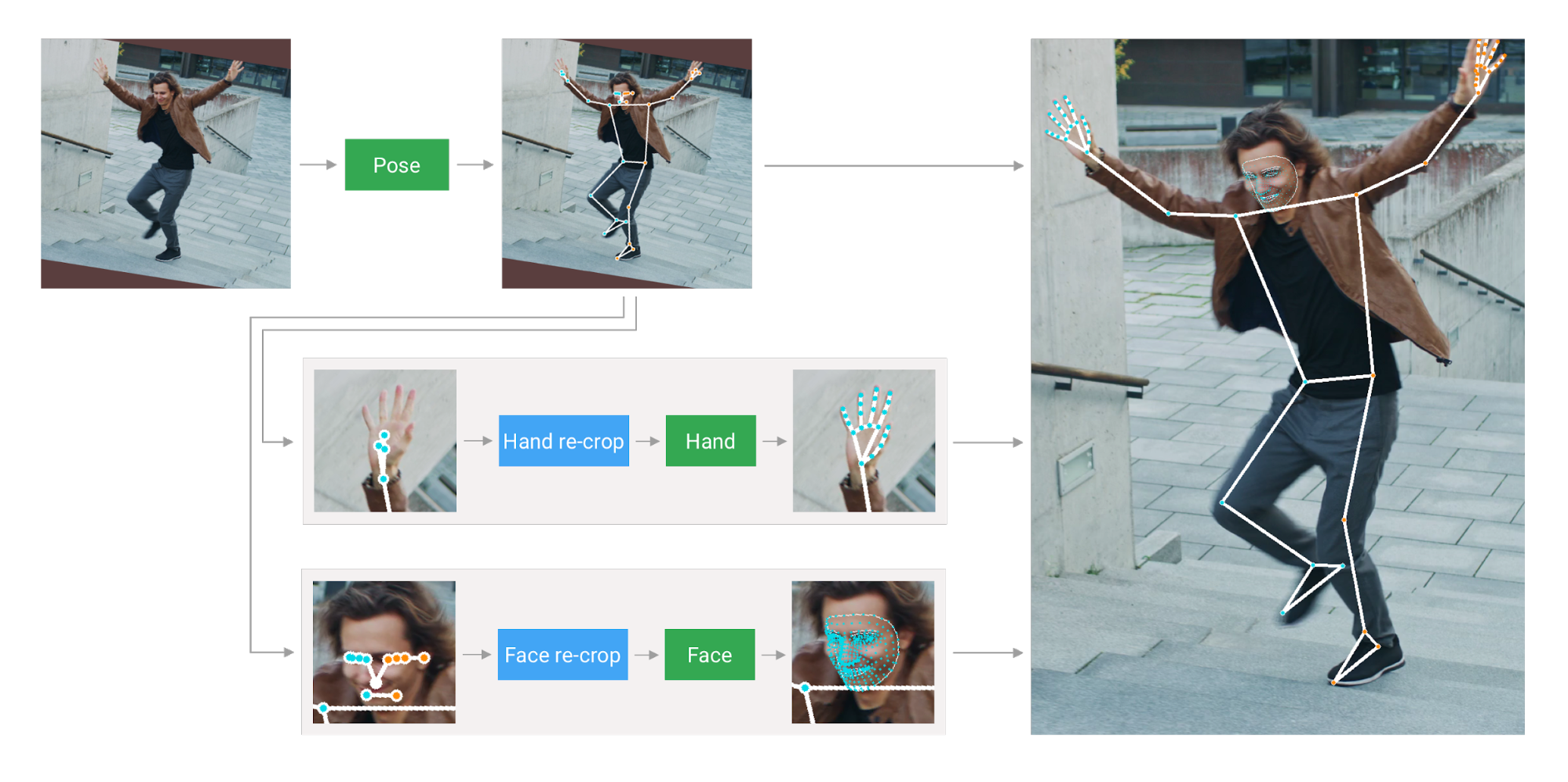
The MediaPipe Holistic pipeline integrates separate models for pose, face and hand components, each of which are optimized for their particular domain. However, because of their different specializations, the input to one component is not well-suited for the others. The pose estimation model, for example, takes a lower, fixed resolution video frame (256x256) as input. But if one were to crop the hand and face regions from that image to pass to their respective models, the image resolution would be too low for accurate articulation. Therefore, we designed MediaPipe Holistic as a multi-stage pipeline, which treats the different regions using a region appropriate image resolution.
First, MediaPipe Holistic estimates the human pose with BlazePose’s pose detector and subsequent keypoint model. Then, using the inferred pose key points, it derives three regions of interest (ROI) crops for each hand (2x) and the face, and employs a re-crop model to improve the ROI (details below). The pipeline then crops the full-resolution input frame to these ROIs and applies task-specific face and hand models to estimate their corresponding keypoints. Finally, all key points are merged with those of the pose model to yield the full 540+ keypoints.
 |
| MediaPipe Holistic pipeline overview. |
To streamline the identification of ROIs, a tracking approach similar to the one used for the standalone face and hand pipelines is utilized. This approach assumes that the object doesn't move significantly between frames, using an estimation from the previous frame as a guide to the object region in the current one. However, during fast movements, the tracker can lose the target, which requires the detector to re-localize it in the image. MediaPipe Holistic uses pose prediction (on every frame) as an additional ROI prior to reduce the response time of the pipeline when reacting to fast movements. This also enables the model to retain semantic consistency across the body and its parts by preventing a mixup between left and right hands or body parts of one person in the frame with another.
In addition, the resolution of the input frame to the pose model is low enough that the resulting ROIs for face and hands are still too inaccurate to guide the re-cropping of those regions, which require a precise input crop to remain lightweight. To close this accuracy gap we use lightweight face and hand re-crop models that play the role of spatial transformers and cost only ~10% of the corresponding model's inference time.
| MEH | FLE | |
| Tracking pipeline (baseline) | 9.8% | 3.1% |
| Pipeline without re-crops | 11.8% | 3.5% |
| Pipeline with re-crops | 9.7% | 3.1% |
| Hand prediction quality.The mean error per hand (MEH) is normalized by the hand size. The face landmarks error (FLE) is normalized by the inter-pupillary distance. |
Performance
MediaPipe Holistic requires coordination between up to 8 models per frame — 1 pose detector, 1 pose landmark model, 3 re-crop models and 3 keypoint models for hands and face. While building this solution, we optimized not only machine learning models, but also pre- and post-processing algorithms (e.g., affine transformations), which take significant time on most devices due to pipeline complexity. In this case, moving all the pre-processing computations to GPU resulted in ~1.5 times overall pipeline speedup depending on the device. As a result, MediaPipe Holistic runs in near real-time performance even on mid-tier devices and in the browser.
| Phone | FPS |
| Google Pixel 2 XL | 18 |
| Samsung S9+ | 20 |
| 15-inch MacBook Pro 2017 | 15 |
| Performance on various mid-tier devices, measured in frames per second (FPS) using TFLite GPU. |
The multi-stage nature of the pipeline provides two more performance benefits. As models are mostly independent, they can be replaced with lighter or heavier versions (or turned off completely) depending on the performance and accuracy requirements. Also, once pose is inferred, one knows precisely whether hands and face are within the frame bounds, allowing the pipeline to skip inference on those body parts.
Applications
MediaPipe Holistic, with its 540+ key points, aims to enable a holistic, simultaneous perception of body language, gesture and facial expressions. Its blended approach enables remote gesture interfaces, as well as full-body AR, sports analytics, and sign language recognition. To demonstrate the quality and performance of the MediaPipe Holistic, we built a simple remote control interface that runs locally in the browser and enables a compelling user interaction, no mouse or keyboard required. The user can manipulate objects on the screen, type on a virtual keyboard while sitting on the sofa, and point to or touch specific face regions (e.g., mute or turn off the camera). Underneath it relies on accurate hand detection with subsequent gesture recognition mapped to a "trackpad" space anchored to the user’s shoulder, enabling remote control from up to 4 meters.
This technique for gesture control can unlock various novel use-cases when other human-computer interaction modalities are not convenient. Try it out in our web demo and prototype your own ideas with it.
 |
| In-browser touchless control demos. Left: Palm picker, touch interface, keyboard. Right: Distant touchless keyboard. Try it out! |
MediaPipe for Research and Web
To accelerate ML research as well as its adoption in the web developer community, MediaPipe now offers ready-to-use, yet customizable ML solutions in Python and in JavaScript. We are starting with those in our previous publications: Face Mesh, Hands and Pose, including MediaPipe Holistic, with many more to come. Try them directly in the web browser: for Python using the notebooks in MediaPipe on Google Colab, and for JavaScript with your own webcam input in MediaPipe on CodePen!
Conclusion
We hope the release of MediaPipe Holistic will inspire the research and development community members to build new unique applications. We anticipate that these pipelines will open up avenues for future research into challenging domains, such as sign-language recognition, touchless control interfaces, or other complex use cases. We are looking forward to seeing what you can build with it!
 |
| Complex and dynamic hand gestures. Videos by Dr. Bill Vicars, used with permission. |
Acknowledgments
Special thanks to all our team members who worked on the tech with us: Fan Zhang, Gregory Karpiak, Kanstantsin Sokal, Juhyun Lee, Hadon Nash, Chuo-Ling Chang, Jiuqiang Tang, Nikolay Chirkov, Camillo Lugaresi, George Sung, Michael Hays, Tyler Mullen, Chris McClanahan, Ekaterina Ignasheva, Marat Dukhan, Artsiom Ablavatski, Yury Kartynnik, Karthik Raveendran, Andrei Vakunov, Andrei Tkachenka, Suril Shah, Buck Bourdon, Ming Guang Yong, Esha Uboweja, Siarhei Kazakou, Andrei Kulik, Matsvei Zhdanovich, and Matthias Grundmann.
Quick links
Other posts of interest
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence