Measuring Compositional Generalization
March 6, 2020
Posted by Marc van Zee, Software Engineer, Google Research
Quick links
People are capable of learning the meaning of a new word and then applying it to other language contexts. As Lake and Baroni put it, “Once a person learns the meaning of a new verb ‘dax’, he or she can immediately understand the meaning of ‘dax twice’ and ‘sing and dax’.” Similarly, one can learn a new object shape and then recognize it with different compositions of previously learned colors or materials (e.g., in the CLEVR dataset). This is because people exhibit the capacity to understand and produce a potentially infinite number of novel combinations of known components, or as Chomsky said, to make “infinite use of finite means.” In the context of a machine learning model learning from a set of training examples, this skill is called compositional generalization.
A common approach for measuring compositional generalization in machine learning (ML) systems is to split the training and testing data based on properties that intuitively correlate with compositional structure. For instance, one approach is to split the data based on sequence length — the training set consists of short examples, while the test set consists of longer examples. Another approach uses sequence patterns, meaning the split is based on randomly assigning clusters of examples sharing the same pattern to either train or test sets. For instance, the questions "Who directed Movie1" and "Who directed Movie2" both fall into the pattern "Who directed <MOVIE>" so they would be grouped together. Yet another method uses held out primitives — some linguistic primitives are shown very rarely during training (e.g., the verb “jump”), but are very prominent in testing. While each of these experiments are useful, it is not immediately clear which experiment is a "better" measure for compositionality. Is it possible to systematically design an “optimal” compositional generalization experiment?
In “Measuring Compositional Generalization: A Comprehensive Method on Realistic Data”, we attempt to address this question by introducing the largest and most comprehensive benchmark for compositional generalization using realistic natural language understanding tasks, specifically, semantic parsing and question answering. In this work, we propose a metric — compound divergence — that allows one to quantitatively assess how much a train-test split measures the compositional generalization ability of an ML system. We analyze the compositional generalization ability of three sequence to sequence ML architectures, and find that they fail to generalize compositionally. We also are releasing the Compositional Freebase Questions dataset used in the work as a resource for researchers wishing to improve upon these results.
Measuring Compositionality
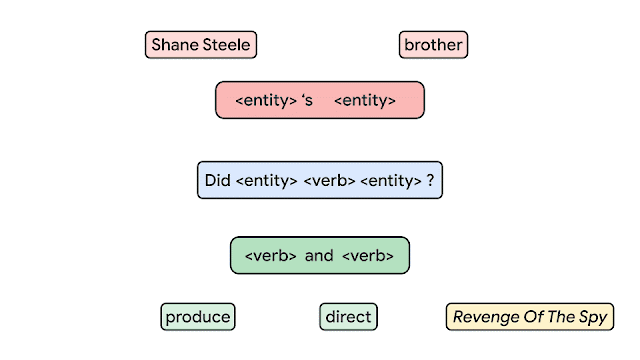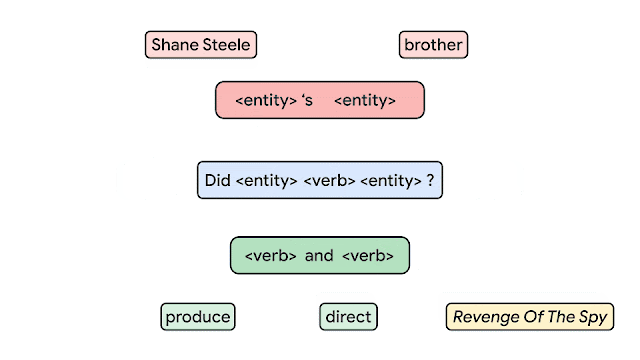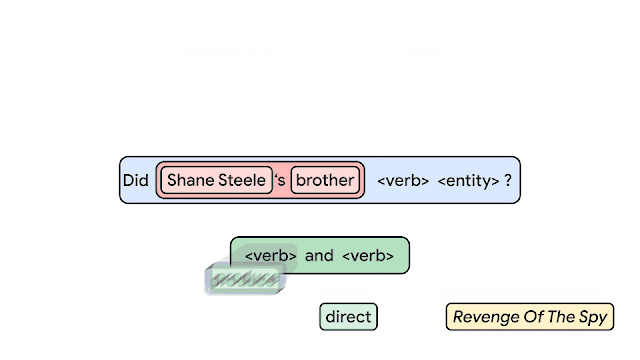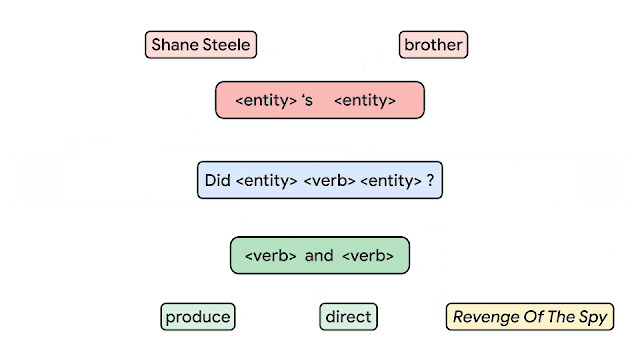
In order to measure the compositional generalization ability of a system, we start with the assumption that we understand the underlying principles of how examples are generated. For instance, we begin with the grammar rules to which we must adhere when generating questions and answers. We then draw a distinction between atoms and compounds. Atoms are the building blocks that are used to generate examples and compounds are concrete (potentially partial) compositions of these atoms. For example, in the figure below, every box is an atom (e.g., Shane Steel, brother, <entity>'s <entity>, produce, etc.), which fits together to form compounds, such as produce and <verb>, Shane Steel’s brother, Did Shane Steel’s brother produce and direct Revenge of the Spy?, etc.
 |
| Building compositional sentences (compounds) from building blocks (atoms). |

The Compositional Freebase Questions dataset
In order to conduct an accurate compositionality experiment, we created the Compositional Freebase Questions (CFQ) dataset, a simple, yet realistic, large dataset of natural language questions and answers generated from the public Freebase knowledge base. The CFQ can be used for text-in / text-out tasks, as well as semantic parsing. In our experiments, we focus on semantic parsing, where the input is a natural language question and the output is a query, which when executed against Freebase, produces the correct outcome. CFQ contains around 240k examples and almost 35k query patterns, making it significantly larger and more complex than comparable datasets — about 4 times that of WikiSQL with about 17x more query patterns than Complex Web Questions. Special care has been taken to ensure that the questions and answers are natural. We also quantify the complexity of the syntax in each example using the “complexity level” metric (L), which corresponds roughly to the depth of the parse tree, examples of which are shown below.

For a given train-test split, if the compound distributions of the train and test sets are very similar, then their compound divergence would be close to 0, indicating that they are not difficult tests for compositional generalization. A compound divergence close to 1 means that the train-test sets have many different compounds, which makes it a good test for compositional generalization. Compound divergence thus captures the notion of "different compound distribution", as desired.
We algorithmically generate train-test splits using the CFQ dataset that have a compound divergence ranging from 0 to 0.7 (the maximum that we were able to achieve). We fix the atom divergence to be very small. Then, for each split we measure the performance of three standard ML architectures — LSTM+attention, Transformer, and Universal Transformer. The results are shown in the graph below.
 |
| Compound divergence vs accuracy for three ML architectures. There is a surprisingly strong negative correlation between compound divergence and accuracy. |
Potentially promising directions for future work might be to apply unsupervised pre-training on input language or output queries, or to use more diverse or more targeted learning architectures, such as syntactic attention. It would also be interesting to apply this approach to other domains such as visual reasoning, e.g. based on CLEVR, or to extend our approach to broader subsets of language understanding, including the use of ambiguous constructs, negations, quantification, comparatives, additional languages, and other vertical domains. We hope that this work will inspire others to use this benchmark to advance the compositional generalization capabilities of learning systems.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
×
❮
❯



