Mastering Atari with Discrete World Models
February 18, 2021
Posted by Danijar Hafner, Student Researcher, Google Research
Quick links
Deep reinforcement learning (RL) enables artificial agents to improve their decisions over time. Traditional model-free approaches learn which of the actions are successful in different situations by interacting with the environment through a large amount of trial and error. In contrast, recent advances in deep RL have enabled model-based approaches to learn accurate world models from image inputs and use them for planning. World models can learn from fewer interactions, facilitate generalization from offline data, enable forward-looking exploration, and allow reusing knowledge across multiple tasks.
Despite their intriguing benefits, existing world models (such as SimPLe) have not been accurate enough to compete with the top model-free approaches on the most competitive reinforcement learning benchmarks — to date, the well-established Atari benchmark requires model-free algorithms, such as DQN, IQN, and Rainbow, to reach human-level performance. As a result, many researchers have focused instead on developing task-specific planning methods, such as VPN and MuZero, which learn by predicting sums of expected task rewards. However, these methods are specific to individual tasks and it is unclear how well they would generalize to new tasks or learn from unsupervised datasets. Similar to the recent breakthrough of unsupervised representation learning in computer vision [1, 2], world models aim to learn patterns in the environment that are more general than any particular task to later solve tasks more efficiently.
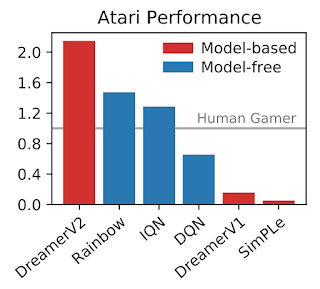
Today, in collaboration with DeepMind and the University of Toronto, we introduce DreamerV2, the first RL agent based on a world model to achieve human-level performance on the Atari benchmark. It constitutes the second generation of the Dreamer agent that learns behaviors purely within the latent space of a world model trained from pixels. DreamerV2 relies exclusively on general information from the images and accurately predicts future task rewards even when its representations were not influenced by those rewards. Using a single GPU, DreamerV2 outperforms top model-free algorithms with the same compute and sample budget.
 |
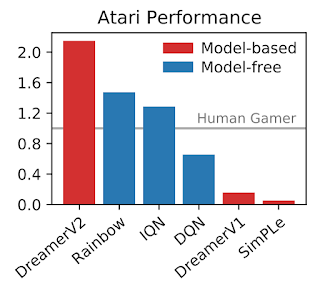
| Gamer normalized median score across the 55 Atari games after 200 million steps. DreamerV2 substantially outperforms previous world models. Moreover, it exceeds top model-free agents within the same compute and sample budget. [Update – 2021 May 04: An earlier version of this figure showed weaker performance by DreamerV2 than was actually achieved.] |
 |
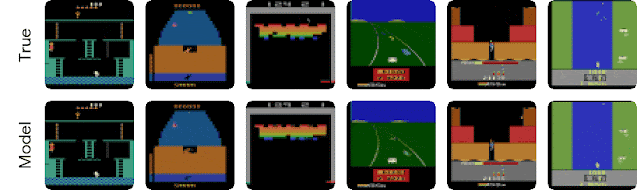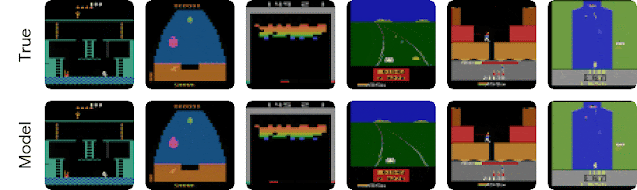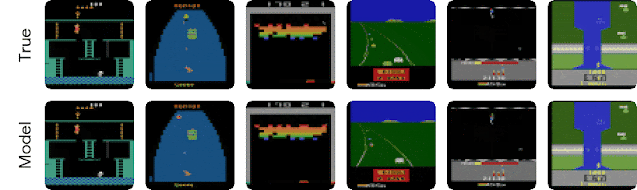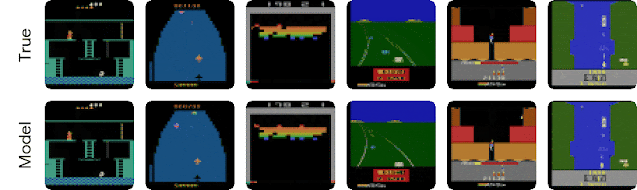
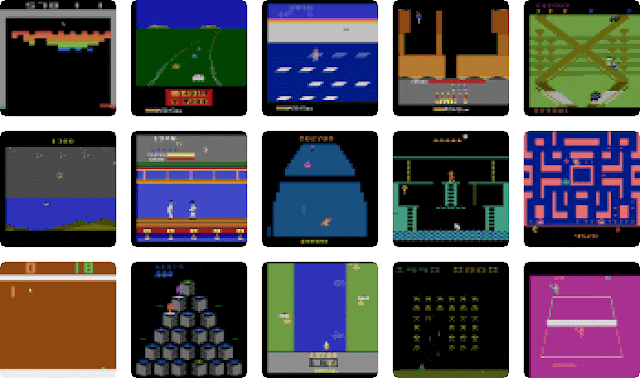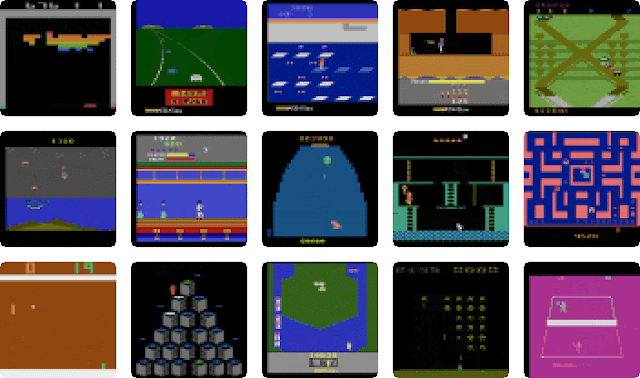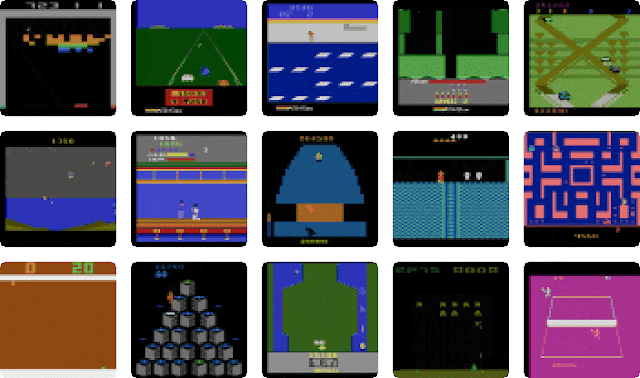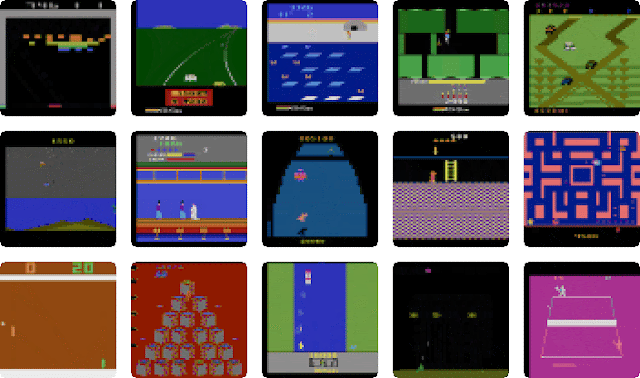
| Behaviors learned by DreamerV2 for some of the 55 Atari games. These videos show images from the environment. Video predictions are shown below in the blog post. |
An Abstract Model of the World
Just like its predecessor, DreamerV2 learns a world model and uses it to train actor-critic behaviors purely from predicted trajectories. The world model automatically learns to compute compact representations of its images that discover useful concepts, such as object positions, and learns how these concepts change in response to different actions. This lets the agent generate abstractions of its images that ignore irrelevant details and enables massively parallel predictions on a single GPU. During 200 million environment steps, DreamerV2 predicts 468 billion compact states for learning its behavior.
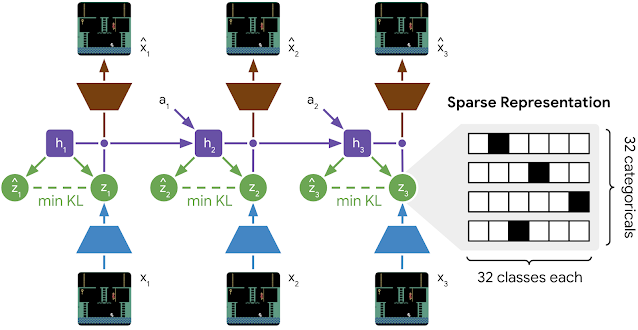
DreamerV2 builds upon the Recurrent State-Space Model (RSSM) that we introduced for PlaNet and was also used for DreamerV1. During training, an encoder turns each image into a stochastic representation that is incorporated into the recurrent state of the world model. Because the representations are stochastic, they do not have access to perfect information about the images and instead extract only what is necessary to make predictions, making the agent robust to unseen images. From each state, a decoder reconstructs the corresponding image to learn general representations. Moreover, a small reward network is trained to rank outcomes during planning. To enable planning without generating images, a predictor learns to guess the stochastic representations without access to the images from which they were computed.
 |
| Learning process of the world model used by DreamerV2. The world model maintains recurrent states (h1–h3) that receive actions (a1–a2) and incorporate information about the images (x1–x3) via stochastic representations (z1–z3). A predictor guesses the representations as (ẑ1–ẑ3) without access to the images from which they were generated. |
Importantly, DreamerV2 introduces two new techniques to RSSM that lead to a substantially more accurate world model for learning successful policies. The first technique is to represent each image with multiple categorical variables instead of the Gaussian variables used by PlaNet, DreamerV1, and many more world models in the literature [1, 2, 3, 4, 5]. This leads the world model to reason about the world in terms of discrete concepts and enables more accurate predictions of future representations.
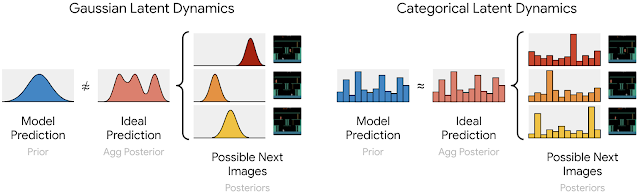
The encoder turns each image into 32 distributions over 32 classes each, the meanings of which are determined automatically as the world model learns. The one-hot vectors sampled from these distributions are concatenated to a sparse representation that is passed on to the recurrent state. To backpropagate through the samples, we use straight-through gradients that are easy to implement using automatic differentiation. Representing images with categorical variables allows the predictor to accurately learn the distribution over the one-hot vectors of the possible next images. In contrast, earlier world models that use Gaussian predictors cannot accurately match the distribution over multiple Gaussian representations for the possible next images.
 |
| Multiple categoricals that represent possible next images can be accurately predicted by a categorical predictor, whereas a Gaussian predictor is not flexible enough to accurately predict multiple possible Gaussian representations. |
The second new technique of DreamerV2 is KL balancing. Many previous world models use the ELBO objective that encourages accurate reconstructions while keeping the stochastic representations (posteriors) close to their predictions (priors) to regularize the amount of information extracted from each image and facilitate generalization. Because the objective is optimized end-to-end, the stochastic representations and their predictions can be made more similar by bringing either of the two towards the other. However, bringing the representations towards their predictions can be problematic when the predictor is not yet accurate. KL balancing lets the predictions move faster toward the representations than vice versa. This results in more accurate predictions, a key to successful planning.
 |
| Long-term video predictions of the world model for holdout sequences. Each model receives 5 frames as input (not shown) and then predicts 45 steps forward given only actions. The video predictions are only used to gain insights into the quality of the world model. During planning, only compact representations are predicted, not images. |
Measuring Atari Performance
DreamerV2 is the first world model that enables learning successful behaviors with human-level performance on the well-established and competitive Atari benchmark. We select the 55 games that many previous studies have in common and recommend this set of games for future work. Following the standard evaluation protocol, the agents are allowed 200M environment interactions using an action repeat of 4 and sticky actions (25% chance that an action is ignored and the previous action is repeated instead). We compare to the top model-free agents IQN and Rainbow, as well as to the well-known C51 and DQN agents implemented in the Dopamine framework.
Different standards exist for aggregating the scores across the 55 games. Ideally, a new algorithm would perform better under all conditions. For all four aggregation methods, DreamerV2 indeed outperforms all compared model-free algorithms while using the same computational budget.
 |
| DreamerV2 outperforms the top model-free agents according to four methods for aggregating scores across the 55 Atari games. We introduce and recommend the Clipped Record Mean (right-most plot) as an informative and robust performance metric. [Update – 2021 May 04: An earlier version of this figure showed weaker performance by DreamerV2 than was actually achieved.] |
The first three aggregation methods were previously proposed in the literature. We identify important drawbacks in each and recommend a new aggregation method, the clipped record mean to overcome their drawbacks.
- Gamer Median. Most commonly, scores for each game are normalized by the performance of a human gamer that was assessed for the DQN paper and the median of the normalized scores of all games is reported. Unfortunately, the median ignores the scores of many simpler and harder games.
- Gamer Mean. The mean takes the scores for all games into account but is mainly influenced by a small number of games where the human gamer performed poorly. This makes it easy for an algorithm to achieve large normalized scores on some games (e.g., James Bond, Video Pinball) that then dominate the mean.
- Record Mean. Prior work recommends normalization based on the human world record instead, but such a metric is still overly influenced by a small number of games where it is easy for the artificial agents to outscore the human record.
- Clipped Record Mean. We introduce a new metric that normalizes scores by the world record and clips them to not exceed the record. This yields an informative and robust metric that takes the performance on all games into account to an approximately equal amount.
While many current algorithms exceed the human gamer baseline, they are still quite far behind the human world record. As shown in the right-most plot above, DreamerV2 leads by achieving 25% of the human record on average across games. Clipping the scores at the record line lets us focus our efforts on developing methods that come closer to the human world record on all of the games rather than exceeding it on just a few games.
What Matters and What Doesn't
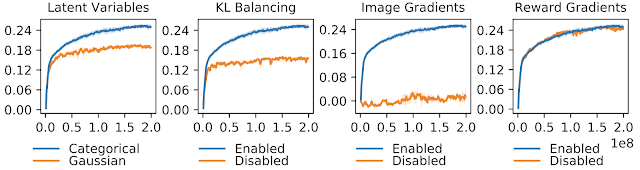
To gain insights into the important components of DreamerV2, we conduct an extensive ablation study. Importantly, we find that categorical representations offer a clear advantage over Gaussian representations despite the fact that Gaussians have been used extensively in prior works. KL balancing provides an even more substantial advantage over the KL regularizer used by most generative models.
By preventing the image reconstruction or reward prediction gradients from shaping the model states, we study their importance for learning successful representations. We find that DreamerV2 relies completely on universal information from the high-dimensional input images and its representations enable accurate reward predictions even when they were not trained using information about the reward. This mirrors the success of unsupervised representation learning in the computer vision community.
 |
| Atari performance for various ablations of DreamerV2 (Clipped Record Mean). Categorical representations, KL balancing, and learning about the images are crucial for the success of DreamerV2. Using reward information, that is specific to narrow tasks, offers no additional benefits for learning the world model. |
Conclusion
We show how to learn a powerful world model to achieve human-level performance on the competitive Atari benchmark and outperform the top model-free agents. This result demonstrates that world models are a powerful approach for achieving high performance on reinforcement learning problems and are ready to use for practitioners and researchers. We see this as an indication that the success of unsupervised representation learning in computer vision [1, 2] is now starting to be realized in reinforcement learning in the form of world models. An unofficial implementation of DreamerV2 is available on Github and provides a productive starting point for future research projects. We see world models that leverage large offline datasets, long-term memory, hierarchical planning, and directed exploration as exciting avenues for future research.
Acknowledgements
This project is a collaboration with Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. We further thank everybody on the Brain Team and beyond who commented on our paper draft and provided feedback at any point throughout the project.
Quick links