Massively Scaling Reinforcement Learning with SEED RL
March 23, 2020
Posted by Lasse Espeholt, Research Engineer, Google Research, Amsterdam
Quick links
Reinforcement learning (RL) has seen impressive advances over the last few years as demonstrated by the recent success in solving games such as Go and Dota 2. Models, or agents, learn by exploring an environment, such as a game, while optimizing for specified goals. However, current RL techniques require increasingly large amounts of training to successfully learn even simple games, which makes iterating research and product ideas computationally expensive and time consuming.
In “SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference”, we present an RL agent that scales to thousands of machines, which enables training at millions of frames per second, and significantly improves computational efficiency. This is achieved with a novel architecture that takes advantage of accelerators (GPUs or TPUs) at scale by centralizing model inference and introducing a fast communication layer. We demonstrate the performance of SEED RL on popular RL benchmarks, such as Google Research Football, Arcade Learning Environment and DeepMind Lab, and show that by using larger models, data efficiency can be increased. The code has been open sourced on Github together with examples for running on Google Cloud with GPUs.
Current Distributed Architectures
The previous generation of distributed reinforcement learning agents, such as IMPALA, made use of accelerators specialized for numerical calculations, taking advantage of the speed and efficiency from which (un)supervised learning has benefited for years. The architecture of an RL agent is usually separated into actors and learners. The actors typically run on CPUs and iterate between taking steps in the environment and running inference on the model to predict the next action. Frequently the actor will update the parameters of the inference model, and after collecting a sufficient amount of observations, will send a trajectory of observations and actions to the learner, which then optimizes the model. In this architecture, the learner trains the model on GPUs using input from distributed inference on hundreds of machines.
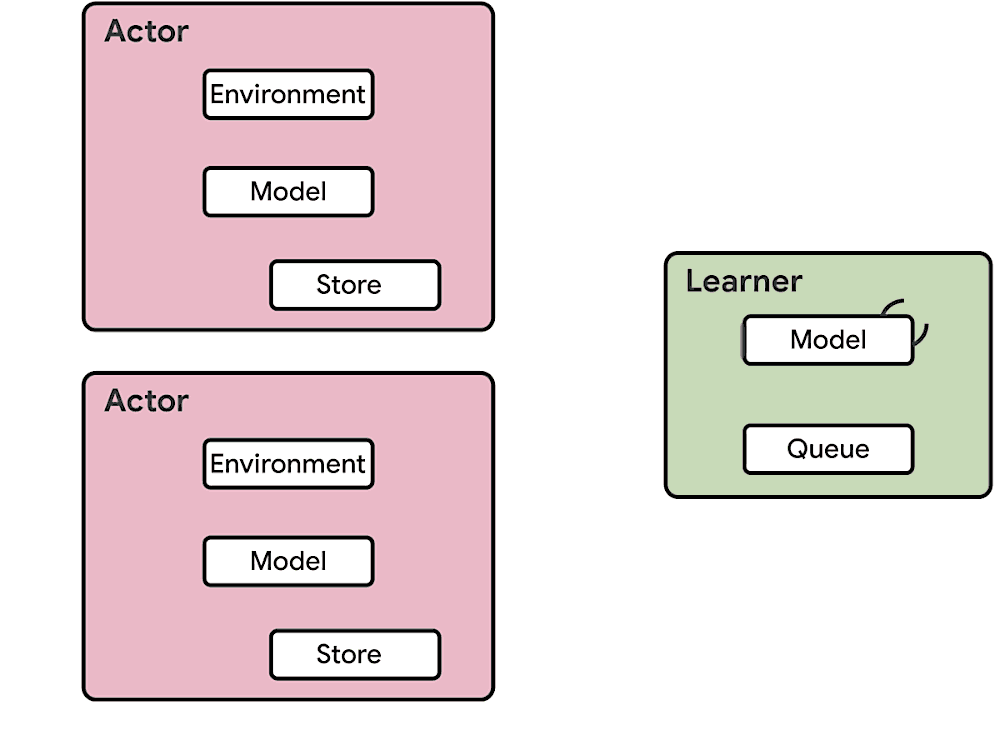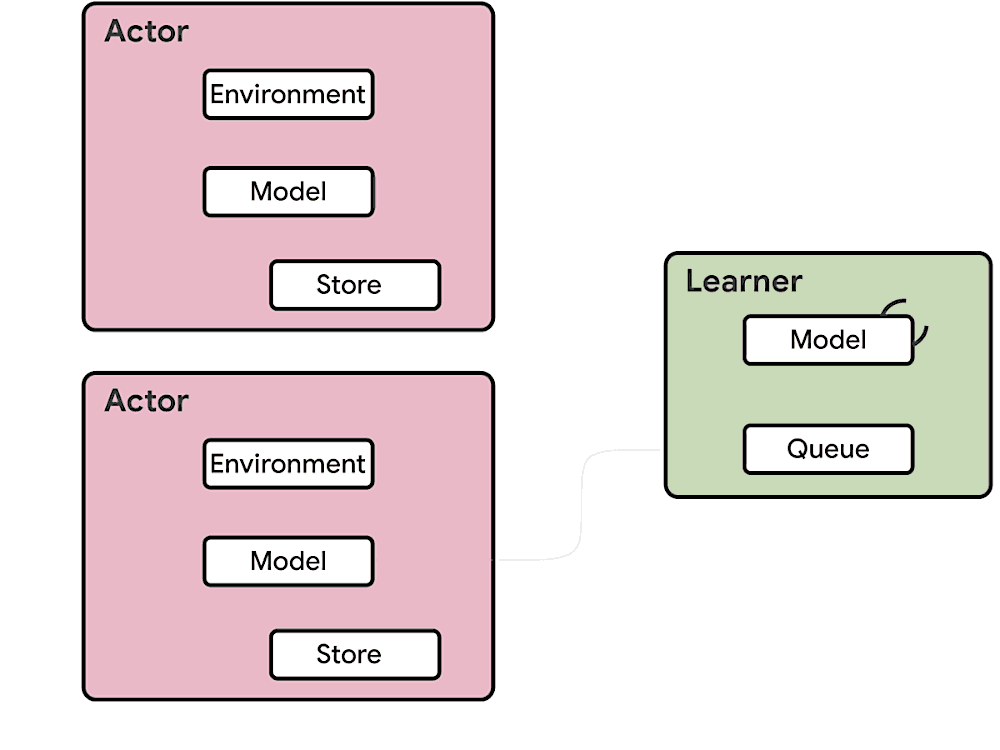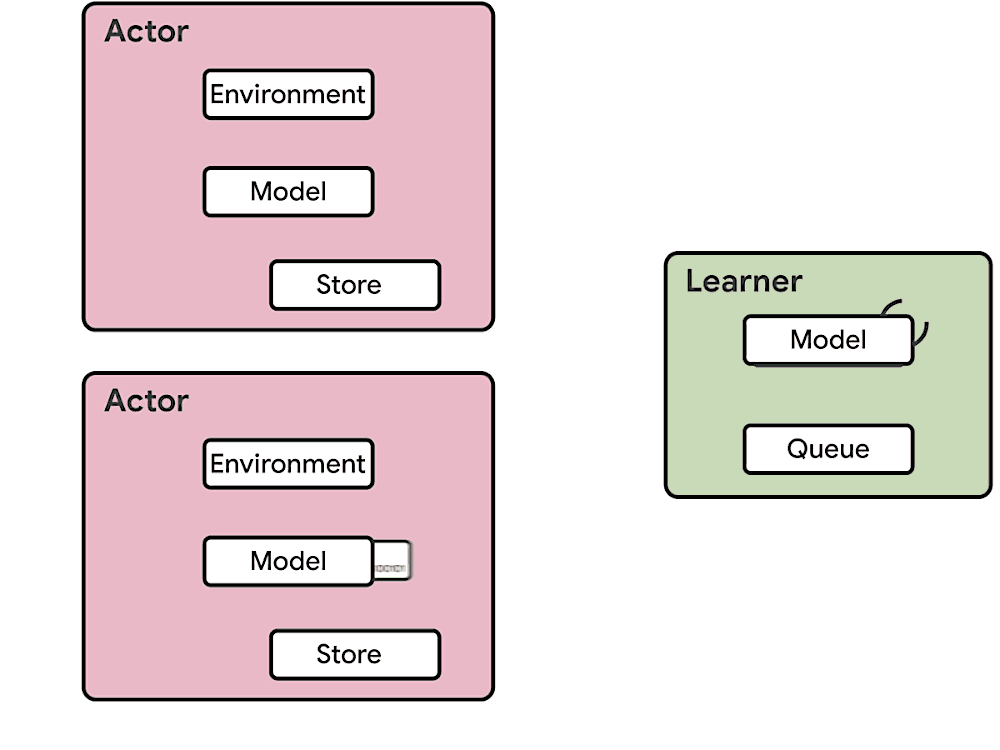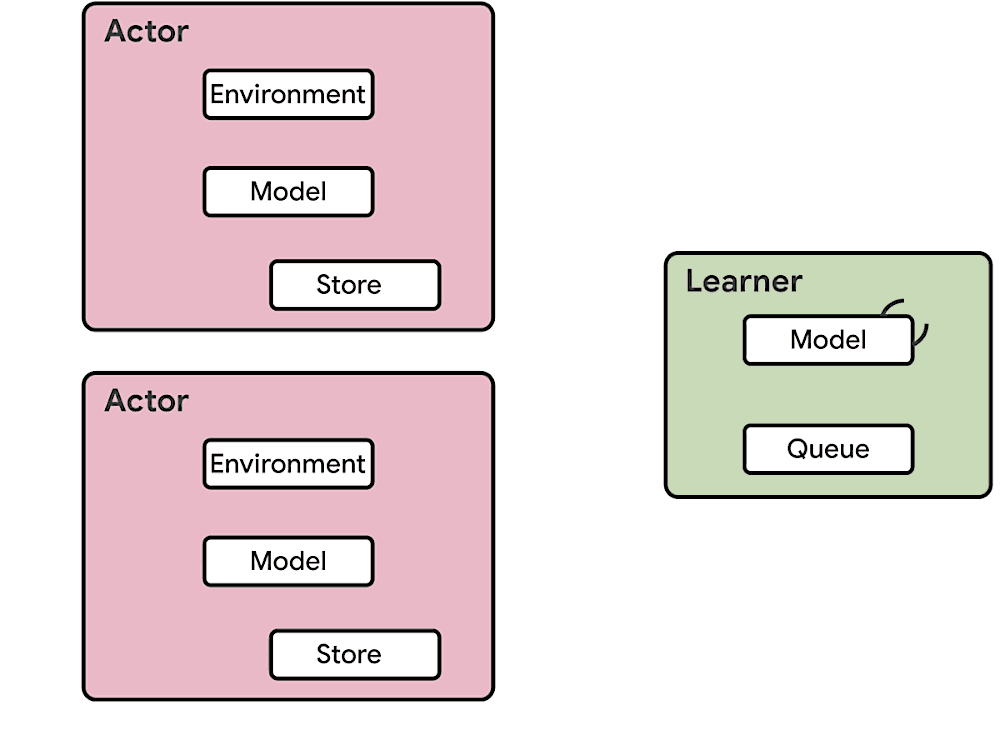 |
| Example architecture for an earlier generation RL agent, IMPALA. Inference is done on the actors, usually using inefficient CPUs. Updated model parameters are frequently sent from the learner to the actors increasing bandwidth requirements. |
- Using CPUs for neural network inference is much less efficient and slower than using accelerators and becomes problematic as models become larger and more computationally expensive.
- The bandwidth required for sending parameters and intermediate model states between the actors and learner can be a bottleneck.
- Handling two completely different tasks on one machine (i.e., environment rendering and inference) is unlikely to utilize machine resources optimally.
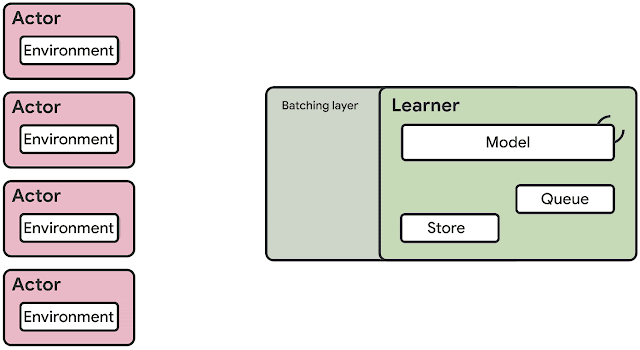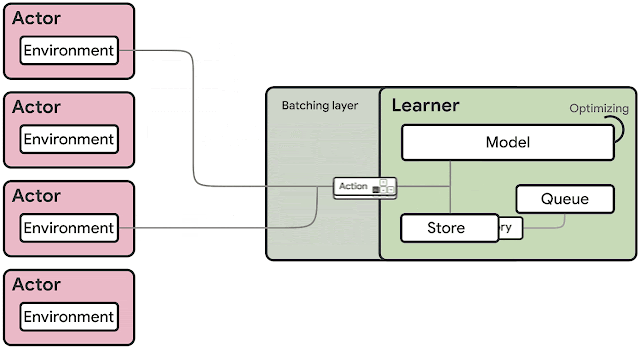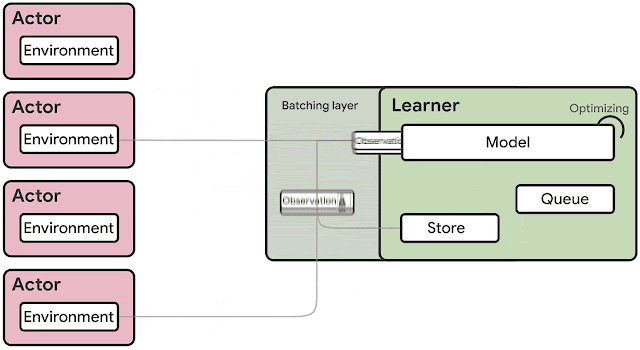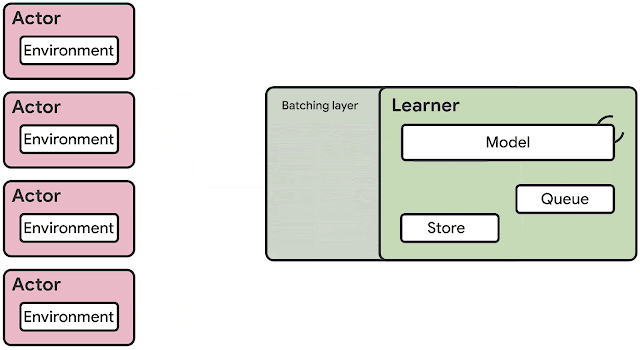
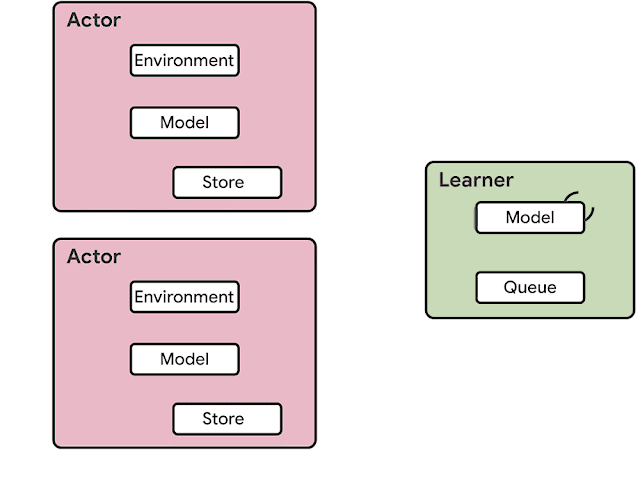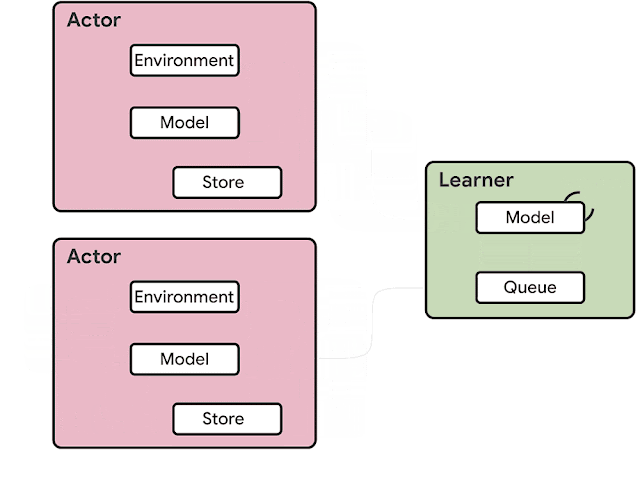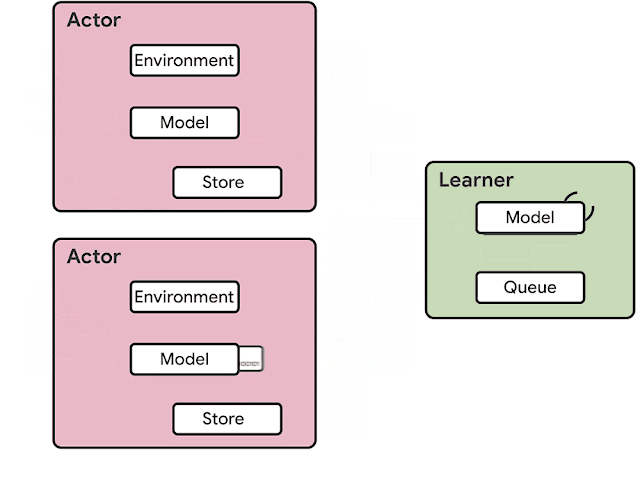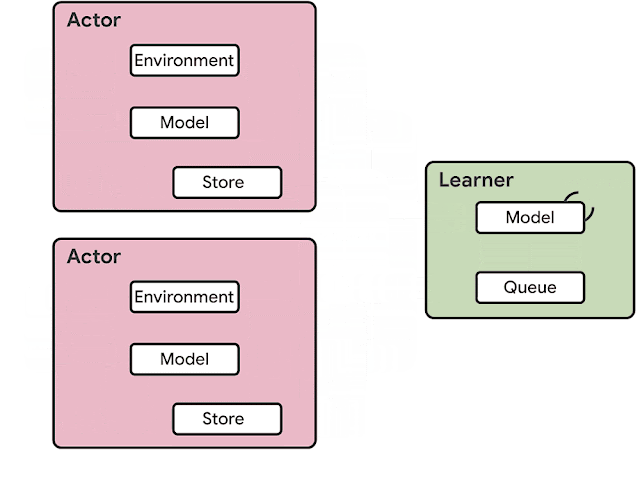
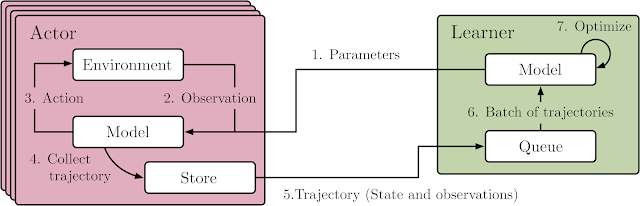
The SEED RL architecture is designed to solve these drawbacks. With this approach, neural network inference is done centrally by the learner on specialized hardware (GPUs or TPUs), enabling accelerated inference and avoiding the data transfer bottleneck by ensuring that the model parameters and state are kept local. While observations are sent to the learner at every environment step, latency is kept low due to a very efficient network library based on the gRPC framework with asynchronous streaming RPCs. This makes it possible to achieve up to a million queries per second on a single machine. The learner can be scaled to thousands of cores (e.g., up to 2048 on Cloud TPUs) and the number of actors can be scaled to thousands of machines to fully utilize the learner, making it possible to train at millions of frames per second. SEED RL is based on the TensorFlow 2 API and, in our experiments, was accelerated by TPUs.
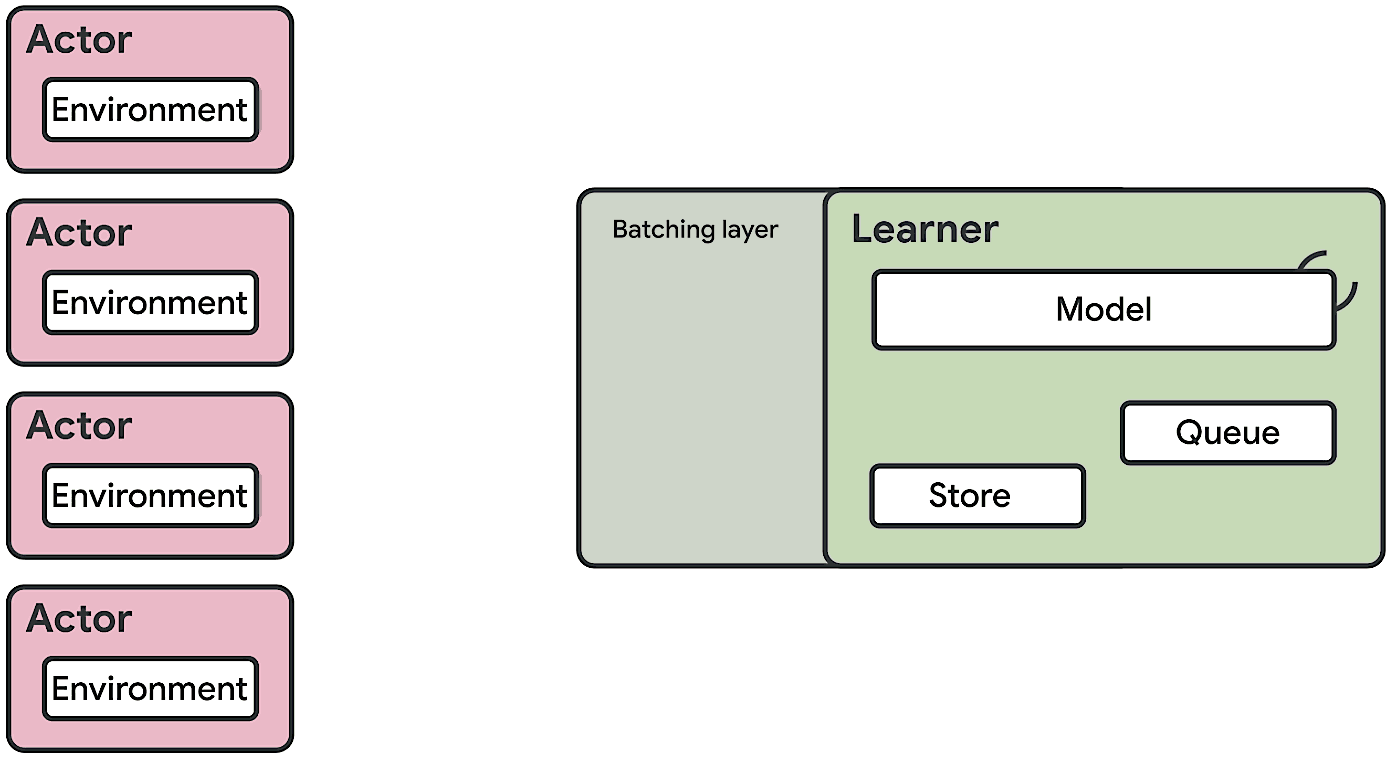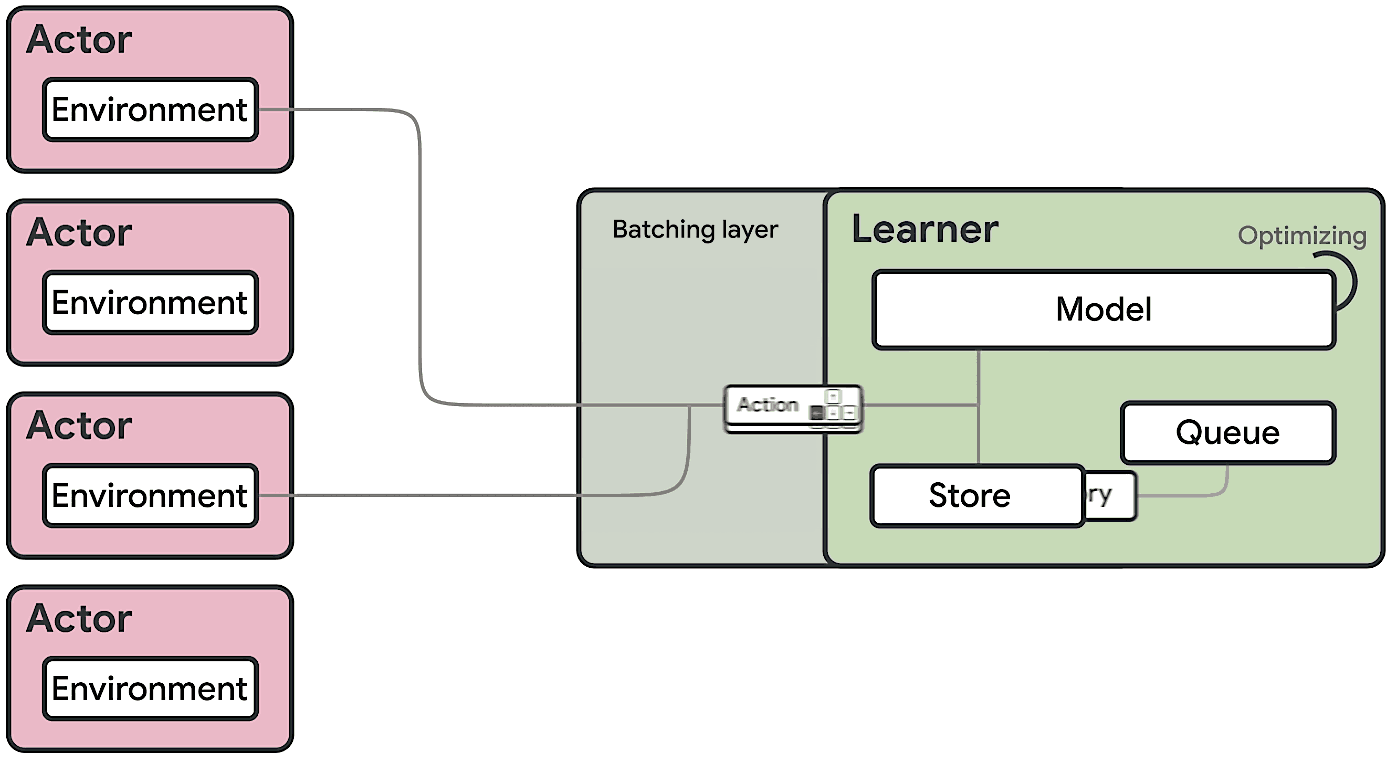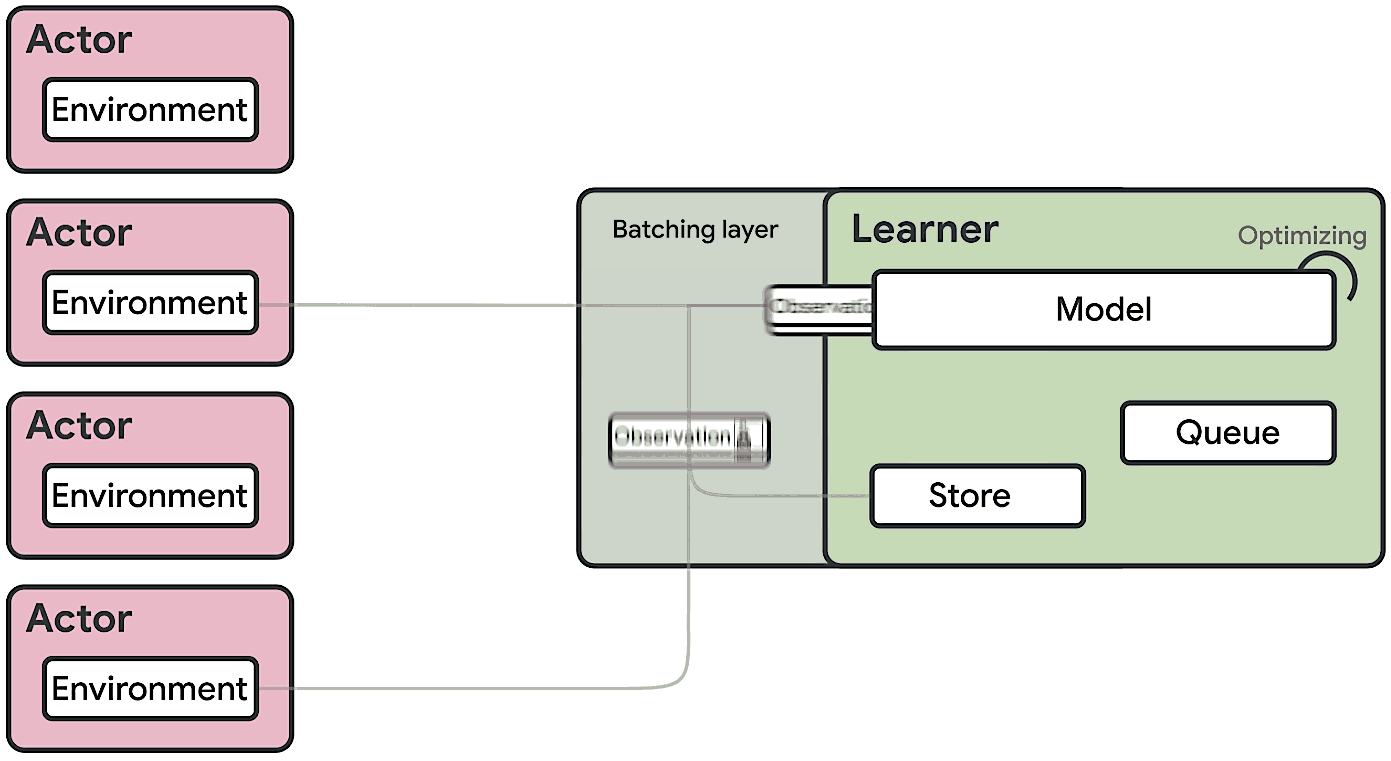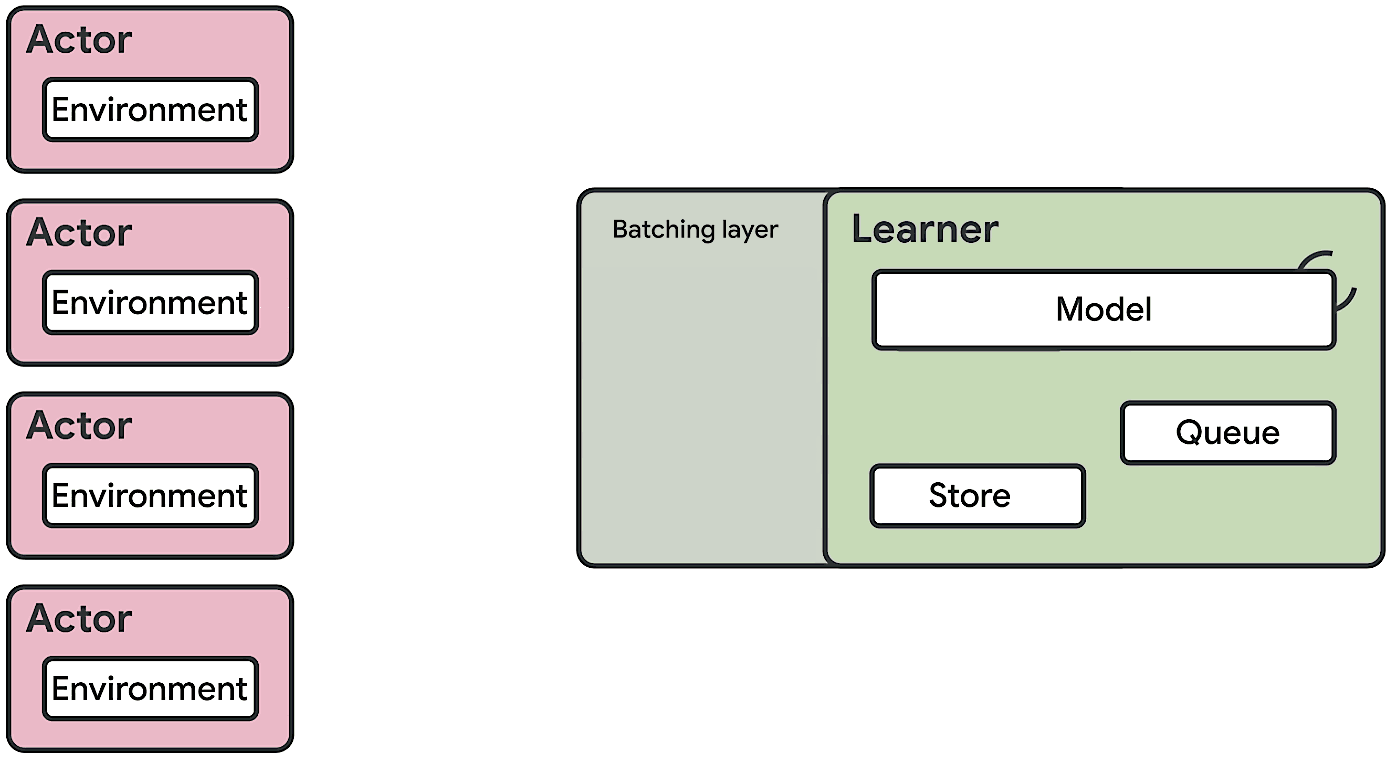 |
| Overview of the architecture of SEED RL. In contrast to the IMPALA architecture, the actors only take actions in environments. Inference is executed centrally by the learner on accelerators using batches of data from multiple actors. |
The second algorithm is R2D2, a Q-learning method that selects an action based on the predicted future value of that action using recurrent distributed replay. This approach allows the Q-learning algorithm to be run at scale, while still allowing the use of recurrent neural networks that can predict future values based on the information of all past frames in an episode.
Experiments
SEED RL is benchmarked on the commonly used Arcade Learning Environment, DeepMind Lab environments, and on the recently released Google Research Football environment.
 |
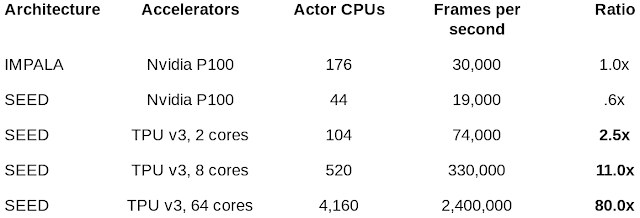
| Frames per second comparing IMPALA and various configurations of SEED RL on DeepMind Lab. SEED RL achieves 2.4M frames per second using 4,160 CPUs. Assuming the same speed, IMPALA would need 14,000 CPUs. |
 |
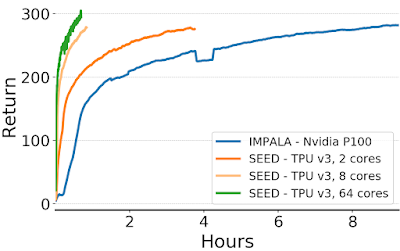
| Episode return (i.e., the sum of rewards) over time on the DeepMind Lab game “explore_goal_locations_small” using IMPALA and SEED RL. With SEED RL, the time to train is significantly reduced. |
 |
| The score of different architectures on the Google Research Football “Hard” task. We show that by using an input resolution and a larger model, the score is improved, and with more training, the model can significantly outperform the builtin AI. |
Acknowledgements
This project was done in collaboration with Raphaël Marinier, Piotr Stanczyk, Ke Wang, Marcin Andrychowicz and Marcin Michalski. We would also like to thank Tom Small for the visualizations.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
×
❮
❯