Mapping Urban Trees Across North America with the Auto Arborist Dataset
June 22, 2022
Posted by Sara Beery, Student Researcher, and Jonathan Huang, Research Scientist, Google Research, Perception Team
Quick links
Over four billion people live in cities around the globe, and while most people interact daily with others — at the grocery store, on public transit, at work — they may take for granted their frequent interactions with the diverse plants and animals that comprise fragile urban ecosystems. Trees in cities, called urban forests, provide critical benefits for public health and wellbeing and will prove integral to urban climate adaptation. They filter air and water, capture stormwater runoff, sequester atmospheric carbon dioxide, and limit erosion and drought. Shade from urban trees reduces energy-expensive cooling costs and mitigates urban heat islands. In the US alone, urban forests cover 127M acres and produce ecosystem services valued at $18 billion. But as the climate changes these ecosystems are increasingly under threat.
 |
| Census data is typically not comprehensive, covering a subset of public trees and not including those in parks. |
Urban forest monitoring — measuring the size, health, and species distribution of trees in cities over time — allows researchers and policymakers to (1) quantify ecosystem services, including air quality improvement, carbon sequestration, and benefits to public health; (2) track damage from extreme weather events; and (3) target planting to improve robustness to climate change, disease and infestation.
However, many cities lack even basic data about the location and species of their trees. Collecting such data via a tree census is costly (a recent Los Angeles census cost $2 million and took 18 months) and thus is typically conducted only by cities with substantial resources. Further, lack of access to urban greenery is a key aspect of urban social inequality, including socioeconomic and racial inequality. Urban forest monitoring enables the quantification of this inequality and the pursuit of its improvement, a key aspect of the environmental justice movement. But machine learning could dramatically lower tree census costs using a combination of street-level and aerial imagery. Such an automated system could democratize access to urban forest monitoring, especially for under-resourced cities that are already disproportionately affected by climate change. While there have been prior efforts to develop automated urban tree species recognition from aerial or street-level imagery, a major limitation has been a lack of large-scale labeled datasets.
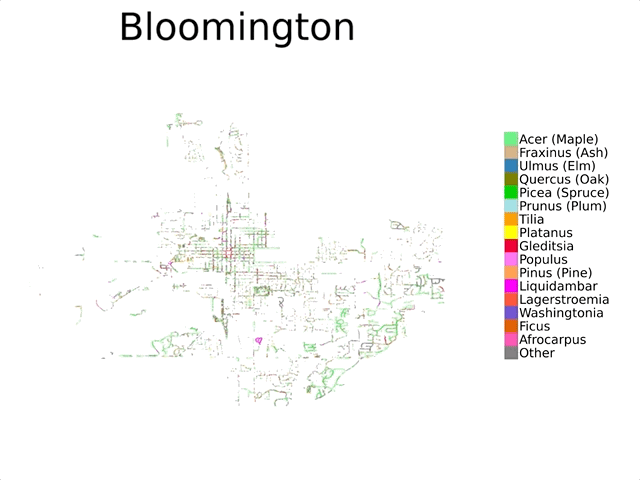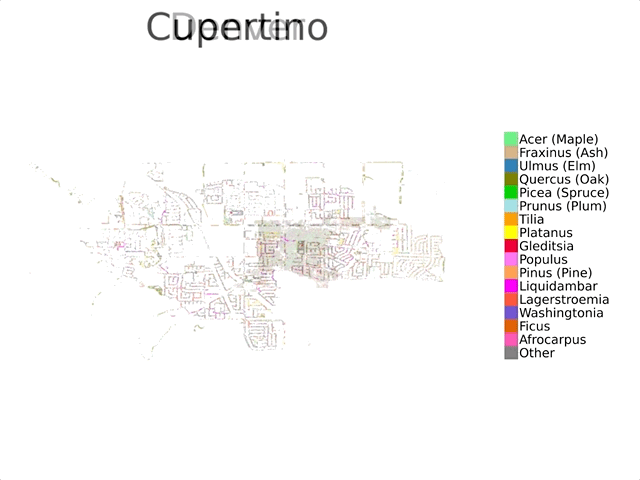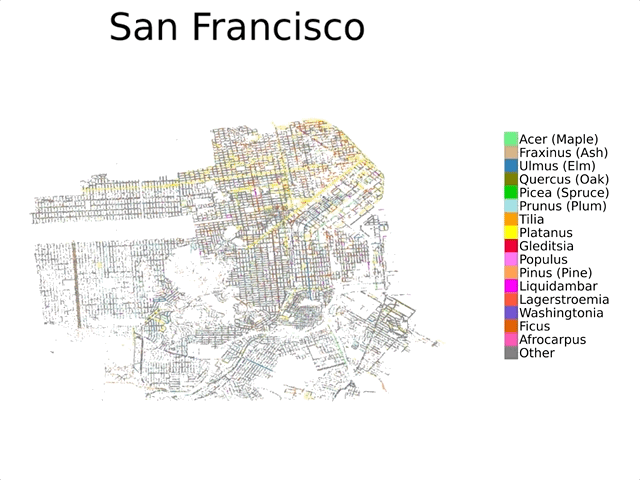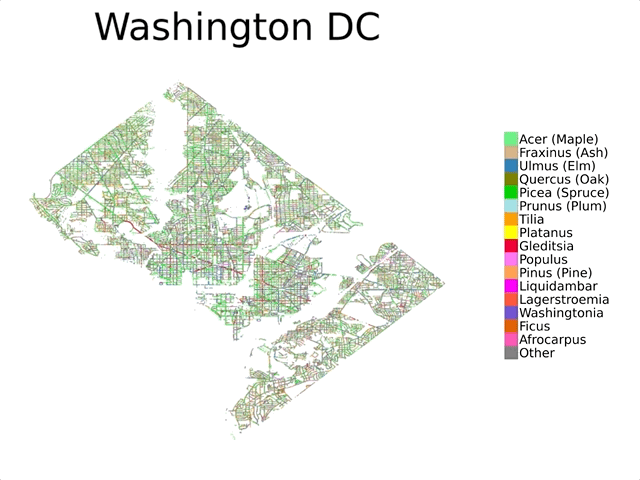
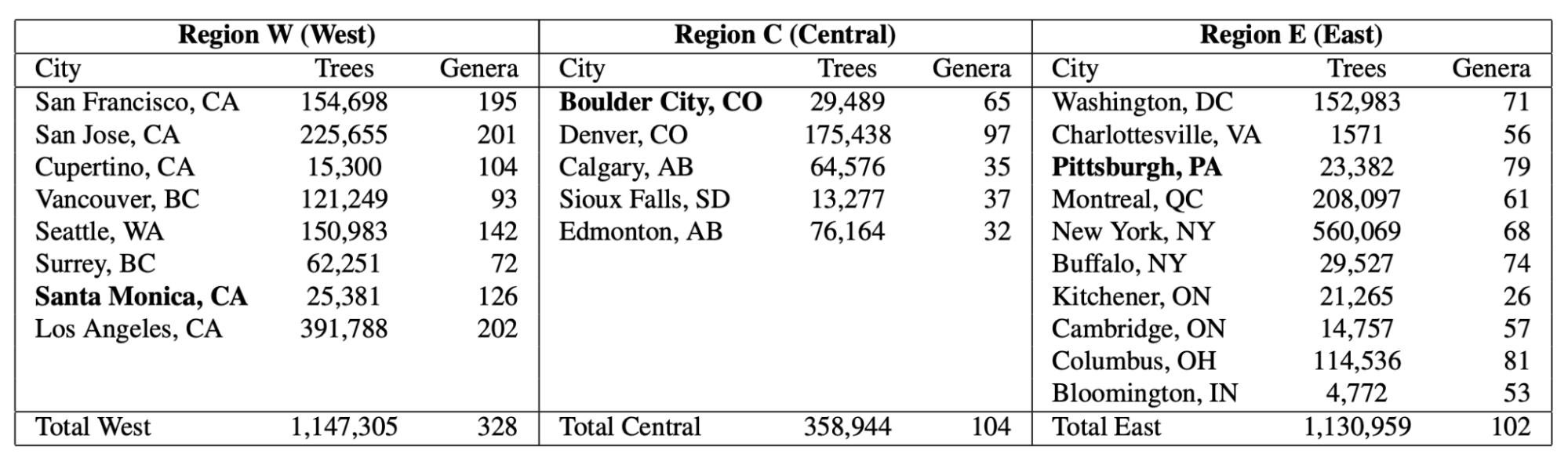
Today we introduce the Auto Arborist Dataset, a multiview urban tree classification dataset that, at ~2.6 million trees and >320 genera, is two orders of magnitude larger than those in prior work. To build the dataset, we pulled from public tree censuses from 23 North American cities (shown above) and merged these records with Street View and overhead RGB imagery. As the first urban forest dataset to cover multiple cities, we analyze in detail how forest models can generalize with respect to geographic distribution shifts, crucial to building systems that scale. We are releasing all 2.6M tree records publicly, along with aerial and ground-level imagery for 1M trees.
 |
| The 23 cities in the dataset are spread across North America, and are categorized into West, Central, and East regions to enable analysis of spatial and hierarchical generalization. |
 |
| The number of tree records and genera in the dataset, per city and per region. The holdout city (which is never seen during training in any capacity) for each region is in bold. |
The Auto Arborist Dataset
To curate Auto Arborist, we started from existing tree censuses which are provided by many cities online. For each tree census considered, we verified that the data contained GPS locations and genus/species labels, and was available for public use. We then parsed these data into a common format, fixing common data entry errors (such as flipped latitude/longitude) and mapping ground-truth genus names (and their common misspellings or alternate names) to a unified taxonomy. We have chosen to focus on genus prediction (instead of species-level prediction) as our primary task to avoid taxonomic complexity arising from hybrid and subspecies and the fact that there is more universal consensus on genus names than species names.
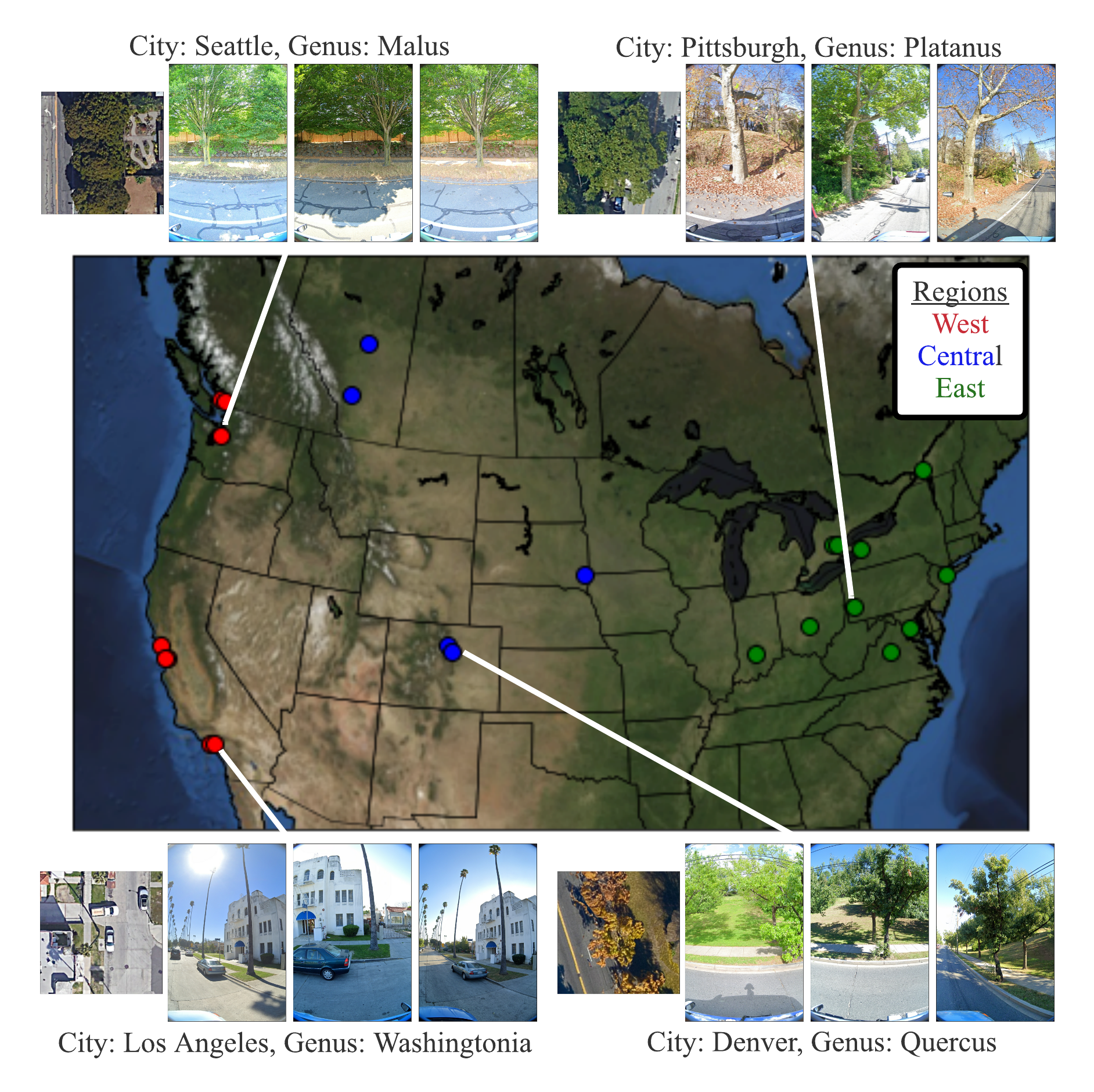
Next, using the provided geolocation for each tree, we queried an RGB aerial image centered on the tree and all street-level images taken within 2-10 meters around it. Finally, we filtered these images to (1) maximize our chances that the tree of interest is visible from each image and (2) preserve user privacy. This latter concern involved a number of steps including the removal of images that included people as determined by semantic segmentation and manual blurring, among others.
 |
| Selected Street View imagery from the Auto Arborist dataset. Green boxes represent tree detections (using a model trained on Open Images) and blue dots represent projected GPS location of the labeled tree. |
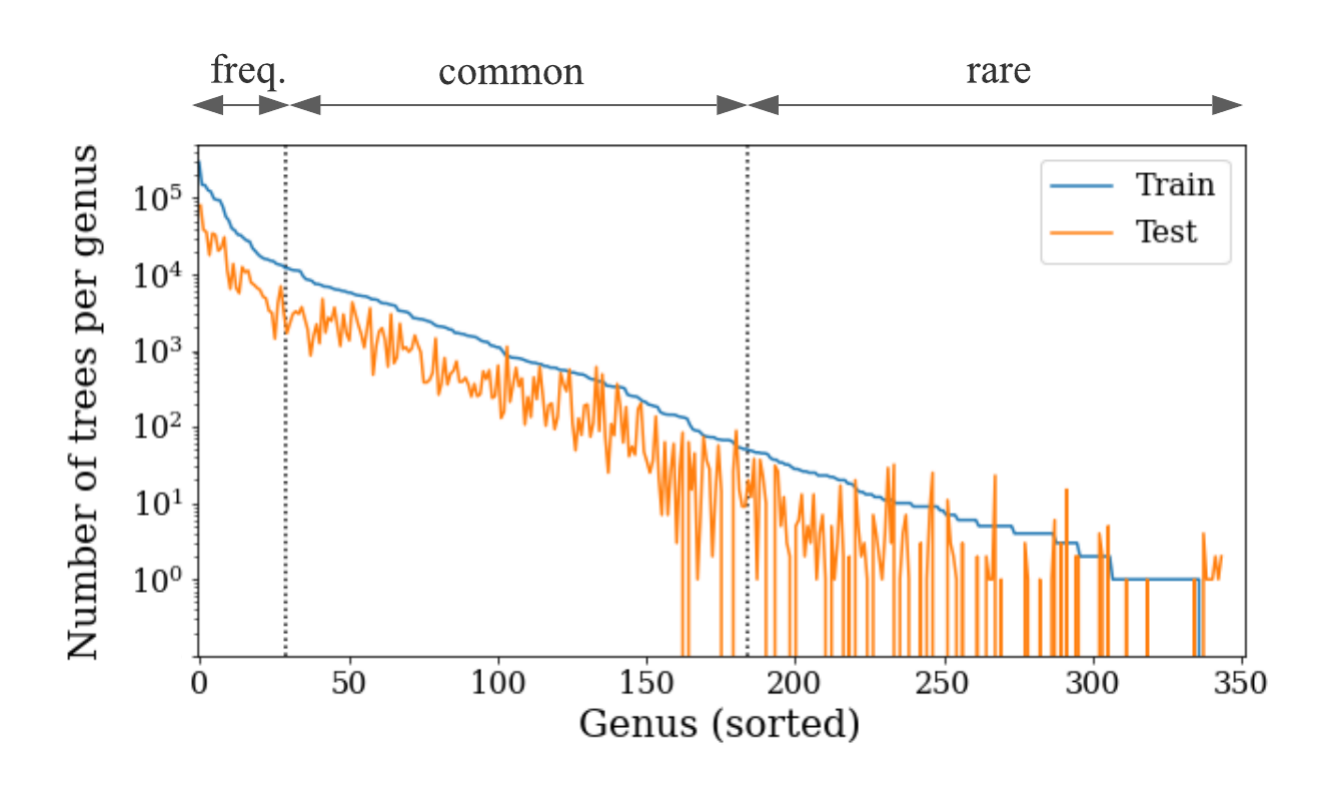
One of the most important challenges for urban forest monitoring is to do well in cities that were not part of the training set. Vision models must contend with distribution shifts, where the training distribution differs from the test distribution from a new city. Genus distributions vary geographically (e.g., there are more Douglas fir in western Canada than in California) and can also vary based on city size (LA is much larger than Santa Monica and contains many more genera). Another challenge is the long-tailed, fine-grained nature of tree genera, which can be difficult to disambiguate even for human experts, with many genera being quite rare.
 |
| The long-tailed distribution across Auto Arborist categories. Most examples come from a few frequent categories, and many categories have far fewer examples. We characterize each genus as frequent, common, or rare based on the number of training examples. Note that the test data is split spatially from the training data within each city, so not all rare genera are seen in the test set. |
Finally, there are a number of ways in which tree images can have noise. For one, there is temporal variation in deciduous trees (for example, when aerial imagery includes leaves, but street-level images are bare). Moreover, public arboreal censuses are not always up-to-date. Thus, sometimes trees have died (and are no longer visible) in the time since the tree census was taken. In addition, aerial data quality can be poor (missing or obscured, e.g., by clouds).
Our curation process sought to minimize these issues by (1) only keeping images with sufficient tree pixels, as determined by a semantic segmentation model, (2) only keeping reasonably recent images, and (3) only keeping images where the tree position was sufficiently close to the street level camera. We considered also optimizing for trees seen in spring and summer, but decided seasonal variation could be a useful cue — we thus also released the date of each image to enable the community to explore the effects of seasonal variability.
Benchmark and Evaluation
To evaluate the dataset, we designed a benchmark to measure domain generalization and performance in the long tail of the distribution. We generated training and test splits at three levels. First, we split within each city (based on latitude or longitude) to see how well a city generalizes to itself. Second, we aggregate city-level training sets into three regions, West, Central, and East, holding out one city from each region. Finally, we merge the training sets across the three regions. For each of these splits, we report both accuracy and class-averaged recall for frequent, common and rare species on the corresponding held-out test sets.
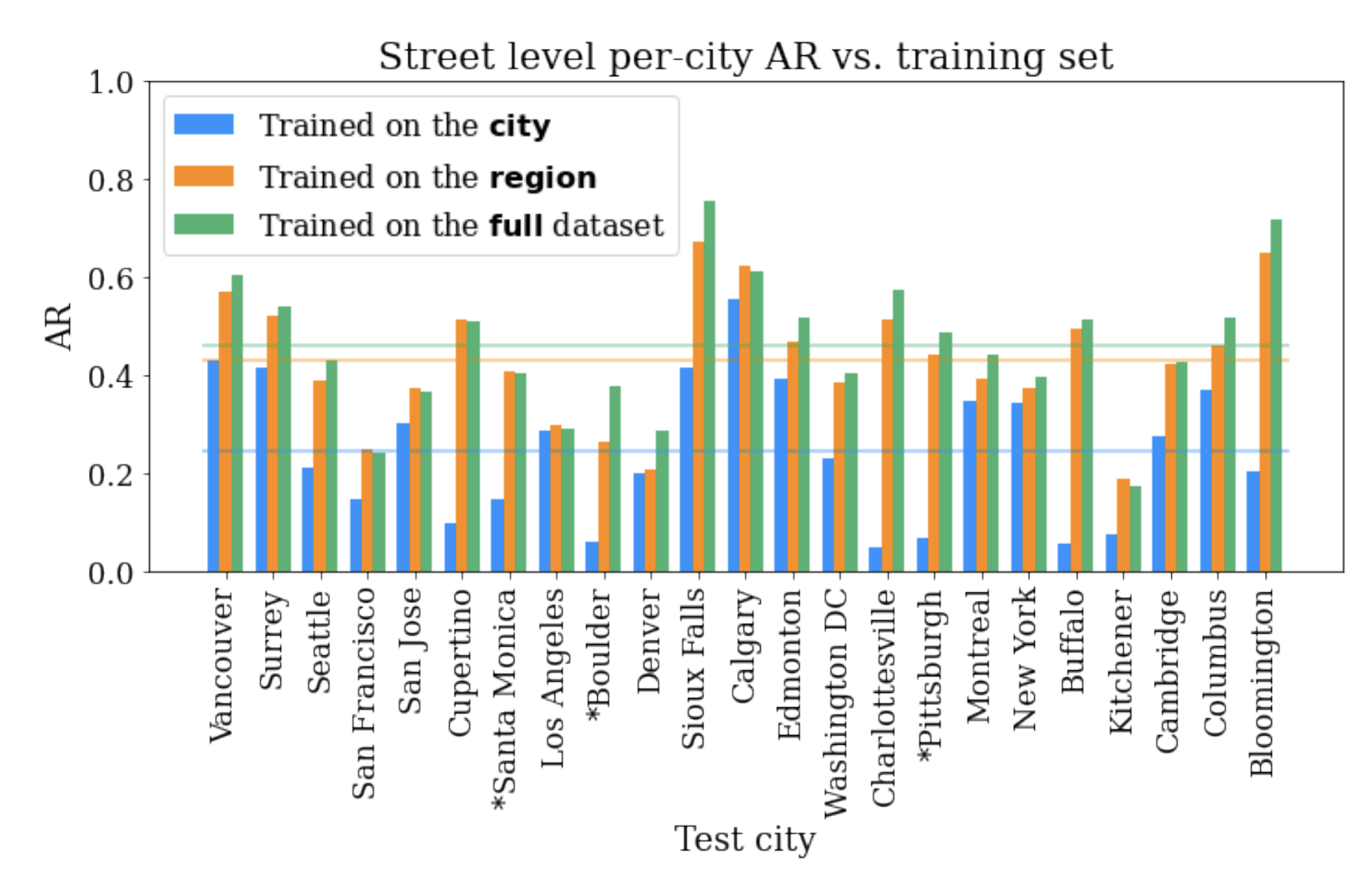
Using these metrics, we establish a performance baseline using standard modern convolutional models (ResNet). Our results demonstrate the benefits of a large-scale, geospatially distributed dataset such as Auto Arborist. First, we see that more training data helps — training on the entire dataset is better than training on a region, which is better than training on a single city.
 |
| The performance on each city’s test set when training on itself, on the region, and on the full training set. |
Second, training on similar cities helps (and thus, having more coverage of cities helps). For example, if focusing on Seattle, then it is better to train on trees in Vancouver than Pittsburgh.
 |
| Cross-set performance, looking at the pairwise combination of train and test sets for each city. Note the block-diagonal structure, which highlights regional structure in the dataset. |
Third, more data modalities and views help. The best performing models combine inputs from multiple Street View angles and overhead views. There remains much room for improvement, however, and this is where we believe the larger community of researchers can help.
Get Involved
By releasing the Auto Arborist Dataset, we step closer to the goal of affordable urban forest monitoring, enabling the computer vision community to tackle urban forest monitoring at scale for the first time. In the future, we hope to expand coverage to more North American cities (particularly in the South of the US and Mexico) and even worldwide. Further, we are excited to push the dataset to the more fine-grained species level and investigate more nuanced monitoring, including monitoring tree health and growth over time, and studying the effects of environmental factors on urban forests.
For more details, see our CVPR 2022 paper. This dataset is part of Google's broader efforts to empower cities with data about urban forests, through the Environmental Insights Explorer Tree Canopy Lab and is available on our GitHub repo. If you represent a city that is interested in being included in the dataset please email auto-arborist+managers@googlegroups.com.
Acknowledgements
We would like to thank our co-authors Guanhang Wu, Trevor Edwards, Filip Pavetic, Bo Majewski, Shreyasee Mukherjee, Stanley Chan, John Morgan, Vivek Rathod, and Chris Bauer. We also thank Ruth Alcantara, Tanya Birch, and Dan Morris from Google AI for Nature and Society, John Quintero, Stafford Marquardt, Xiaoqi Yin, Puneet Lall, and Matt Manolides from Google Geo, Karan Gill, Tom Duerig, Abhijit Kundu, David Ross, Vighnesh Birodkar, Yiwen Luo and Lily Pagan from Google Research (Perception team), and Pietro Perona for their support. This work was supported in part by the Resnick Sustainability Institute and was undertaken while Sara Beery was a Student Researcher at Google.
Quick links
Other posts of interest
-

February 17, 2026
Teaching AI to read a map- Machine Perception ·
- Open Source Models & Datasets
-

January 22, 2026
Small models, big results: Achieving superior intent extraction through decomposition- Generative AI ·
- Machine Perception ·
- Mobile Systems
-

December 12, 2025
Spotlight on innovation: Google-sponsored Data Science for Health Ideathon across Africa- Conferences & Events ·
- Generative AI ·
- Global ·
- Health & Bioscience