Mapping the modern world: How S2Vec learns the language of our cities
March 24, 2026
Shushman Choudhury, Research Scientist, Google Research
We introduce S2Vec, a self-supervised framework that transforms complex geospatial data into general-purpose embeddings to predict socioeconomic and environmental patterns across the globe.
Quick links
When we think about artificial intelligence and geography, we often focus on navigation, or getting from point A to point B. However, the built environment — the complex web of roads, buildings, businesses, and infrastructure that defines our world — contains far more information than just coordinates on a map. These features tell a story about socioeconomic health, environmental patterns, and urban development.
Until recently, translating these diverse geospatial features into formats that machine learning (ML) models can understand had been a manual and labor-intensive process. Researchers often had to hand-craft specific indicators for every new problem they wanted to solve. At Google Research, we’ve developed a new way to bridge this gap as part of the Google Earth AI initiative, which transforms planetary information into actionable intelligence using foundation models and advanced AI reasoning.
In line with the EarthAI vision, we recently introduced S2Vec, a self-supervised framework designed to learn general-purpose embeddings (i.e., compact, numerical summaries) of the built environment. S2Vec allows AI to understand the character of a neighborhood much like a human does, recognizing patterns in how gas stations, parks, and housing are distributed, and using that knowledge to predict metrics that matter, from population density to environmental impact. In our evaluations, S2Vec demonstrated competitive performance against image-based baselines in socioeconomic prediction tasks, particularly in geographic adaptation (extrapolation), while showing a clear need for improvement in environmental tasks, like tree cover and elevation.
The challenge: Going beyond points on a map
Geospatial data is notoriously difficult to work with because it is multimodal and varies wildly in scale. A city block might contain hundreds of data points (buildings, cafes, bus stops), while a rural area might have only a few. Standard ML models prefer structured, uniform data, like the grid of pixels in a photo.
To address this challenge, S2Vec uses a two-step process to rasterize the world:
- S2 Geometry partitioning: We use the S2 Geometry library to divide the Earth's surface into a hierarchy of cells. This allows us to look at the world at different resolutions, from a whole country down to a few square meters, and look up cells of any resolution for any location very efficiently. Our internally optimized version of the S2 library can seamlessly switch between cell resolutions covering a given location rapidly.
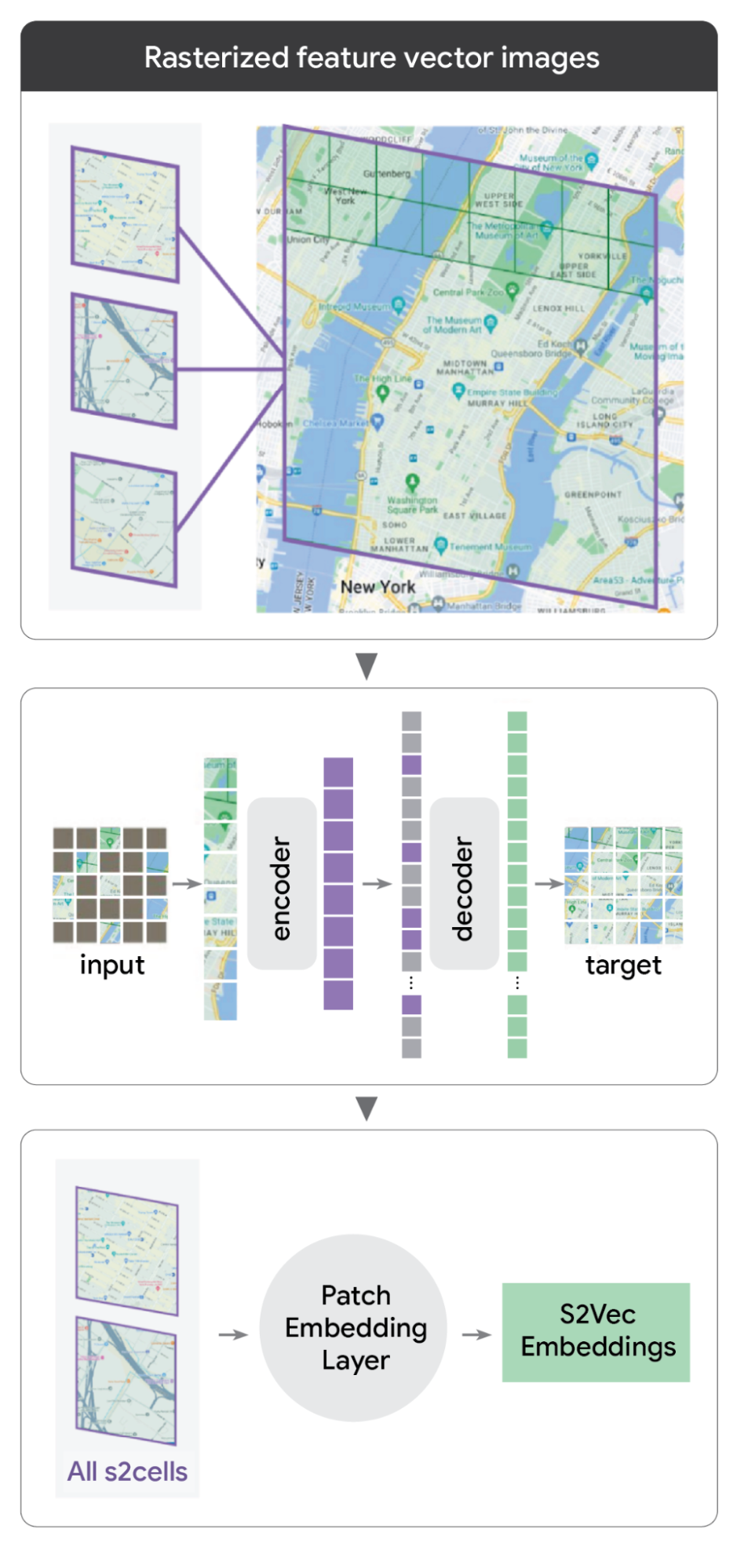
- Feature rasterization: Instead of treating buildings or roads as a list of coordinates, we count the types of features within each S2 cell and arrange them into a multi-layered image. If a cell has three coffee shops and one park, those become "colors" in our geospatial image.
This transformation allows us to treat geographical data of the built environment like a digital photograph that the AI can "see”. In turn, this rasterization opens up the vast and mature toolbox of computer vision techniques that have mostly solved the problem of natural image understanding.
S2Vec rasterizes images to learn embeddings of the built environment.
Masked autoencoding: Learning without labels
After transforming the built environment into rasterized feature images, S2Vec analyzes them using masked autoencoding (MAE), a robust self-supervised learning technique. While traditional ML relies on hand-crafted labels (e.g., manually tagging regions for income levels or air quality), self-supervision eliminates this bottleneck. Since labeling the entire planet is an impossible task, MAE allows us to unlock global insights without the need for manually crafted labels.
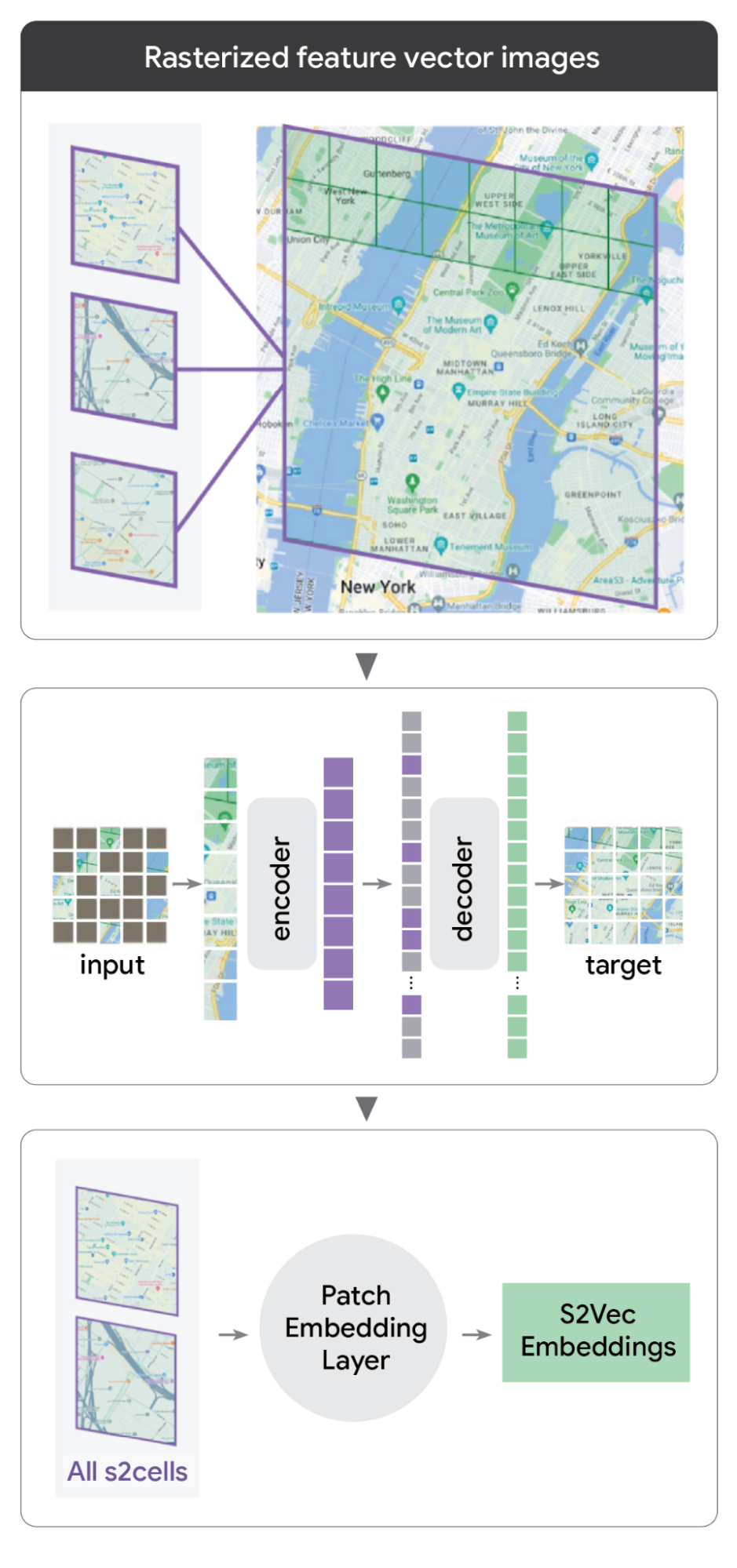
The MAE process systematically shows the model a “patch” of the built environment while hiding (masking) certain parts of it. The model then reconstructs the missing pieces based solely on the surrounding context:
- Contextual logic: If the model sees a cluster of high-rise residential buildings and a subway station, it learns to correctly predict that there is likely a grocery store in the masked area.
- Scale: By practicing this millions of times across the globe, the model learns the deep, underlying relationships between different urban features.
The output is a general-purpose embedding: a unique mathematical shorthand that captures the signature of a location. These strings of numbers represent a location’s characteristics, creating a foundation that can then be adapted for a range of tasks.
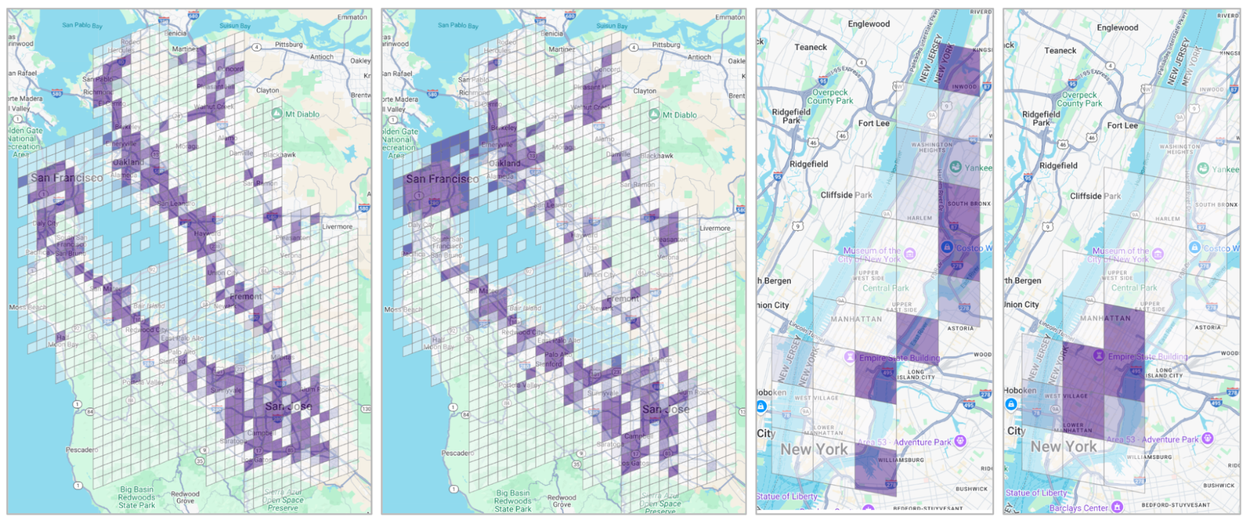
S2Vec captures the “character” of an urban area by dividing regions into grids in which each cell acts as a data point for “built environment” features like buildings and roads.
Next, the MAE learns to "fill in the blanks" of hidden map sections, identifying deep patterns in the built environment. This creates a powerful mathematical "embedding" for any location, allowing us to predict socioeconomic metrics like housing prices and population density with global scale and accuracy.
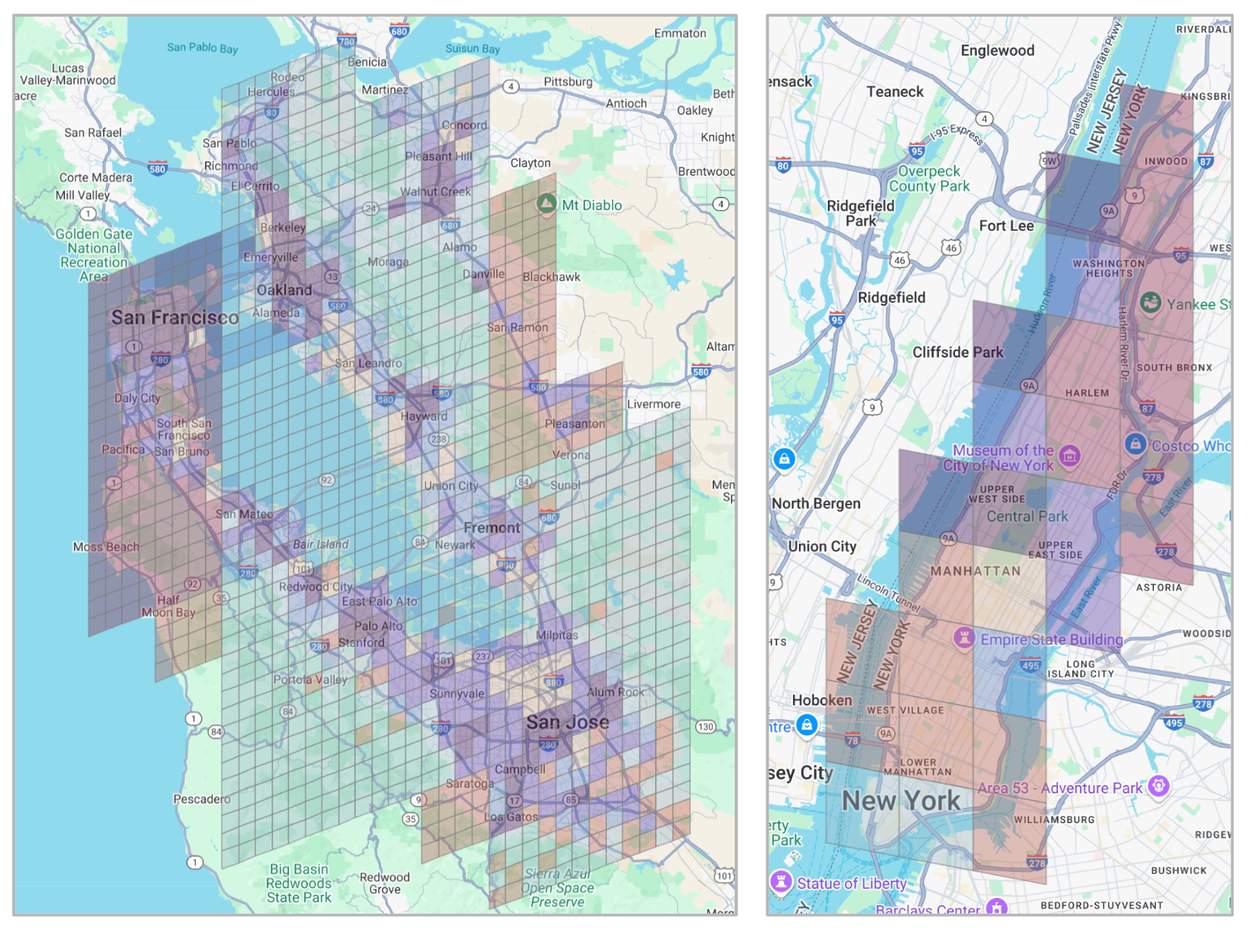
The S2Vec auto-encoder tags regions, essentially allowing them to be more deeply categorized and analyzed according to factors like socioeconomic data and population density.
Even without being told what a "financial district" or a "suburban residential zone" is, the model can group them together based purely on the spatial relationship of their features.
Evaluation
We compared S2Vec’s geospatial performance against several geospatial and image-based embedding approaches, including: SATCLIP, GEOCLIP, RS-MaMMUT, Hex2vec, and GeoVeX. The models were evaluated on multiple geospatial regression benchmarks, specifically predicting socioeconomic metrics like US-wide population density and median income, as well as environmental factors including carbon emissions, tree cover, and elevation.
- Loss function: Models were trained and tuned using mean squared error (MSE) loss.
- Task types: Performance was measured across two settings: random train/test splits (interpolation) and zero-shot geographic adaptation (extrapolation).
Socioeconomic strengths
S2Vec was typically found to be the best individual model for zero-shot geographic adaptation tasks, such as predicting US-wide median income or population density in unseen regions.
Multimodal fusion
Combining S2Vec with image-based embeddings (multimodal fusion) generally outperformed using any single individual modality.
Environmental weakness
While S2Vec was competitive in predicting environmental factors like carbon emissions, the results showed that "built environment" data alone isn't always enough. For these tasks, S2Vec performed best when combined with satellite imagery embeddings, which captures transportation, vegetation, and terrain features that building counts might miss.
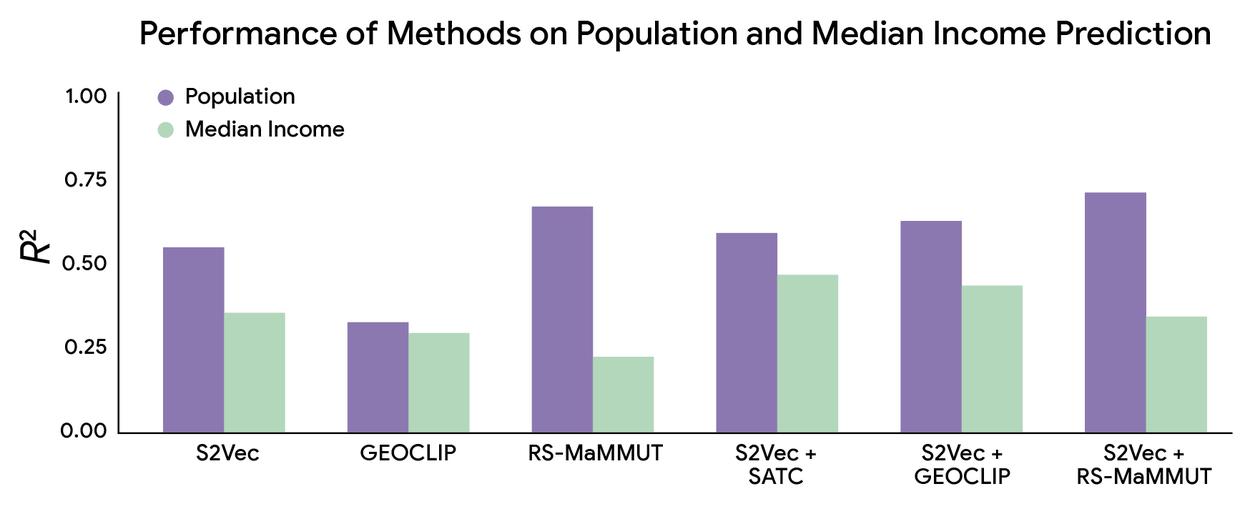
R2 (coefficient of determination) measures how well the model explains the dataset variation (range is 0 and 1, higher is better). Notably, S2Vec by itself performed just as well as industry standard RS-MaMMUT and better than GEOCLIP. As expected, S2Vec combined with RS-MaMMUT performed the best.
Conclusion
S2Vec represents a significant step toward foundational intelligence for geography. By creating a scalable, self-supervised way to represent the built environment, we are moving away from niche, hand-crafted models and toward a more general form of geospatial AI.
The implications of this kind of work are broad. Urban planners could use the insights derived from these embeddings and others like them to better understand how infrastructure changes affect neighborhood health, while environmental researchers can more accurately model the carbon footprint of rapidly growing cities.
Teaching AI to "read" the language of our streets and buildings yields a deeper, data-driven understanding of the world we’ve built. This aligns with our broader Earth AI mission to transform planetary information into actionable intelligence — an objective supported by our existing ecosystem of foundation models, the Population Dynamics Foundation Model (PDFM), and the Remote Sensing Foundations’ RS-MaMMUT VLM model. Together, these tools provide the scale and precision needed to map and manage our impact on the planet.
Acknowledgments
We’d like to thank the other co-authors on the paper: Iveel Tsogsuren, Chandrakumari Suvarna, Elad Aharoni, Abdul Rahman Kreidieh, Chun-ta Lu, and Neha Arora. We’d also like to thank Pranjal Awasthi for valuable insights.
Quick links
Other posts of interest
-

March 17, 2026
Google Research at The Check Up: from healthcare innovation to real-world care settings- Health & Bioscience ·
- Machine Intelligence
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

March 12, 2026
Protecting cities with AI-driven flash flood forecasting- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets