Making Visible Watermarks More Effective
August 17, 2017
Posted by Tali Dekel and Michael Rubinstein, Research Scientists
Quick links
Whether you are a photographer, a marketing manager, or a regular Internet user, chances are you have encountered visible watermarks many times. Visible watermarks are those logos and patterns that are often overlaid on digital images provided by stock photography websites, marking the image owners while allowing viewers to perceive the underlying content so that they could license the images that fit their needs. It is the most common mechanism for protecting the copyrights of hundreds of millions of photographs and stock images that are offered online daily.
It’s standard practice to use watermarks on the assumption that they prevent consumers from accessing the clean images, ensuring there will be no unauthorized or unlicensed use. However, in “On The Effectiveness Of Visible Watermarks” recently presented at the 2017 Computer Vision and Pattern Recognition Conference (CVPR 2017), we show that a computer algorithm can get past this protection and remove watermarks automatically, giving users unobstructed access to the clean images the watermarks are intended to protect.
 |
| Left: example watermarked images from popular stock photography websites. Right: watermark-free version of the images on the left, produced automatically by a computer algorithm. More results are available below and on our project page. Image sources: Adobe Stock, 123RF. |
The Vulnerability of Visible Watermarks
Visible watermarks are often designed to contain complex structures such as thin lines and shadows in order to make them harder to remove. Indeed, given a single image, for a computer to detect automatically which visual structures belong to the watermark and which structures belong to the underlying image is extremely difficult. Manually, the task of removing a watermark from an image is tedious, and even with state-of-the-art editing tools it may take a Photoshop expert several minutes to remove a watermark from one image.
However, a fact that has been overlooked so far is that watermarks are typically added in a consistent manner to many images. We show that this consistency can be used to invert the watermarking process — that is, estimate the watermark image and its opacity, and recover the original, watermark-free image underneath. This can all be done automatically, without any user intervention or prior information about the watermark, and by only observing watermarked image collections publicly available online.
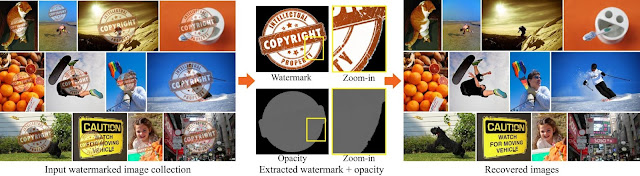
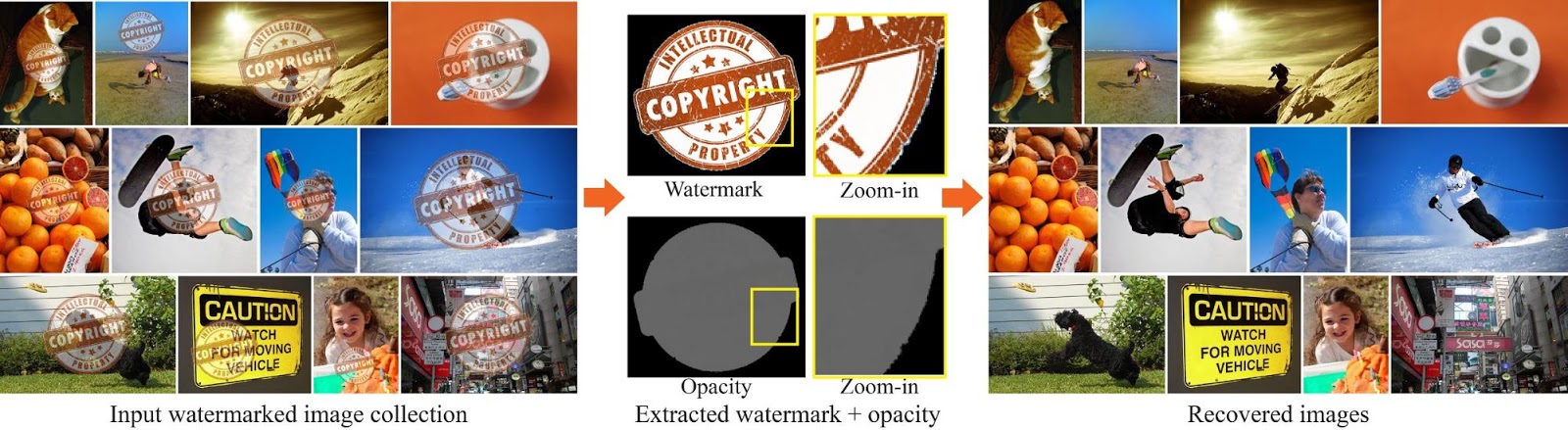 |
| The consistency of a watermark over many images allows to automatically remove it in mass scale. Left: input collection marked by the same watermark, middle: computed watermark and its opacity, right: recovered, watermark-free images. Image sources: COCO dataset, Copyright logo. |
 |
| Watermark extraction with increasing number of images. Left: watermarked input images, Middle: median intensities over the input images (up to the input image shown), Right: the corresponding estimated (matted) watermark. All images licensed from 123RF. |
Here are some more results, showing the estimated watermarks and example watermark-free results generated for several popular stock image services. We show many more results in our supplementary material on the project page.
 |
| Left column: Watermark estimated automatically from watermarked images online (rendered on a gray background). Middle colum: Input watermarked image. Right column: Automatically removed watermark. Image sources: Adobe Stock, Can Stock Photo, 123RF, Fotolia. |
The vulnerability of current watermarking techniques lies in the consistency in watermarks across image collections. Therefore, to counter it, we need to introduce inconsistencies when embedding the watermark in each image. In our paper we looked at several types of inconsistencies and how they affect the techniques described above. We found for example that simply changing the watermark’s position randomly per image does not prevent removing the watermark, nor do small random changes in the watermark’s opacity. But we found that introducing random geometric perturbations to the watermark — warping it when embedding it in each image — improves its robustness. Interestingly, very subtle warping is already enough to generate watermarks that this technique cannot fully defeat.
 |
| Flipping between the original watermark and a slightly, randomly warped watermark that can improve its robustness |

Here are some more results on the images from above when using subtle, randomly warped versions of the watermarks. Notice again how visible artifacts remain when trying to remove the watermark in this case, compared to the accurate reconstructions that are achievable with current, consistent watermarks. More results and a detailed analysis can be found in our paper and project page.
 |
| Left column: Watermarked image, using subtle, random warping of the watermark. Right Column: Watermark removal result. |
While we cannot guarantee that there will not be a way to break such randomized watermarking schemes in the future, we believe (and our experiments show) that randomization will make watermarked collection attacks fundamentally more difficult. We hope that these findings will be helpful for the photography and stock image communities.
Acknowledgements
The research described in this post was performed by Tali Dekel, Michael Rubinstein, Ce Liu and Bill Freeman. We thank Aaron Maschinot for narrating our video.
-
Labels:
- Machine Perception
- Photography
Quick links
Other posts of interest
-

February 17, 2026
Teaching AI to read a map- Machine Perception ·
- Open Source Models & Datasets
-

January 22, 2026
Small models, big results: Achieving superior intent extraction through decomposition- Generative AI ·
- Machine Perception ·
- Mobile Systems
-

October 23, 2025
Google Earth AI: Unlocking geospatial insights with foundation models and cross-modal reasoning- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Machine Perception
×
❮
❯