Looking to Listen: Audio-Visual Speech Separation
April 11, 2018
Posted by Inbar Mosseri and Oran Lang, Software Engineers, Google Research
Quick links
People are remarkably good at focusing their attention on a particular person in a noisy environment, mentally “muting” all other voices and sounds. Known as the cocktail party effect, this capability comes natural to us humans. However, automatic speech separation — separating an audio signal into its individual speech sources — while a well-studied problem, remains a significant challenge for computers.
In “Looking to Listen at the Cocktail Party”, to appear in SIGGRAPH 2018 this summer, we present a deep learning audio-visual model for isolating a single speech signal from a mixture of sounds such as other voices and background noise. In this work, we are able to computationally produce videos in which speech of specific people is enhanced while all other sounds are suppressed. Our method works on ordinary videos with a single audio track, and all that is required from the user is to select the face of the person in the video they want to hear, or to have such a person be selected algorithmically based on context. We believe this capability can have a wide range of applications, from speech enhancement and recognition in videos, through video conferencing, to improved hearing aids, especially in situations where there are multiple people speaking.
A unique aspect of our technique is in combining both the auditory and visual signals of an input video to separate the speech. Intuitively, movements of a person’s mouth, for example, should correlate with the sounds produced as that person is speaking, which in turn can help identify which parts of the audio correspond to that person. The visual signal not only improves the speech separation quality significantly in cases of mixed speech (compared to speech separation using audio alone, as we demonstrate in our paper), but, importantly, it also associates the separated, clean speech tracks with the visible speakers in the video.
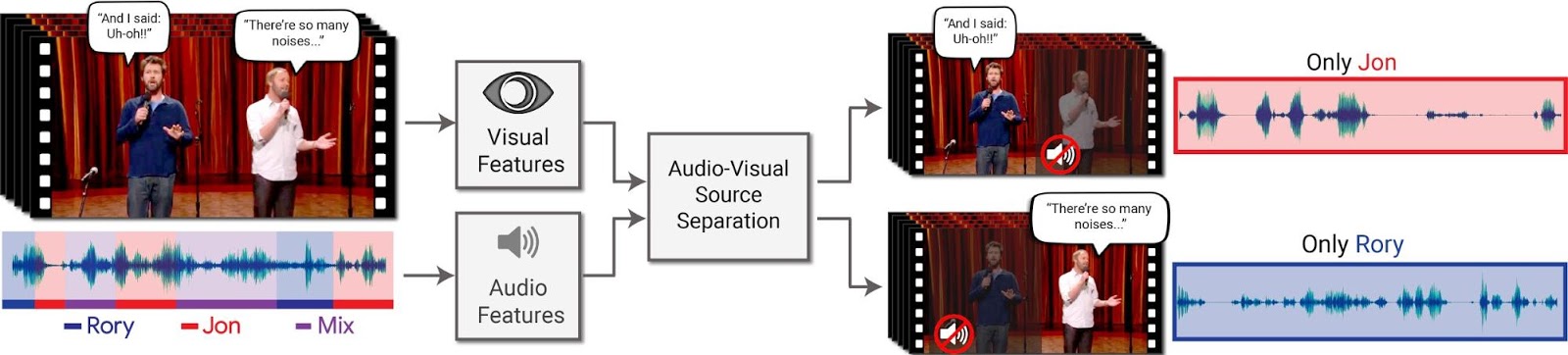 |
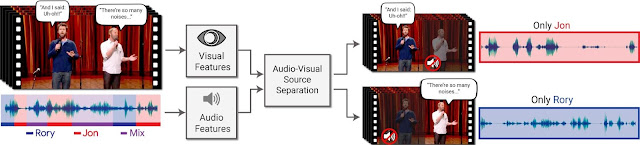
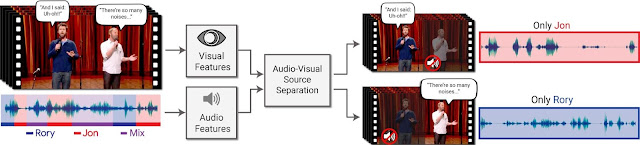
| The input to our method is a video with one or more people speaking, where the speech of interest is interfered by other speakers and/or background noise. The output is a decomposition of the input audio track into clean speech tracks, one for each person detected in the video. |
An Audio-Visual Speech Separation Model
To generate training examples, we started by gathering a large collection of 100,000 high-quality videos of lectures and talks from YouTube. From these videos, we extracted segments with a clean speech (e.g. no mixed music, audience sounds or other speakers) and with a single speaker visible in the video frames. This resulted in roughly 2000 hours of video clips, each of a single person visible to the camera and talking with no background interference. We then used this clean data to generate “synthetic cocktail parties” -- mixtures of face videos and their corresponding speech from separate video sources, along with non-speech background noise we obtained from AudioSet.
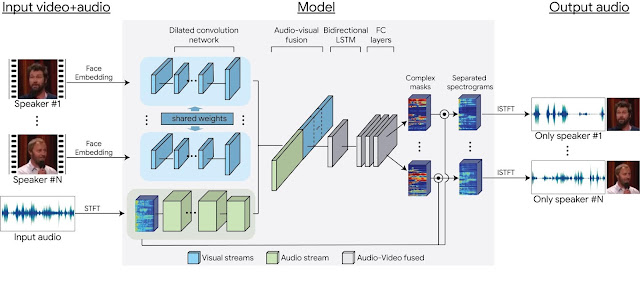
Using this data, we were able to train a multi-stream convolutional neural network-based model to split the synthetic cocktail mixture into separate audio streams for each speaker in the video. The input to the network are visual features extracted from the face thumbnails of detected speakers in each frame, and a spectrogram representation of the video’s soundtrack. During training, the network learns (separate) encodings for the visual and auditory signals, then it fuses them together to form a joint audio-visual representation. With that joint representation, the network learns to output a time-frequency mask for each speaker. The output masks are multiplied by the noisy input spectrogram and converted back to a time-domain waveform to obtain an isolated, clean speech signal for each speaker. For full details, see our paper.
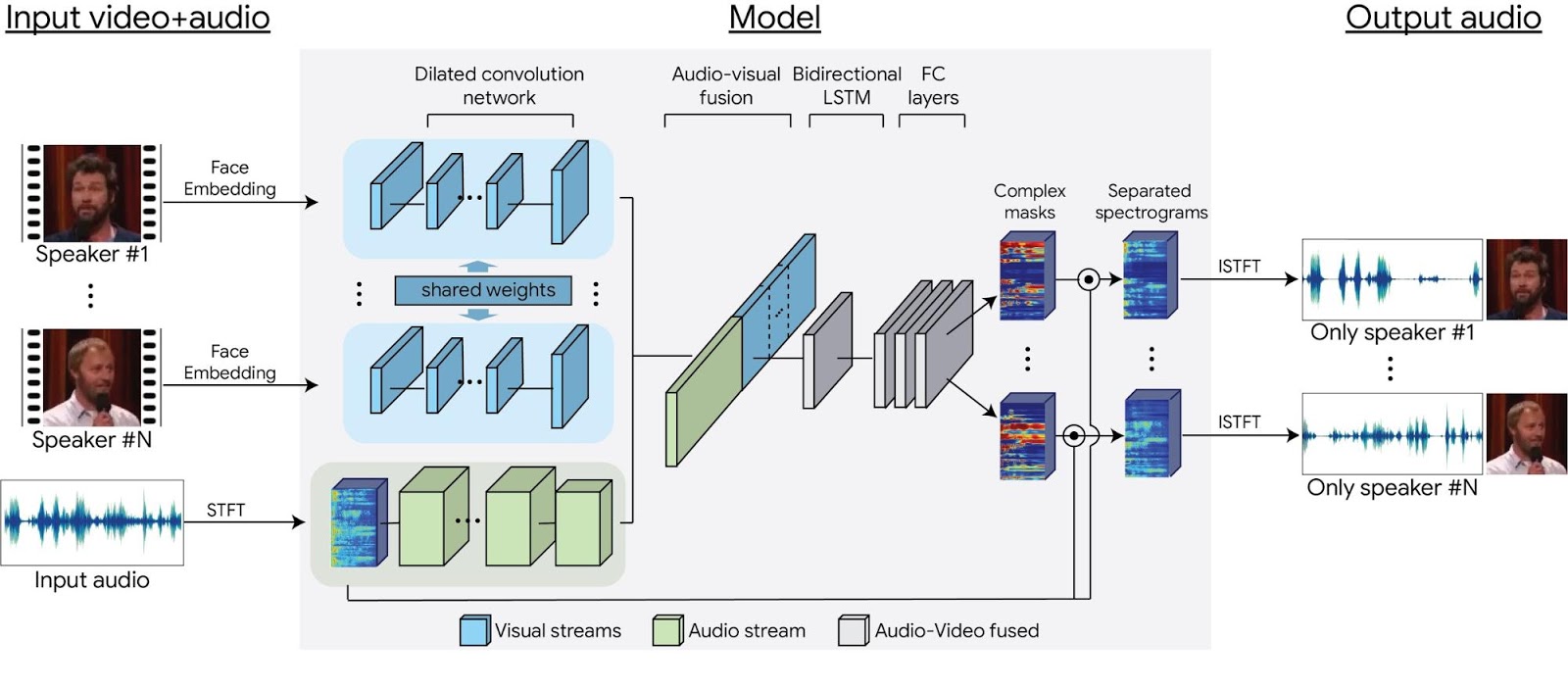 |
| Our multi-stream, neural network-based model architecture. |
Here are some more speech separation and enhancement results by our method, playing first the input video with mixed or noisy speech, then our results. Sound by others than the selected speakers can be entirely suppressed or suppressed to the desired level.
Application to Speech Recognition
Our method can also potentially be used as a pre-process for speech recognition and automatic video captioning. Handling overlapping speakers is a known challenge for automatic captioning systems, and separating the audio to the different sources could help in presenting more accurate and easy-to-read captions.
You can similarly see and compare the captions before and after speech separation in all the other videos in this post and on our website, by turning on closed captions in the YouTube player when playing the videos (“cc” button at the lower right corner of the player).
On our project web page you can find more results, as well as comparisons with state-of-the-art audio-only speech separation and with other recent audio-visual speech separation work. Indeed, with recent advances in deep learning, there is a clear growing interest in the academic community in audio-visual analysis. For example, independently and concurrently to our work, this work from UC Berkeley explored a self-supervised approach for separating speech of on/off-screen speakers, and this work from MIT addressed the problem of separating the sound of multiple on-screen objects (e.g., musical instruments), while locating the image regions from which the sound originates.
We envision a wide range of applications for this technology. We are currently exploring opportunities for incorporating it into various Google products. Stay tuned!
Acknowledgements
The research described in this post was done by Ariel Ephrat (as an intern), Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, Bill Freeman and Michael Rubinstein. We would like to thank Yossi Matias and Google Research Israel for their support for the project, and John Hershey for his valuable feedback. We also thank Arkady Ziefman for his help with animations and figures, and Rachel Soh for helping us procure permissions for video content in our results.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence