LOLNeRF: Learn from One Look
September 13, 2022
Posted by Daniel Rebain, Student Researcher, and Mark Matthews, Senior Software Engineer, Google Research, Perception Team
Quick links
An important aspect of human vision is our ability to comprehend 3D shape from the 2D images we observe. Achieving this kind of understanding with computer vision systems has been a fundamental challenge in the field. Many successful approaches rely on multi-view data, where two or more images of the same scene are available from different perspectives, which makes it much easier to infer the 3D shape of objects in the images.
There are, however, many situations where it would be useful to know 3D structure from a single image, but this problem is generally difficult or impossible to solve. For example, it isn’t necessarily possible to tell the difference between an image of an actual beach and an image of a flat poster of the same beach. However it is possible to estimate 3D structure based on what kind of 3D objects occur commonly and what similar structures look like from different perspectives.
In “LOLNeRF: Learn from One Look”, presented at CVPR 2022, we propose a framework that learns to model 3D structure and appearance from collections of single-view images. LOLNeRF learns the typical 3D structure of a class of objects, such as cars, human faces or cats, but only from single views of any one object, never the same object twice. We build our approach by combining Generative Latent Optimization (GLO) and neural radiance fields (NeRF) to achieve state-of-the-art results for novel view synthesis and competitive results for depth estimation.
 |
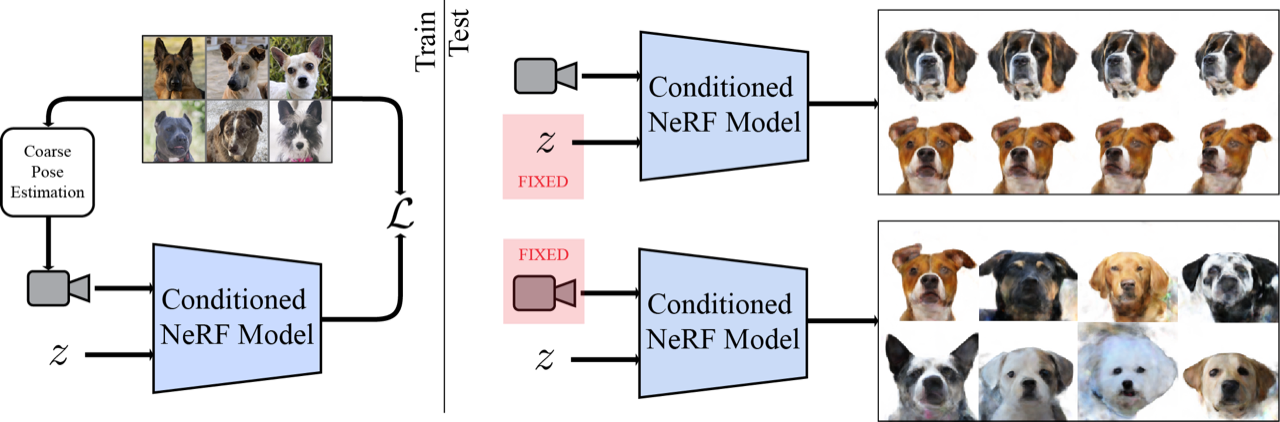
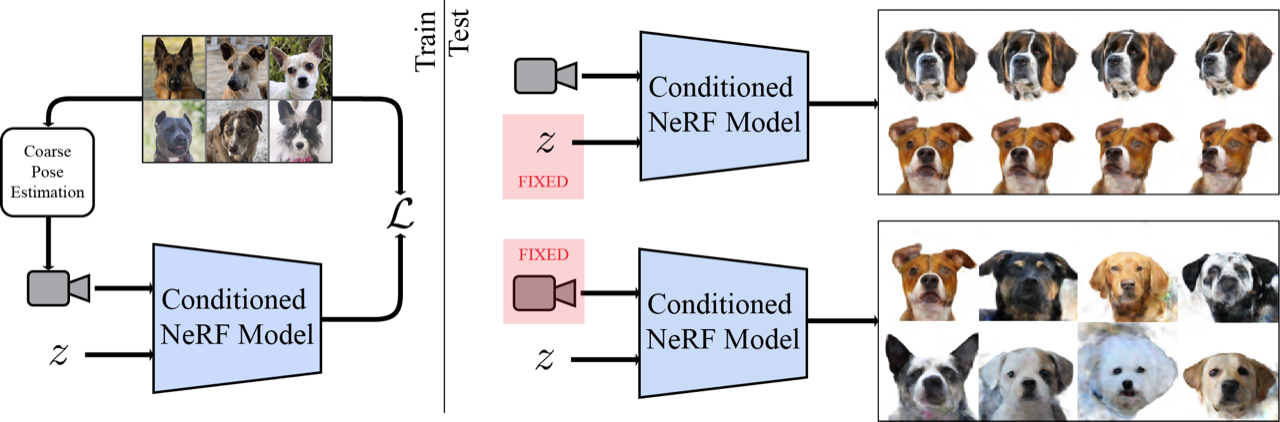
| We learn a 3D object model by reconstructing a large collection of single-view images using a neural network conditioned on latent vectors, z (left). This allows for a 3D model to be lifted from the image, and rendered from novel viewpoints. Holding the camera fixed, we can interpolate or sample novel identities (right). |
Combining GLO and NeRF
GLO is a general method that learns to reconstruct a dataset (such as a set of 2D images) by co-learning a neural network (decoder) and table of codes (latents) that is also an input to the decoder. Each of these latent codes re-creates a single element (such as an image) from the dataset. Because the latent codes have fewer dimensions than the data elements themselves, the network is forced to generalize, learning common structure in the data (such as the general shape of dog snouts).
NeRF is a technique that is very good at reconstructing a static 3D object from 2D images. It represents an object with a neural network that outputs color and density for each point in 3D space. Color and density values are accumulated along rays, one ray for each pixel in a 2D image. These are then combined using standard computer graphics volume rendering to compute a final pixel color. Importantly, all these operations are differentiable, allowing for end-to-end supervision. By enforcing that each rendered pixel (of the 3D representation) matches the color of ground truth (2D) pixels, the neural network creates a 3D representation that can be rendered from any viewpoint.
We combine NeRF with GLO by assigning each object a latent code and concatenating it with standard NeRF inputs, giving it the ability to reconstruct multiple objects. Following GLO, we co-optimize these latent codes along with network weights during training to reconstruct the input images. Unlike standard NeRF, which requires multiple views of the same object, we supervise our method with only single views of any one object (but multiple examples of that type of object). Because NeRF is inherently 3D, we can then render the object from arbitrary viewpoints. Combining NeRF with GLO gives it the ability to learn common 3D structure across instances from only single views while still retaining the ability to recreate specific instances of the dataset.
Camera Estimation
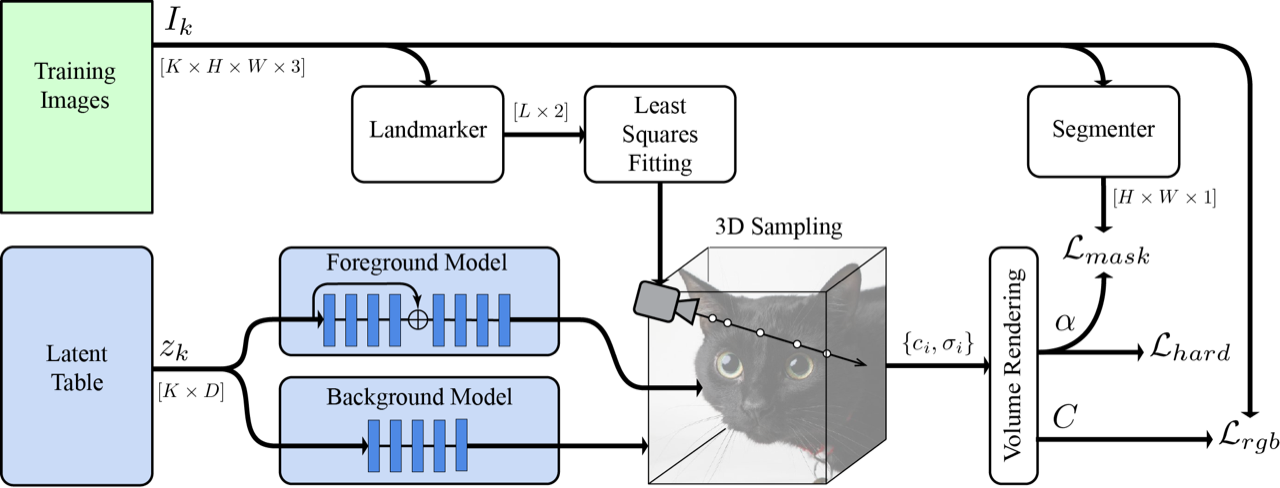
In order for NeRF to work, it needs to know the exact camera location, relative to the object, for each image. Unless this was measured when the image was taken, it is generally unknown. Instead, we use the MediaPipe Face Mesh to extract five landmark locations from the images. Each of these 2D predictions correspond to a semantically consistent point on the object (e.g., the tip of the nose or corners of the eyes). We can then derive a set of canonical 3D locations for the semantic points, along with estimates of the camera poses for each image, such that the projection of the canonical points into the images is as consistent as possible with the 2D landmarks.
 |
| We train a per-image table of latent codes alongside a NeRF model. Output is subject to per-ray RGB, mask and hardness losses. Cameras are derived from a fit of predicted landmarks to canonical 3D keypoints. |
 |
| Example MediaPipe landmarks and segmentation masks (images from CelebA). |
Hard Surface and Mask Losses
Standard NeRF is effective for accurately reproducing the images, but in our single-view case, it tends to produce images that look blurry when viewed off-axis. To address this, we introduce a novel hard surface loss, which encourages the density to adopt sharp transitions from exterior to interior regions, reducing blurring. This essentially tells the network to create “solid” surfaces, and not semi-transparent ones like clouds.
We also obtained better results by splitting the network into separate foreground and background networks. We supervised this separation with a mask from the MediaPipe Selfie Segmenter and a loss to encourage network specialization. This allows the foreground network to specialize only on the object of interest, and not get “distracted” by the background, increasing its quality.
Results
We surprisingly found that fitting only five key points gave accurate enough camera estimates to train a model for cats, dogs, or human faces. This means that given only a single view of your beloved cats Schnitzel, Widget and friends, you can create a new image from any other angle.
 |
| Top: example cat images from AFHQ. Bottom: A synthesis of novel 3D views created by LOLNeRF. |
Conclusion
We’ve developed a technique that is effective at discovering 3D structure from single 2D images. We see great potential in LOLNeRF for a variety of applications and are currently investigating potential use-cases.
 |
| Interpolation of feline identities from linear interpolation of learned latent codes for different examples in AFHQ. |
Code Release
We acknowledge the potential for misuse and importance of acting responsibly. To that end, we will only release the code for reproducibility purposes, but will not release any trained generative models.
Acknowledgements
We would like to thank Andrea Tagliasacchi, Kwang Moo Yi, Viral Carpenter, David Fleet, Danica Matthews, Florian Schroff, Hartwig Adam and Dmitry Lagun for continuous help in building this technology.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence