Lidar-Camera Deep Fusion for Multi-Modal 3D Detection
April 12, 2022
Posted by Yingwei Li, Student Researcher, Google Cloud and Adams Wei Yu, Research Scientist, Google Research, Brain Team
Quick links
LiDAR and visual cameras are two types of complementary sensors used for 3D object detection in autonomous vehicles and robots. LiDAR, which is a remote sensing technique that uses light in the form of a pulsed laser to measure ranges, provides low-resolution shape and depth information, while cameras provide high-resolution shape and texture information. While the features captured by LiDAR and cameras should be merged together to provide optimal 3D object detection, it turns out that most state-of-the-art 3D object detectors use LiDAR as the only input. The main reason is that to develop robust 3D object detection models, most methods need to augment and transform the data from both modalities, making the accurate alignment of the features challenging.
Existing algorithms for fusing LiDAR and camera outputs, such as PointPainting, PointAugmenting, EPNet, 4D-Net and ContinuousFusion, generally follow two approaches — input-level fusion where the features are fused at an early stage, decorating points in the LiDAR point cloud with the corresponding camera features, or mid-level fusion where features are extracted from both sensors and then combined. Despite realizing the importance of effective alignment, these methods struggle to efficiently process the common scenario where features are enhanced and aggregated before fusion. This indicates that effectively fusing the signals from both sensors might not be straightforward and remains challenging.
In our CVPR 2022 paper, “DeepFusion: LiDAR-Camera Deep Fusion for Multi-Modal 3D Object Detection”, we introduce a fully end-to-end multi-modal 3D detection framework called DeepFusion that applies a simple yet effective deep-level feature fusion strategy to unify the signals from the two sensing modalities. Unlike conventional approaches that decorate raw LiDAR point clouds with manually selected camera features, our method fuses the deep camera and deep LiDAR features in an end-to-end framework. We begin by describing two novel techniques, InverseAug and LearnableAlign, that improve the quality of feature alignment and are applied to the development of DeepFusion. We then demonstrate state-of-the-art performance by DeepFusion on the Waymo Open Dataset, one of the largest datasets for automotive 3D object detection.
InverseAug: Accurate Alignment under Geometric Augmentation
To achieve good performance on existing 3D object detection benchmarks for autonomous cars, most methods require strong data augmentation during training to avoid overfitting. However, the necessity of data augmentation poses a non-trivial challenge in the DeepFusion pipeline. Specifically, the data from the two modalities use different augmentation strategies, e.g., rotating along the z-axis for 3D point clouds combined with random flipping for 2D camera images, often resulting in alignment that is inaccurate. Then the augmented LiDAR data has to go through a voxelization step that converts the point clouds into volume data stored in a three dimensional array of voxels. The voxelized features are quite different compared to the raw data, making the alignment even more difficult. To address the alignment issue caused by geometry-related data augmentation, we introduce Inverse Augmentation (InverseAug), a technique used to reverse the augmentation before fusion during the model’s training phase.
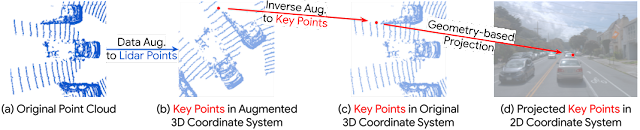
In the example below, we demonstrate the difficulties in aligning the augmented LiDAR data with the camera data. In this case, the LiDAR point cloud is augmented by rotation with the result that a given 3D key point, which could be any 3D coordinate, such as a LiDAR data point, cannot be easily aligned in 2D space simply through use of the original LiDAR and camera parameters. To make the localization feasible, InverseAug first stores the augmentation parameters before applying the geometry-related data augmentation. At the fusion stage, it reverses all data augmentation to get the original coordinate for the 3D key point, and then finds its corresponding 2D coordinates in the camera space.
 |
| During training, InverseAug resolves the inaccurate alignment from geometric augmentation. |
 |
| Left: Alignment without InverseAug. Right: Alignment quality improvement with InverseAug. |
LearnableAlign: A Cross-Modality-Attention Module to Learn Alignment
We also introduce Learnable Alignment (LearnableAlign), a cross-modality-attention–based feature-level alignment technique, to improve the alignment quality. For input-level fusion methods, such as PointPainting and PointAugmenting, given a 3D LiDAR point, only the corresponding camera pixel can be exactly located as there is a one-to-one mapping. In contrast, when fusing deep features in the DeepFusion pipeline, each LiDAR feature represents a voxel containing a subset of points, and hence, its corresponding camera pixels are in a polygon. So the alignment becomes the problem of learning the mapping between a voxel cell and a set of pixels.
A naïve approach is to average over all pixels corresponding to the given voxel. However, intuitively, and as supported by our visualized results, these pixels are not equally important because the information from the LiDAR deep feature unequally aligns with every camera pixel. For example, some pixels may contain critical information for detection (e.g., the target object), while others may be less informative (e.g., consisting of backgrounds such as roads, plants, occluders, etc.).
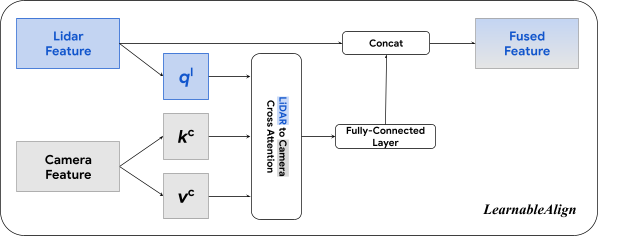
LearnableAlign leverages a cross-modality attention mechanism to dynamically capture the correlations between two modalities. Here, the input contains the LiDAR features in a voxel cell, and all its corresponding camera features. The output of the attention is essentially a weighted sum of the camera features, where the weights are collectively determined by a function of the LiDAR and camera features. More specifically, LearnableAlign uses three fully-connected layers to respectively transform the LiDAR features to a vector (ql), and camera features to vectors (kc) and (vc). For each vector (ql), we compute the dot products between (ql) and (kc) to obtain the attention affinity matrix that contains correlations between the LiDAR features and the corresponding camera features. Normalized by a softmax operator, the attention affinity matrix is then used to calculate weights and aggregate the vectors (vc) that contain camera information. The aggregated camera information is then processed by a fully-connected layer, and concatenated (Concat) with the original LiDAR feature. The output is then fed into any standard 3D detection framework, such as PointPillars or CenterPoint for model training.
 |
| LearnableAlign leverages the cross-attention mechanism to align LiDAR and camera features. |
DeepFusion: A Better Way to Fuse Information from Different Modalities
Powered by our two novel feature alignment techniques, we develop DeepFusion, a fully end-to-end multi-modal 3D detection framework. In the DeepFusion pipeline, the LiDAR points are first fed into an existing feature extractor (e.g., pillar feature net from PointPillars) to obtain LiDAR features (e.g., pseudo-images). In the meantime, the camera images are fed into a 2D image feature extractor (e.g., ResNet) to obtain camera features. Then, InverseAug and LearnableAlign are applied in order to fuse the camera and LiDAR features together. Finally, the fused features are processed by the remaining components of the selected 3D detection model (e.g., the backbone and detection head from PointPillars) to obtain the detection results.
 |
| The pipeline of DeepFusion. |
Benchmark Results
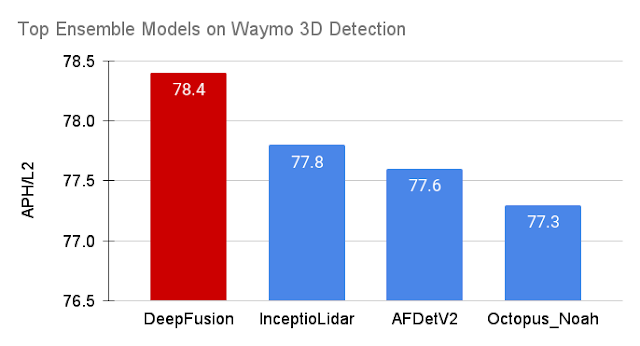
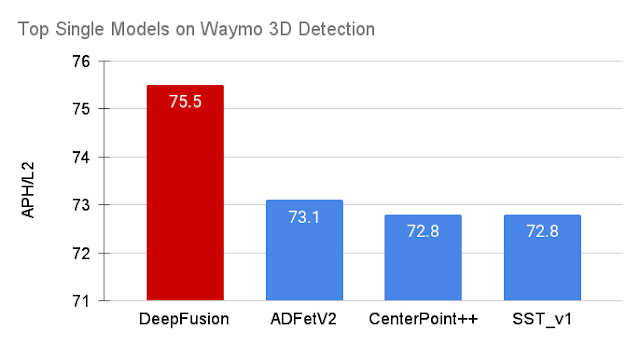
We evaluate DeepFusion on the Waymo Open Dataset, one of the largest 3D detection challenges for autonomous cars, using the Average Precision with Heading (APH) metric under difficulty level 2, the default metric to rank a model’s performance on the leaderboard. Among the 70 participating teams all over the world, the DeepFusion single and ensemble models achieve state-of-the-art performance in their corresponding categories.
 |
| The single DeepFusion model achieves new state-of-the-art performance on Waymo Open Dataset. |
 |
| The Ensemble DeepFusion model outperforms all other methods on Waymo Open Dataset, ranking No. 1 on the leaderboard. |
The Impact of InverseAug and LearnableAlign
We also conduct ablation studies on the effectiveness of the proposed InverseAug and LearnableAlign techniques. We demonstrate that both InverseAug and LearnableAlign individually contribute to a performance gain over the LiDAR-only model, and combining both can further yield an even more significant boost.
 |
| Ablation studies on InverseAug (IA) and LearnableAlign (LA) measured in average precision (AP) and APH. Combining both techniques contributes to the best performance gain. |
Conclusion
We demonstrate that late-stage deep feature fusion can be more effective when features are aligned well, but aligning features from two different modalities can be challenging. To address this challenge, we propose two techniques, InverseAug and LearnableAlign, to improve the quality of alignment among multimodal features. By integrating these techniques into the fusion stage of our proposed DeepFusion method, we achieve state-of-the-art performance on the Waymo Open Dataset.
Acknowledgements:
Special thanks to co-authors Tianjian Meng, Ben Caine, Jiquan Ngiam, Daiyi Peng, Junyang Shen, Bo Wu, Yifeng Lu, Denny Zhou, Quoc Le, Alan Yuille, Mingxing Tan.
-
Labels:
- Machine Perception
Quick links
Other posts of interest
-

February 17, 2026
Teaching AI to read a map- Machine Perception ·
- Open Source Models & Datasets
-

January 22, 2026
Small models, big results: Achieving superior intent extraction through decomposition- Generative AI ·
- Machine Perception ·
- Mobile Systems
-

October 23, 2025
Google Earth AI: Unlocking geospatial insights with foundation models and cross-modal reasoning- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Machine Perception