Leveraging Machine Learning for Game Development
March 19, 2021
Posted by Ji Hun Kim and Richard Wu, Software Engineers, Stadia
Quick links
Over the years, online multiplayer games have exploded in popularity, captivating millions of players across the world. This popularity has also exponentially increased demands on game designers, as players expect games to be well-crafted and balanced — after all, it's no fun to play a game where a single strategy beats all the rest.
In order to create a positive gameplay experience, game designers typically tune the balance of a game iteratively:
- Stress-test through thousands of play-testing sessions from test users
- Incorporate feedback and re-design the game
- Repeat 1 & 2 until both the play-testers and game designers are satisfied
This process is not only time-consuming but also imperfect — the more complex the game, the easier it is for subtle flaws to slip through the cracks. When games often have many different roles that can be played, with dozens of interconnecting skills, it makes it all the more difficult to hit the right balance.
Today, we present an approach that leverages machine learning (ML) to adjust game balance by training models to serve as play-testers, and demonstrate this approach on the digital card game prototype Chimera, which we’ve previously shown as a testbed for ML-generated art. By running millions of simulations using trained agents to collect data, this ML-based game testing approach enables game designers to more efficiently make a game more fun, balanced, and aligned with their original vision.
Chimera
We developed Chimera as a game prototype that would heavily lean on machine learning during its development process. For the game itself, we purposefully designed the rules to expand the possibility space, making it difficult to build a traditional hand-crafted AI to play the game.
The gameplay of Chimera revolves around the titular chimeras, creature mash-ups that players aim to strengthen and evolve. The objective of the game is to defeat the opponent's chimera. These are the key points in the game design:
- Players may play:
- creatures, which can attack (through their attack stat) or be attacked (against their health stat), or
- spells, which produce special effects.
- Creatures are summoned into limited-capacity biomes, which are placed physically on the board space. Each creature has a preferred biome and will take repeated damage if placed on an incorrect biome or a biome that is over capacity.
- A player controls a single chimera, which starts off in a basic "egg" state and can be evolved and strengthened by absorbing creatures. To do this, the player must also acquire a certain amount of link energy, which is generated from various gameplay mechanics.
- The game ends when a player has successfully brought the health of the opponent's chimera to 0.
Learning to Play Chimera
As an imperfect information card game with a large state space, we expected Chimera to be a difficult game for an ML model to learn, especially as we were aiming for a relatively simple model. We used an approach inspired by those used by earlier game-playing agents like AlphaGo, in which a convolutional neural network (CNN) is trained to predict the probability of a win when given an arbitrary game state. After training an initial model on games where random moves were chosen, we set the agent to play against itself, iteratively collecting game data, that was then used to train a new agent. With each iteration, the quality of the training data improved, as did the agent’s ability to play the game.
 |
| The ML agent's performance against our best hand-crafted AI as training progressed. The initial ML agent (version 0) picked moves randomly. |
For the actual game state representation that the model would receive as input, we found that passing an "image" encoding to the CNN resulted in the best performance, beating all benchmark procedural agents and other types of networks (e.g. fully connected). The chosen model architecture is small enough to run on a CPU in reasonable time, which allowed us to download the model weights and run the agent live in a Chimera game client using Unity Barracuda.
 |
| An example game state representation used to train the neural network. |
 |
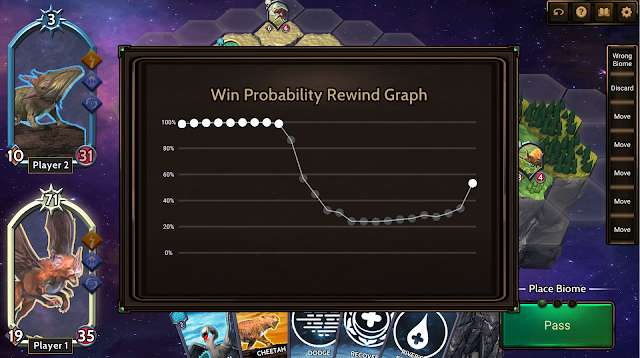
| In addition to making decisions for the game AI, we also used the model to display the estimated win probability for a player over the course of the game. |
Balancing Chimera
This approach enabled us to simulate millions more games than real players would be capable of playing in the same time span. After collecting data from the games played by the best-performing agents, we analyzed the results to find imbalances between the two of the player decks we had designed.
First, the Evasion Link Gen deck was composed of spells and creatures with abilities that generated extra link energy used to evolve a player’s chimera. It also contained spells that enabled creatures to evade attacks. In contrast, the Damage-Heal deck contained creatures of variable strength with spells that focused on healing and inflicting minor damage. Although we had designed these decks to be of equal strength, the Evasion Link Gen deck was winning 60% of the time when played against the Damage-Heal deck.
When we collected various stats related to biomes, creatures, spells, and chimera evolutions, two things immediately jumped out at us:
- There was a clear advantage in evolving a chimera — the agent won a majority of the games where it evolved its chimera more than the opponent did. Yet, the average number of evolves per game did not meet our expectations. To make it more of a core game mechanic, we wanted to increase the overall average number of evolves while keeping its usage strategic.
- The T-Rex creature was overpowered. Its appearances correlated strongly with wins, and the model would always play the T-Rex regardless of penalties for summoning into an incorrect or overcrowded biome.
From these insights, we made some adjustments to the game. To emphasize chimera evolution as a core mechanism in the game, we decreased the amount of link energy required to evolve a chimera from 3 to 1. We also added a “cool-off” period to the T-Rex creature, doubling the time it took to recover from any of its actions.
Repeating our ‘self-play’ training procedure with the updated rules, we observed that these changes pushed the game in the desired direction — the average number of evolves per game increased, and the T-Rex's dominance faded.
 |
| One example comparison of the T-Rex’s influence before and after balancing. The charts present the number of games won (or lost) when a deck initiates a particular spell interaction (e.g., using the “Dodge” spell to benefit a T-Rex). Left: Before the changes, the T-Rex had a strong influence in every metric examined — highest survival rate, most likely to be summoned ignoring penalties, most absorbed creature during wins. Right: After the changes, the T-Rex was much less overpowered. |
By weakening the T-Rex, we successfully reduced the Evasion Link Gen deck's reliance on an overpowered creature. Even so, the win ratio between the decks remained at 60/40 rather than 50/50. A closer look at the individual game logs revealed that the gameplay was often less strategic than we would have liked. Searching through our gathered data again, we found several more areas to introduce changes in.
To start, we increased the starting health of both players as well as the amount of health that healing spells could replenish. This was to encourage longer games that would allow a more diverse set of strategies to flourish. In particular, this enabled the Damage-Heal deck to survive long enough to take advantage of its healing strategy. To encourage proper summoning and strategic biome placement, we increased the existing penalties on playing creatures into incorrect or overcrowded biomes. And finally, we decreased the gap between the strongest and weakest creatures through minor attribute adjustments.
New adjustments in place, we arrived at the final game balance stats for these two decks:
| Deck | Avg # evolves per game (before → after) |
Win % (1M games) (before → after) |
| Evasion Link Gen | 1.54 → 2.16 | 59.1% → 49.8% |
| Damage Heal | 0.86 → 1.76 | 40.9% → 50.2% |
Conclusion
Normally, identifying imbalances in a newly prototyped game can take months of playtesting. With this approach, we were able to not only discover potential imbalances but also introduce tweaks to mitigate them in a span of days. We found that a relatively simple neural network was sufficient to reach high level performance against humans and traditional game AI. These agents could be leveraged in further ways, such as for coaching new players or discovering unexpected strategies. We hope this work will inspire more exploration in the possibilities of machine learning for game development.
Acknowledgements
This project was conducted in collaboration with many people. Thanks to Ryan Poplin, Maxwell Hannaman, Taylor Steil, Adam Prins, Michal Todorovic, Xuefan Zhou, Aaron Cammarata, Andeep Toor, Trung Le, Erin Hoffman-John, and Colin Boswell. Thanks to everyone who contributed through playtesting, advising on game design, and giving valuable feedback.
-
Labels:
- Machine Intelligence
Quick links
Other posts of interest
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

March 11, 2026
Exploring the feasibility of conversational diagnostic AI in a real-world clinical study- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

March 4, 2026
Teaching LLMs to reason like Bayesians- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing