Learning from deep learning: a case study of feature discovery and validation in pathology
March 14, 2023
Posted by Ellery Wulczyn and Yun Liu, Google Research
Quick links
When a patient is diagnosed with cancer, one of the most important steps is examination of the tumor under a microscope by pathologists to determine the cancer stage and to characterize the tumor. This information is central to understanding clinical prognosis (i.e., likely patient outcomes) and for determining the most appropriate treatment, such as undergoing surgery alone versus surgery plus chemotherapy. Developing machine learning (ML) tools in pathology to assist with the microscopic review represents a compelling research area with many potential applications.
Previous studies have shown that ML can accurately identify and classify tumors in pathology images and can even predict patient prognosis using known pathology features, such as the degree to which gland appearances deviate from normal. While these efforts focus on using ML to detect or quantify known features, alternative approaches offer the potential to identify novel features. The discovery of new features could in turn further improve cancer prognostication and treatment decisions for patients by extracting information that isn’t yet considered in current workflows.
Today, we’d like to share progress we’ve made over the past few years towards identifying novel features for colorectal cancer in collaboration with teams at the Medical University of Graz in Austria and the University of Milano-Bicocca (UNIMIB) in Italy. Below, we will cover several stages of the work: (1) training a model to predict prognosis from pathology images without specifying the features to use, so that it can learn what features are important; (2) probing that prognostic model using explainability techniques; and (3) identifying a novel feature and validating its association with patient prognosis. We describe this feature and evaluate its use by pathologists in our recently published paper, “Pathologist validation of a machine-learned feature for colon cancer risk stratification”. To our knowledge, this is the first demonstration that medical experts can learn new prognostic features from machine learning, a promising start for the future of this “learning from deep learning” paradigm.
Training a prognostic model to learn what features are important
One potential approach to identifying novel features is to train ML models to directly predict patient outcomes using only the images and the paired outcome data. This is in contrast to training models to predict “intermediate” human-annotated labels for known pathologic features and then using those features to predict outcomes.
Initial work by our team showed the feasibility of training models to directly predict prognosis for a variety of cancer types using the publicly available TCGA dataset. It was especially exciting to see that for some cancer types, the model's predictions were prognostic after controlling for available pathologic and clinical features. Together with collaborators from the Medical University of Graz and the Biobank Graz, we subsequently extended this work using a large de-identified colorectal cancer cohort. Interpreting these model predictions became an intriguing next step, but common interpretability techniques were challenging to apply in this context and did not provide clear insights.
Interpreting the model-learned features
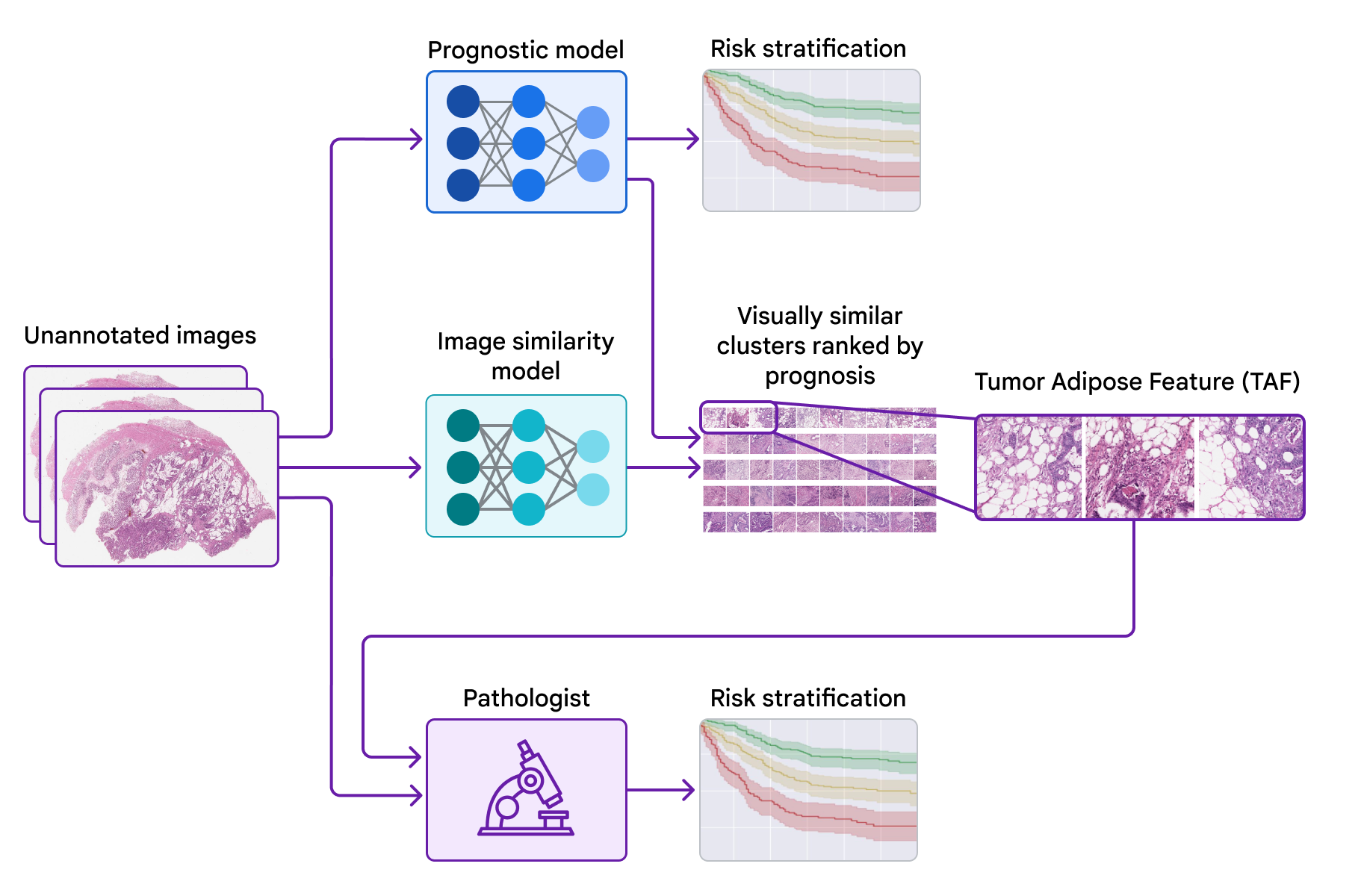
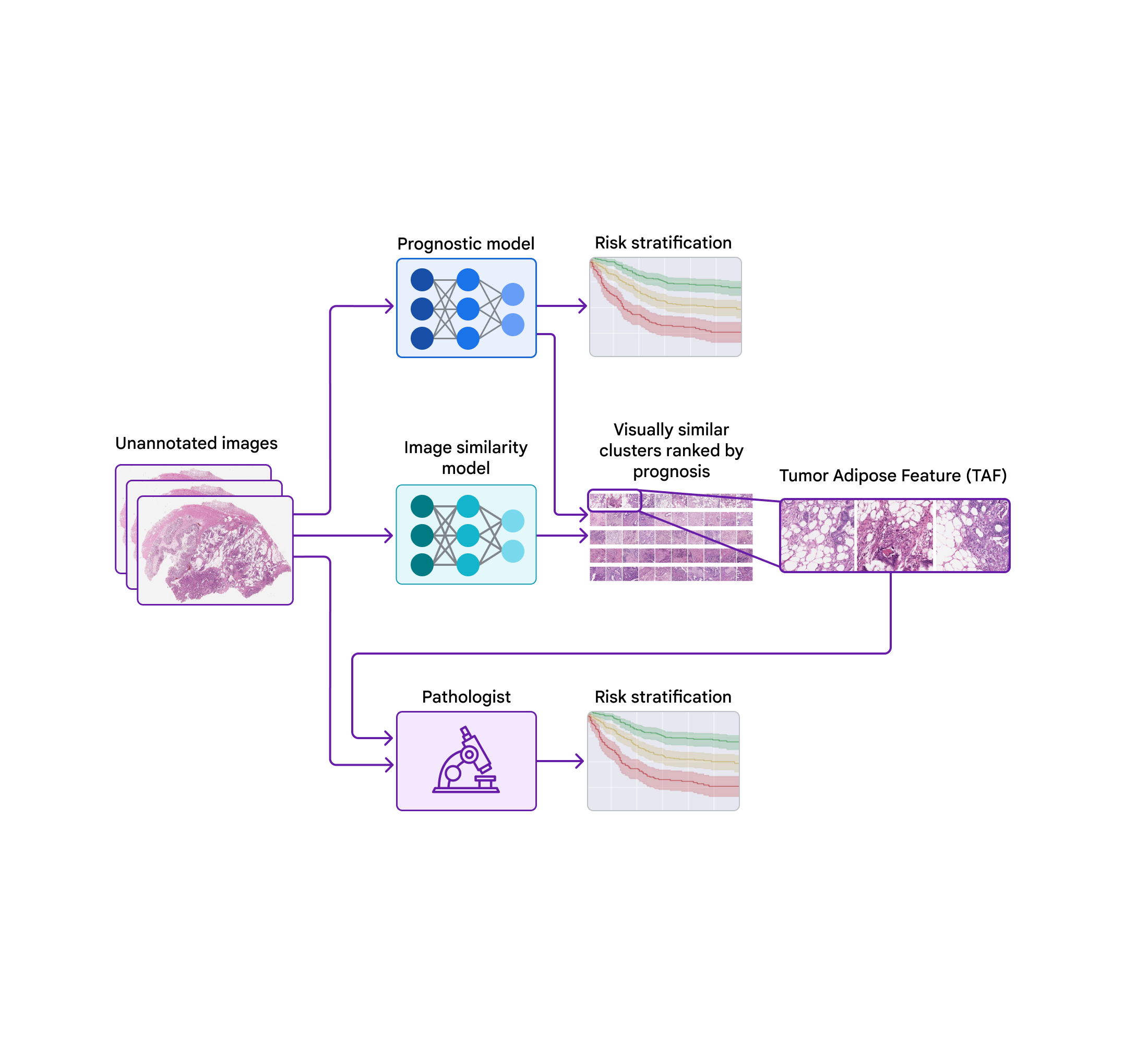
To probe the features used by the prognostic model, we used a second model (trained to identify image similarity) to cluster cropped patches of the large pathology images. We then used the prognostic model to compute the average ML-predicted risk score for each cluster.
One cluster stood out for its high average risk score (associated with poor prognosis) and its distinct visual appearance. Pathologists described the images as involving high grade tumor (i.e., least-resembling normal tissue) in close proximity to adipose (fat) tissue, leading us to dub this cluster the “tumor adipose feature” (TAF); see next figure for detailed examples of this feature. Further analysis showed that the relative quantity of TAF was itself highly and independently prognostic.
 |
| A prognostic ML model was developed to predict patient survival directly from unannotated giga-pixel pathology images. A second image similarity model was used to cluster cropped patches of pathology images. The prognostic model was used to compute the average model-predicted risk score for each cluster. One cluster, dubbed the “tumor adipose feature” (TAF) stood out in terms of its high average risk score (associated with poor survival) and distinct visual appearance. Pathologists learned to identify TAF and pathologist scoring for TAF was shown to be prognostic. |
 |
 |
| Left: H&E pathology slide with an overlaid heatmap indicating locations of the tumor adipose feature (TAF). Regions highlighted in red/orange are considered to be more likely TAF by the image similarity model, compared to regions highlighted in green/blue or regions not highlighted at all. Right: Representative collection of TAF patches across multiple cases. |
Validating that the model-learned feature can be used by pathologists
These studies provided a compelling example of the potential for ML models to predict patient outcomes and a methodological approach for obtaining insights into model predictions. However, there remained the intriguing questions of whether pathologists could learn and score the feature identified by the model while maintaining demonstrable prognostic value.
In our most recent paper, we collaborated with pathologists from the UNIMIB to investigate these questions. Using example images of TAF from the previous publication to learn and understand this feature of interest, UNIMIB pathologists developed scoring guidelines for TAF. If TAF was not seen, the case was scored as “absent”, and if TAF was observed, then “unifocal”, “multifocal”, and “widespread” categories were used to indicate the relative quantity. Our study showed that pathologists could reproducibly identify the ML-derived TAF and that their scoring for TAF provided statistically significant prognostic value on an independent retrospective dataset. To our knowledge, this is the first demonstration of pathologists learning to identify and score a specific pathology feature originally identified by an ML-based approach.
Putting things in context: learning from deep learning as a paradigm
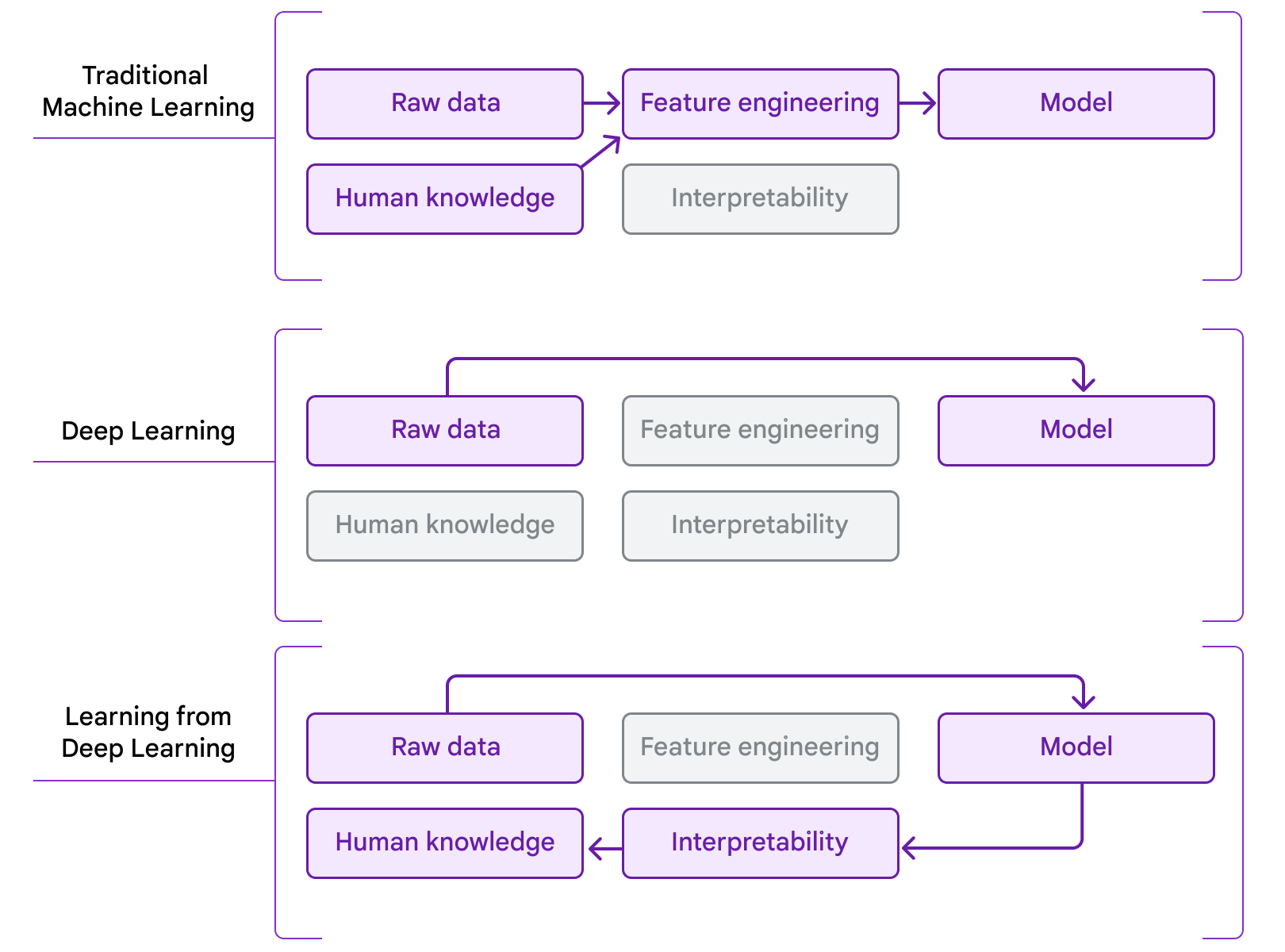
Our work is an example of people “learning from deep learning”. In traditional ML, models learn from hand-engineered features informed by existing domain knowledge. More recently, in the deep learning era, a combination of large-scale model architectures, compute, and datasets has enabled learning directly from raw data, but this is often at the expense of human interpretability. Our work couples the use of deep learning to predict patient outcomes with interpretability methods, to extract new knowledge that could be applied by pathologists. We see this process as a natural next step in the evolution of applying ML to problems in medicine and science, moving from the use of ML to distill existing human knowledge to people using ML as a tool for knowledge discovery.
 |
| Traditional ML focused on engineering features from raw data using existing human knowledge. Deep learning enables models to learn features directly from raw data at the expense of human interpretability. Coupling deep learning with interpretability methods provides an avenue for expanding the frontiers of scientific knowledge by learning from deep learning. |
Acknowledgements
This work would not have been possible without the efforts of coauthors Vincenzo L'Imperio, Markus Plass, Heimo Muller, Nicolò' Tamini, Luca Gianotti, Nicola Zucchini, Robert Reihs, Greg S. Corrado, Dale R. Webster, Lily H. Peng, Po-Hsuan Cameron Chen, Marialuisa Lavitrano, David F. Steiner, Kurt Zatloukal, Fabio Pagni. We also appreciate the support from Verily Life Sciences and the Google Health Pathology teams – in particular Timo Kohlberger, Yunnan Cai, Hongwu Wang, Kunal Nagpal, Craig Mermel, Trissia Brown, Isabelle Flament-Auvigne, and Angela Lin. We also appreciate manuscript feedback from Akinori Mitani, Rory Sayres, and Michael Howell, and illustration help from Abi Jones. This work would also not have been possible without the support of Christian Guelly, Andreas Holzinger, Robert Reihs, Farah Nader, Melissa Moran, Robert Nagle, the Biobank Graz, the efforts of the slide digitization teams at the Medical University Graz and Google, the participation of the pathologists who reviewed and annotated cases during model development, and the technicians of the UNIMIB team.
Quick links
Other posts of interest
-

June 12, 2026
Research into how AI can help users understand skin conditions- Health & Bioscience ·
- Human-Computer Interaction and Visualization
-

June 4, 2026
Towards passive heart health monitoring via smartphone camera- Health & Bioscience ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

May 1, 2026
Catalyzing scientific impact through global partnerships and open resources- Data Mining & Modeling ·
- General Science ·
- Health & Bioscience ·
- Open Source Models & Datasets