
Launching the Speech Commands Dataset
August 24, 2017
Posted by Pete Warden, Software Engineer, Google Brain Team
Quick links
At Google, we’re often asked how to get started using deep learning for speech and other audio recognition problems, like detecting keywords or commands. And while there are some great open source speech recognition systems like Kaldi that can use neural networks as a component, their sophistication makes them tough to use as a guide to a simpler tasks. Perhaps more importantly, there aren’t many free and openly available datasets ready to be used for a beginner’s tutorial (many require preprocessing before a neural network model can be built on them) or that are well suited for simple keyword detection.
To solve these problems, the TensorFlow and AIY teams have created the Speech Commands Dataset, and used it to add training* and inference sample code to TensorFlow. The dataset has 65,000 one-second long utterances of 30 short words, by thousands of different people, contributed by members of the public through the AIY website. It’s released under a Creative Commons BY 4.0 license, and will continue to grow in future releases as more contributions are received. The dataset is designed to let you build basic but useful voice interfaces for applications, with common words like “Yes”, “No”, digits, and directions included. The infrastructure we used to create the data has been open sourced too, and we hope to see it used by the wider community to create their own versions, especially to cover underserved languages and applications.
To try it out for yourself, download the prebuilt set of the TensorFlow Android demo applications and open up “TF Speech”. You’ll be asked for permission to access your microphone, and then see a list of ten words, each of which should light up as you say them.
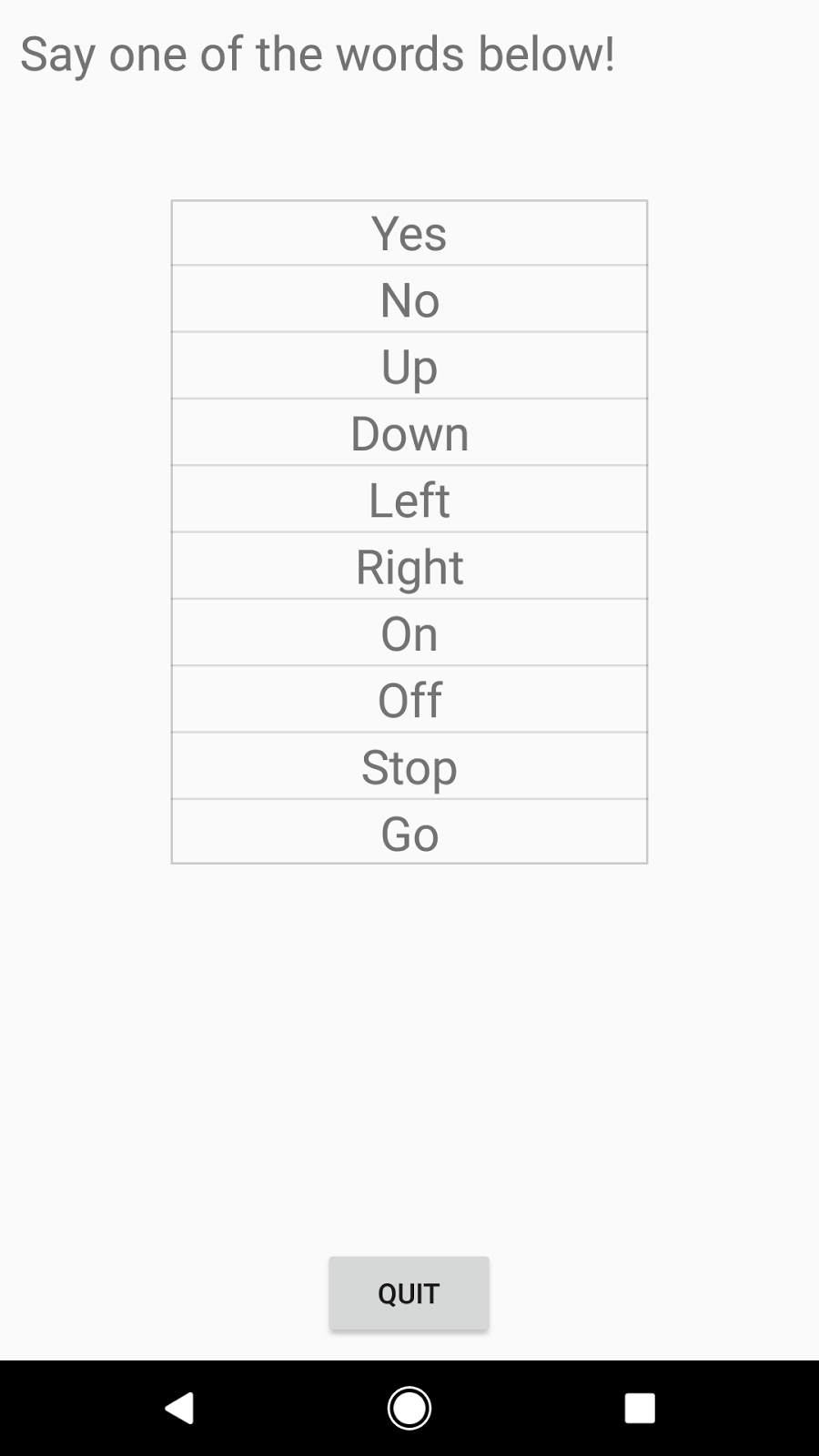
You can also learn how to train your own version of this model through the new audio recognition tutorial on TensorFlow.org. With the latest development version of the framework and a modern desktop machine, you can download the dataset and train the model in just a few hours. You’ll also see a wide variety of options to customize the neural network for different problems, and to make different latency, size, and accuracy tradeoffs to run on different platforms.
We are excited to see what new applications people are able to build with the help of this dataset and tutorial, so I hope you get a chance to dive in and start recognizing!
* The architecture this network is based on is described in Convolutional Neural Networks for Small-footprint Keyword Spotting, presented at Interspeech 2015.↩
Quick links
Other posts of interest
-

March 12, 2026
Protecting cities with AI-driven flash flood forecasting- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets
×
❮
❯
