Large-Scale Matrix Factorization on TPUs
April 8, 2022
Posted by Harsh Mehta, Software Engineer, Google Research
Quick links
Matrix factorization is one of the oldest, yet still widely used, techniques for learning how to recommend items such as songs or movies from user ratings. In its basic form, it approximates a large, sparse (i.e., mostly empty) matrix of user-item interactions with a product of two smaller, denser matrices representing learned item and user features. These dense matrices, in turn, can be used to recommend items to a user with which they haven't interacted before.
Despite its algorithmic simplicity, matrix factorization can still achieve competitive performance in recommender benchmarks. Alternating least squares (ALS), and especially its implicit variation, is a fundamental algorithm to learn the parameters of matrix factorization. ALS is known for its high efficiency because it scales linearly in the number of rows, columns and non-zeros. Hence, this algorithm is very well suited for large-scale challenges. But, for very large real-world matrix factorization datasets, a single machine implementation would not suffice, and so, it would require a large distributed system. Most of the distributed implementations of matrix factorization that employ ALS leverage off-the-shelf CPU devices, and rightfully so, due to the inherently sparse nature of the problem (the input matrix is mostly empty).
On the other hand, recent success of deep learning, which has exhibited growing computational capacity, has spurred a new wave of research and progress on hardware accelerators such as Tensor Processing Units (TPUs). TPUs afford domain specific hardware speedups, especially for use cases like deep learning, which involves a large number of dense matrix multiplications. In particular, they allow significant speedups for traditional data-parallel workloads, such as training models with Stochastic Gradient Descent (SGD) in SPMD (single program multiple data) fashion. The SPMD approach has gained popularity in computations like training neural networks with gradient descent algorithms, and can be used for both data-parallel and model-parallel computations, where we distribute parameters of the model across available devices. Nevertheless, while TPUs have been enormously attractive for methods based on SGD, it is not immediately clear if a high performance implementation of ALS, which requires a large number of distributed sparse matrix multiplies, can be developed for a large-scale cluster of TPU devices.
In “ALX: Large Scale Matrix Factorization on TPUs”, we explore a distributed ALS design that makes efficient use of the TPU architecture and can scale well to matrix factorization problems of the order of billions of rows and columns by scaling the number of available TPU cores. The approach we propose leverages a combination of model and data parallelism, where each TPU core both stores a portion of the embedding table and trains over a unique slice of data, grouped in mini-batches. In order to spur future research on large-scale matrix factorization methods and to illustrate the scalability properties of our own implementation, we also built and released a real world web link prediction dataset called WebGraph.
 |
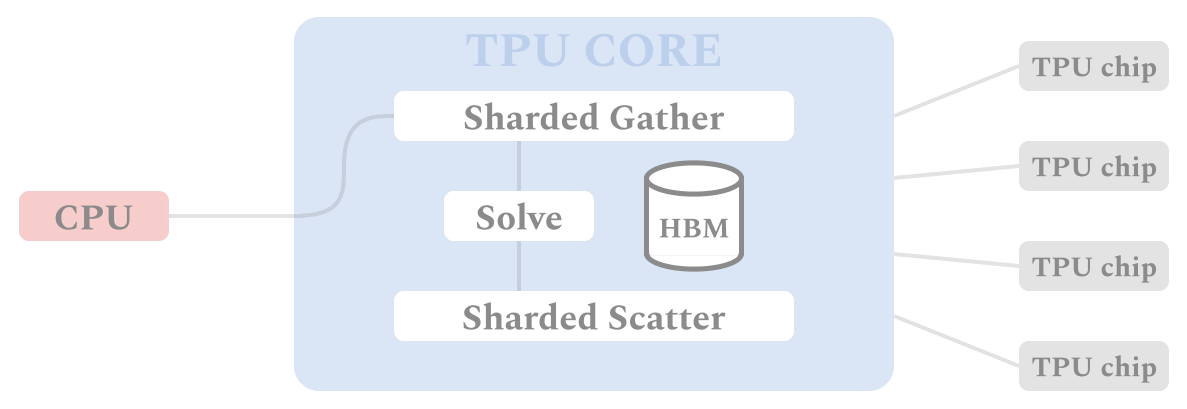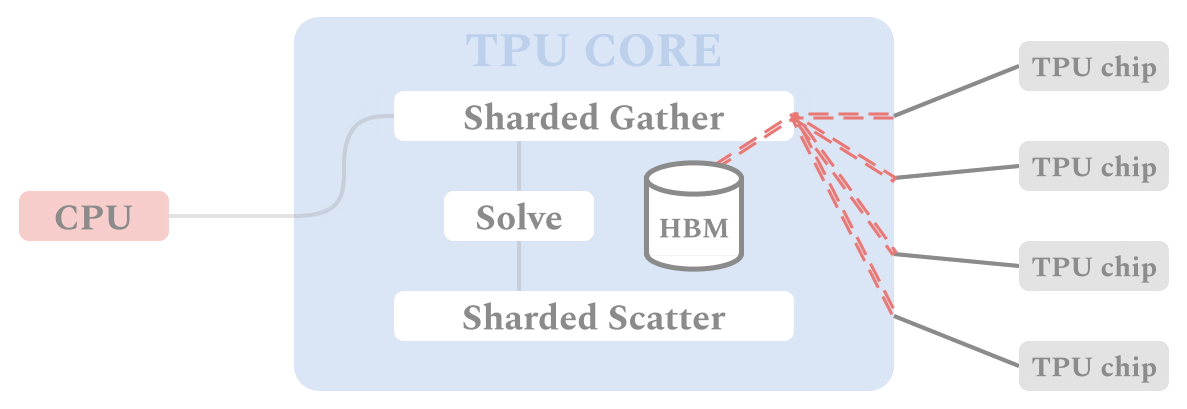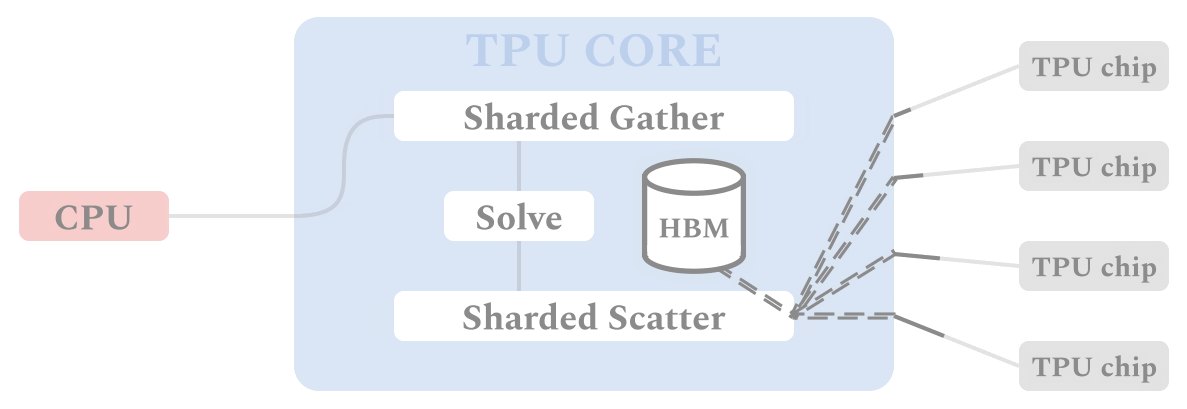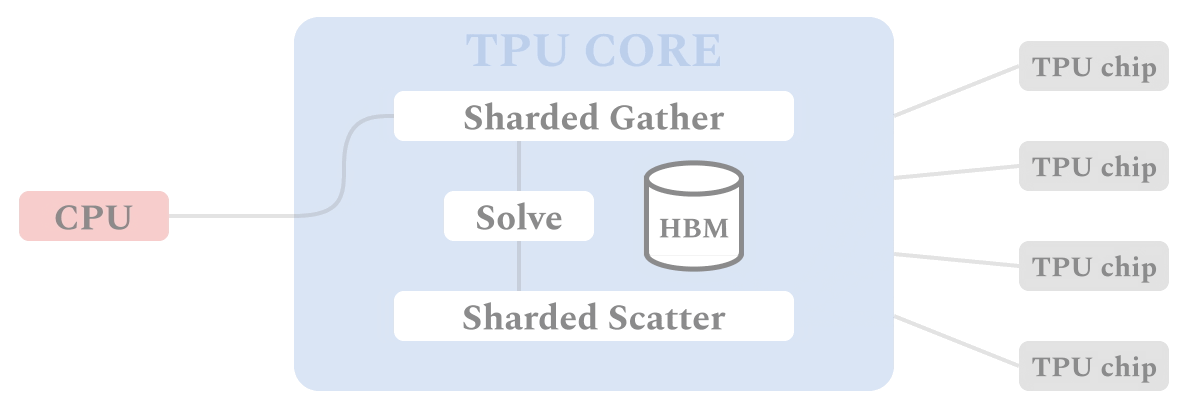
| The figure shows the flow of data and computation through the ALX framework on TPU devices. Similar to SGD-based training procedures, each TPU core performs identical computation for its own batch of data in SPMD fashion, which allows for synchronous computation in parallel on multiple TPU cores. Each TPU starts with gathering all the relevant item embeddings in the Sharded Gather stage. These materialized embeddings are used to solve for user embeddings which are scattered to the relevant shard of the embedding table in the Sharded Scatter stage. |
Dense Batching for Improved Efficiency
We designed ALX specifically for TPUs, exploiting unique properties of TPU architecture while overcoming a few interesting limitations. For instance, each TPU core has limited memory and restricts all tensors to have a static shape, but each example in a mini-batch can have a wildly varying number of items (i.e., inputs can be long and sparse). To resolve this, we break exceedingly long examples into multiple smaller examples of the same shape, a process called dense batching. More details about dense batching can be found in our paper.
 |
| Illustrating example of how sparse batches are densified to increase efficiency on TPUs. |
Uniform Sharding of Embedding Tables
With the batching problem solved, we next want to factorize a sparse matrix into two dense embedding matrices (e.g., user and item embeddings) such that the resulting dot product of embeddings approximate the original sparse matrix — this helps us infer predictions for all the positions from the original matrix, including those that were empty, which can be used to recommend items with which users haven’t interacted. Both the resulting embedding tables (W and H in the figure below) can potentially be too large to fit in a single TPU core, thus requiring a distributed training setup for most large-scale use cases.
Most previous attempts of distributed matrix factorization use a parameter server architecture where the model parameters are stored on highly available servers, and the training data is processed in parallel by workers that are solely responsible for the learning task. In our case, since each TPU core has identical compute and memory, it's wasteful to only use either memory for storing model parameters or compute for training. Thus, we designed our system such that each core is used to do both.
 |
| Illustrative example of factorizing a sparse matrix Y into two dense embedding matrices W and H. |
In ALX, we uniformly divide both embedding tables, thus fully exploiting both the size of distributed memory available and the dedicated low-latency interconnects between TPUs. This is highly efficient for very large embedding tables and results in good performance for distributed gather and scatter operations.
 |
| Uniform sharding of both embedding tables (W and H) across TPU cores (in blue). |
WebGraph
Since potential applications may involve very large data sets, scalability is potentially an important opportunity for advancement in matrix factorization. To that end, we also release a large real-world web link prediction dataset called WebGraph. This dataset can be easily modeled as a matrix factorization problem where rows and columns are source and destination links, respectively, and the task is to predict destination links from each source link. We use WebGraph to illustrate the scaling properties of ALX.
The WebGraph dataset was generated from a single crawl performed by CommonCrawl in 2021 where we strip everything and keep only the link->outlinks data. Since the performance of a factorization method depends on the properties of the underlying graph, we created six versions of WebGraph, each varying in the sparsity pattern and locale, to study how well ALS performs on each.
- To study locale-specific graphs, we filter based on two top level domains: ‘de’ and ‘in’, each producing a graph with an order of magnitude fewer nodes.
- These graphs can still have arbitrary sparsity patterns and dangling links. Thus we further filter the nodes in each graph to have a minimum of either 10 or 50 inlinks and outlinks.
For easy access, we have made these available as a Tensorflow Dataset package. For reference, the biggest version, WebGraph-sparse, has more than 365M nodes and 30B edges. We create and publish both training and testing splits for evaluation purposes.
Results
We carefully tune the system and quality parameters of ALX. Based on our observations related to precision and choice of linear solvers. We observed that by carefully selecting the precision for storage of the embedding tables (bfloat16) and for the input to the linear solvers (float32), we were able to halve the memory required for the embeddings while still avoiding problems arising from lower precision values during the solve stage. For our linear solvers, we selected conjugate gradients, which we found to be the fastest across the board on TPUs. We use embeddings of dimension 128 and train the model for 16 epochs. In our experience, hyperparameter tuning over both norm penalty (λ) and unobserved weight (α) has been indispensable for good recall metrics as shown in the table below.
 |
| Results obtained by running ALX on all versions of WebGraph dataset. Recall values of 1.0 denote perfect recall. |
Scaling Analysis
Since the input data are processed in parallel across TPU cores, increasing the number of cores decreases training time, ideally in a linear fashion. But at the same time, a larger number of cores requires more network communication (due to the sharded embedding tables). Thanks to high-speed interconnects, this overhead can be negligible for a small number of cores, but as the number of cores increases, the overhead eventually slows down the ideal linear scaling.
In order to confirm our hypothesis, we analyze scaling properties of the four biggest WebGraph variants in terms of training time as we increase the number of available TPU cores. As shown below, even empirically, we do observe the predicted linear decrease in training time up to a sweet spot, after which the network overhead slows the decline.
 |
| Scaling analysis of running time as the number of TPU cores are increased. Each figure plots the time taken to train for one epoch in seconds. |
Conclusion
For easy access and reproducibility, the ALX code is open-sourced and can be easily run on Google Cloud. In fact, we illustrate that a sparse matrix like WebGraph-dense of size 135M x 135M (with 22B edges) can be factorized in a colab connected to 8 TPU cores in less than a day. We have designed the ALX framework with scalability in mind. With 256 TPU cores, one epoch of the largest WebGraph variant, WebGraph-sparse (365M x 365M sparse matrix) takes around 20 minutes to finish (5.5 hours for the whole training run). The final model has around 100B parameters. We hope that the ALX and WebGraph will be useful to both researchers and practitioners working in these fields. The code for ALX can be found here on github!
Acknowledgements
The core team includes Steffen Rendle, Walid Krichene and Li Zhang. We thank many Google colleagues for helping at various stages of this project. In particular, we are grateful to the JAX team for numerous discussions, especially James Bradbury and Skye Wanderman-Milne; Blake Hechtman for help with XLA and Rasmus Larsen for useful discussions about performance of linear solvers on TPUs. Finally, we're also grateful to Nicolas Mayoraz, John Anderson, and Fernando Pereira for providing useful feedback.
Quick links
Other posts of interest
-

July 29, 2025
Simulating large systems with Regression Language Models- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets ·
- Software Systems & Engineering
-

July 17, 2025
Android Earthquake Alerts: A global system for early warning- Data Mining & Modeling ·
- General Science ·
- Mobile Systems
-

June 30, 2025
How we created HOV-specific ETAs in Google Maps- Algorithms & Theory ·
- Data Mining & Modeling ·
- Machine Intelligence