Introducing the Next Generation of On-Device Vision Models: MobileNetV3 and MobileNetEdgeTPU
November 13, 2019
Posted by Andrew Howard and Suyog Gupta, Software Engineers, Google Research
Quick links
On-device machine learning (ML) is an essential component in enabling privacy-preserving, always-available and responsive intelligence. This need to bring on-device machine learning to compute and power-limited devices has spurred the development of algorithmically-efficient neural network models and hardware capable of performing billions of math operations per second, while consuming only a few milliwatts of power. The recently launched Google Pixel 4 exemplifies this trend, and ships with the Pixel Neural Core that contains an instantiation of the Edge TPU architecture, Google’s machine learning accelerator for edge computing devices, and powers Pixel 4 experiences such as face unlock, a faster Google Assistant and unique camera features. Similarly, algorithms, such as MobileNets, have been critical for the success of on-device ML by providing compact and efficient neural network models for mobile vision applications.
Today we are pleased to announce the release of source code and checkpoints for MobileNetV3 and the Pixel 4 Edge TPU-optimized counterpart MobileNetEdgeTPU model. These models are the culmination of the latest advances in hardware-aware AutoML techniques as well as several advances in architecture design. On mobile CPUs, MobileNetV3 is twice as fast as MobileNetV2 with equivalent accuracy, and advances the state-of-the-art for mobile computer vision networks. On the Pixel 4 Edge TPU hardware accelerator, the MobileNetEdgeTPU model pushes the boundary further by improving model accuracy while simultaneously reducing the runtime and power consumption.
Building MobileNetV3
In contrast with the hand-designed previous version of MobileNet, MobileNetV3 relies on AutoML to find the best possible architecture in a search space friendly to mobile computer vision tasks. To most effectively exploit the search space we deploy two techniques in sequence — MnasNet and NetAdapt. First, we search for a coarse architecture using MnasNet, which uses reinforcement learning to select the optimal configuration from a discrete set of choices. Then we fine-tune the architecture using NetAdapt, a complementary technique that trims under-utilized activation channels in small decrements. To provide the best possible performance under different conditions we have produced both large and small models.
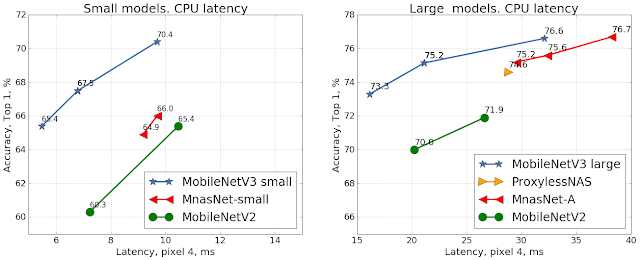
 |
| Comparison of accuracy vs. latency for mobile models on the ImageNet classification task using the Google Pixel 4 CPU. |
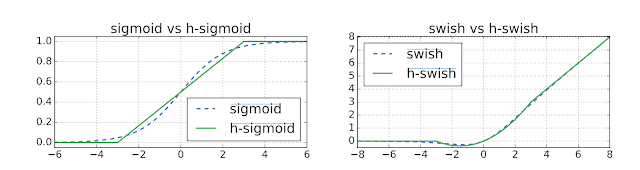
The MobileNetV3 search space builds on multiple recent advances in architecture design that we adapt for the mobile environment. First, we introduce a new activation function called hard-swish (h-swish) which is based on the Swish nonlinearity function. The critical drawback of the Swish function is that it is very inefficient to compute on mobile hardware. So, instead we use an approximation that can be efficiently expressed as a product of two piecewise linear functions.

Combining h-swish plus mobile-friendly squeeze-and-excitation with a modified version of the inverted bottleneck structure introduced in MobileNetV2 yielded a new building block for MobileNetV3.
 |
| MobileNetV3 extends the MobileNetV2 inverted bottleneck structure by adding h-swish and mobile friendly squeeze-and-excitation as searchable options. |
- Size of expansion layer
- Degree of squeeze-excite compression
- Choice of activation function: h-swish or ReLU
- Number of layers for each resolution block

In addition to classification models, we also introduced MobileNetV3 object detection models, which reduced detection latency by 25% relative to MobileNetV2 at the same accuracy for the COCO dataset.
In order to optimize MobileNetV3 for efficient semantic segmentation, we introduced a low latency segmentation decoder called Lite Reduced Atrous Spatial Pyramid Pooling (LR-SPP). This new decoder contains three branches, one for low resolution semantic features, one for higher resolution details, and one for light-weight attention. The combination of LR-SPP and MobileNetV3 reduces the latency by over 35% on the high resolution Cityscapes Dataset.
MobileNet for Edge TPUs
The Edge TPU in Pixel 4 is similar in architecture to the Edge TPU in the Coral line of products, but customized to meet the requirements of key camera features in Pixel 4. The accelerator-aware AutoML approach substantially reduces the manual process involved in designing and optimizing neural networks for hardware accelerators. Crafting the neural architecture search space is an important part of this approach and centers around the inclusion of neural network operations that are known to improve hardware utilization. While operations such as squeeze-and-excite and swish non-linearity have been shown to be essential in building compact and fast CPU models, these operations tend to perform suboptimally on Edge TPU and hence are excluded from the search space. The minimalistic variants of MobileNetV3 also forgo the use of these operations (i.e., squeeze-and-excite, swish, and 5x5 convolutions) to allow easier portability to a variety of other hardware accelerators such as DSPs and GPUs.
The neural network architecture search, incentivized to jointly optimize the model accuracy and Edge TPU latency, produces the MobileNetEdgeTPU model that achieves lower latency for a fixed accuracy (or higher accuracy for a fixed latency) than existing mobile models such as MobileNetV2 and minimalistic MobileNetV3. Compared with the EfficientNet-EdgeTPU model (optimized for the Edge TPU in Coral), these models are designed to run at a much lower latency on Pixel 4, albeit at the cost of some loss in accuracy.
Although reducing the model’s power consumption was not a part of the search objective, the lower latency of the MobileNetEdgeTPU models also helps reduce the average Edge TPU power use. The MobileNetEdgeTPU model consumes less than 50% the power of the minimalistic MobileNetV3 model at comparable accuracy.
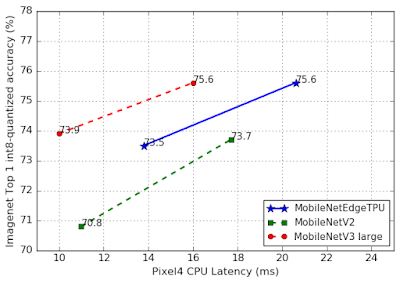
 |
| Left: Comparison of the accuracy on the ImageNet classification task between MobileNetEdgeTPU and other image classification networks designed for mobile when running on Pixel4 Edge TPU. MobileNetEdgeTPU achieves higher accuracy and lower latency compared with other models. Right: Average Edge TPU power in Watts for different classification models running at 30 frames per second (fps). |
The MobileNetEdgeTPU classification model also serves as an effective feature extractor for object detection tasks. Compared with MobileNetV2 based detection models, MobileNetEdgeTPU models offer a significant improvement in model quality (measured as the mean average precision; mAP) on the COCO14 minival dataset at comparable runtimes on the Edge TPU. The MobileNetEdgeTPU detection model has a latency of 6.6ms and achieves mAP score of 24.3, while MobileNetV2-based detection models achieve an mAP of 22 and takes 6.8ms per inference.
The Need for Hardware-Aware Models
While the results shown above highlight the power, performance, and quality benefits of MobileNetEdgeTPU models, it is important to note that the improvements arise due to the fact that these models have been customized to run on the Edge TPU accelerator.
MobileNetEdgeTPU when running on a mobile CPU delivers inferior performance compared with the models that have been tuned specifically for mobile CPUs (MobileNetV3). MobileNetEdgeTPU models perform a much greater number of operations, and so, it is not surprising that they run slower on mobile CPUs, which exhibit a more linear relationship between a model’s compute requirements and the runtime.
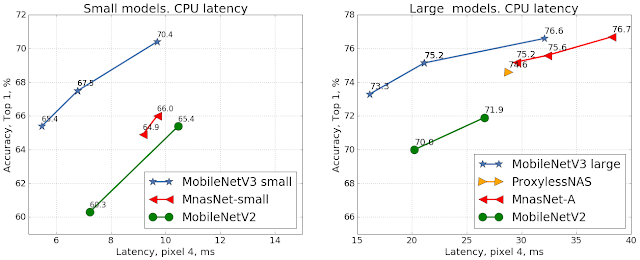
 |
| MobileNetV3 is still the best performing network when using mobile CPU as the deployment target. |
The MobileNetV3 and MobileNetEdgeTPU code, as well as both floating point and quantized checkpoints for ImageNet classification, are available at the MobileNet github page. Open source implementation for MobileNetV3 and MobileNetEdgeTPU object detection is available in the Tensorflow Object Detection API. Open source implementation for MobileNetV3 semantic segmentation is available in TensorFlow through DeepLab.
Acknowledgements:
This work is made possible through a collaboration spanning several teams across Google. We’d like to acknowledge contributions from Berkin Akin, Okan Arikan, Gabriel Bender, Bo Chen, Liang-Chieh Chen, Grace Chu, Eddy Hsu, John Joseph, Pieter-jan Kindermans, Quoc Le, Owen Lin, Hanxiao Liu, Yun Long, Ravi Narayanaswami, Ruoming Pang, Mark Sandler, Mingxing Tan, Vijay Vasudevan, Weijun Wang, Dong Hyuk Woo, Dmitry Kalenichenko, Yunyang Xiong, Yukun Zhu and support from Hartwig Adam, Blaise Agüera y Arcas, Chidu Krishnan and Steve Molloy.
Quick links
Other posts of interest
-

February 17, 2026
Teaching AI to read a map- Machine Perception ·
- Open Source Models & Datasets
-
February 11, 2026
Scheduling in a changing world: Maximizing throughput with time-varying capacity- Algorithms & Theory
-

February 4, 2026
Sequential Attention: Making AI models leaner and faster without sacrificing accuracy- Algorithms & Theory
×
❮
❯