Introducing the Inclusive Images Competition
September 6, 2018
Posted by Tulsee Doshi, Product Manager, Google AI
Quick links
The release of large, publicly available image datasets, such as ImageNet, Open Images and Conceptual Captions, has been one of the factors driving the tremendous progress in the field of computer vision. While these datasets are a necessary and critical part of developing useful machine learning (ML) models, some open source data sets have been found to be geographically skewed based on how they were collected. Because the shape of a dataset informs what an ML model learns, such skew may cause the research community to inadvertently develop models that may perform less well on images drawn from geographical regions under-represented in those data sets. For example, the images below show one standard open-source image classifier trained on the Open Images dataset that does not properly apply “wedding” related labels to images of wedding traditions from different parts of the world.
 |
| Wedding photographs (donated by Googlers), labeled by a classifier trained on the Open Images dataset. The classifier’s label predictions are recorded below each image. |
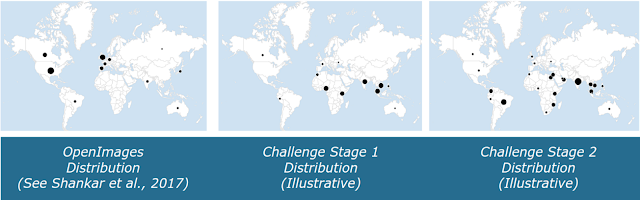
In support of this effort and to spur further progress in developing inclusive ML models, we are happy to announce the Inclusive Images Competition on Kaggle. Developed in partnership with the Conference on Neural Information Processing Systems Competition Track, this competition challenges you to use Open Images, a large, multilabel, publicly-available image classification dataset that is majority-sampled from North America and Europe, to train a model that will be evaluated on images collected from a different set of geographic regions across the globe.
 |
| The three geographical distributions of data in this competition. Competitors will train their models on Open Images, a widely used publicly available benchmark dataset for image classification which happens to be drawn mostly from North America and Western Europe. Models are then evaluated first on Challenge Stage 1 and finally on Challenge Stage 2, each with different un-revealed geographical distributions. In this way, models are stress-tested for their ability to operate inclusively beyond their training data. |
 |
| Examples of labeled images from the challenge dataset. Clockwise from top left, image donation by Peter Tester, Mukesh Kumhar, HeeYoung Moon, Sudipta Pramanik, jaturan amnatbuddee, Tomi Familoni and Anu Subhi |
The results of the competition will be presented at the 2018 Conference on Neural Information Processing Systems, and we will provide top-ranking competitors with travel grants to attend the conference (see this page for full details). We look forward to being part of the community's development of more inclusive, global image classification algorithms!
Acknowledgements
We would like to thank the following individuals for making the Inclusive Image Competition and dataset possible: James Atwood, Pallavi Baljekar, Parker Barnes, Anurag Batra, Eric Breck, Peggy Chi, Tulsee Doshi, Julia Elliott, Gursheesh Kour, Akshay Gaur, Yoni Halpern, Henry Jicha, Matthew Long, Jigyasa Saxena, Richa Singh and D. Sculley.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
×
❮
❯