Introducing the Google Universal Image Embedding Challenge
August 4, 2022
Posted by Bingyi Cao, Software Engineer, Google Research, and Mário Lipovský, Software Engineer, Google Lens
Quick links
Computer vision models see daily application for a wide variety of tasks, ranging from object recognition to image-based 3D object reconstruction. One challenging type of computer vision problem is instance-level recognition (ILR) — given an image of an object, the task is to not only determine the generic category of an object (e.g., an arch), but also the specific instance of the object (”Arc de Triomphe de l'Étoile, Paris, France”).
Previously, ILR was tackled using deep learning approaches. First, a large set of images was collected. Then a deep model was trained to embed each image into a high-dimensional space where similar images have similar representations. Finally, the representation was used to solve the ILR tasks related to classification (e.g., with a shallow classifier trained on top of the embedding) or retrieval (e.g., with a nearest neighbor search in the embedding space).
Since there are many different object domains in the world, e.g., landmarks, products, or artworks, capturing all of them in a single dataset and training a model that can distinguish between them is quite a challenging task. To decrease the complexity of the problem to a manageable level, the focus of research so far has been to solve ILR for a single domain at a time. To advance the research in this area, we hosted multiple Kaggle competitions focused on the recognition and retrieval of landmark images. In 2020, Amazon joined the effort and we moved beyond the landmark domain and expanded to the domains of artwork and product instance recognition. The next step is to generalize the ILR task to multiple domains.
To this end, we’re excited to announce the Google Universal Image Embedding Challenge, hosted by Kaggle in collaboration with Google Research and Google Lens. In this challenge, we ask participants to build a single universal image embedding model capable of representing objects from multiple domains at the instance level. We believe that this is the key for real-world visual search applications, such as augmenting cultural exhibits in a museum, organizing photo collections, visual commerce and more.
 |
| Images1 of object instances from some domains represented in the dataset: apparel and accessories, furniture and home goods, toys, cars, landmarks, dishes, artwork and illustrations. |
Degrees of Variation in Different Domains
To represent objects from a large number of domains, we require one model to learn many domain-specific subtasks (e.g., filtering different kinds of noise or focusing on a specific detail), which can only be learned from a semantically and visually diverse collection of images. Addressing each degree of variation proposes a new challenge for both image collection and model training.
The first sort of variation comes from the fact that while some domains contain unique objects in the world (landmarks, artwork, etc.), others contain objects that may have many copies (clothing, furniture, packaged goods, food, etc.). Because a landmark is always placed at the same location, the surrounding context may be useful for recognition. In contrast, a product, say a phone, even of a specific model and color, may have millions of physical instances and thus appear in many surrounding contexts.
Another challenge comes from the fact that a single object may appear different depending on the point of view, lighting conditions, occlusion or deformations (e.g., a dress worn on a person may look very different than on a hanger). In order for a model to learn invariance to all of these visual modes, all of them should be captured by the training data.
Additionally, similarities between objects differ across domains. For example, in order for a representation to be useful in the product domain, it must be able to distinguish very fine-grained details between similarly looking products belonging to two different brands. In the domain of food, however, the same dish (e.g., spaghetti bolognese) cooked by two chefs may look quite different, but the ability of the model to distinguish spaghetti bolognese from other dishes may be sufficient for the model to be useful. Additionally, a vision model of high quality should assign similar representations to more visually similar renditions of a dish.
| Domain | Landmark | Apparel | ||||
| Image |
.jpg)
|
.jpg)
|
||||
| Instance Name | Empire State Building2 | Cycling jerseys with Android logo3 | ||||
| Which physical objects belong to the instance class? | Single instance in the world | Many physical instances; may differ in size or pattern (e.g., a patterned cloth cut differently) | ||||
| What are the possible views of the object? | Appearance variation only based on capture conditions (e.g., illumination or viewpoint); limited number of common external views; possibility of many internal views | Deformable appearance (e.g., worn or not); limited number of common views: front, back, side | ||||
| What are the surroundings and are they useful for recognition? | Surrounding context does not vary much other than daily and yearly cycles; may be useful for verifying the object of interest | Surrounding context can change dramatically due to difference in environment, additional pieces of clothing, or accessories partially occluding clothing of interest (e.g., a jacket or a scarf) | ||||
| What may be tricky cases that do not belong to the instance class? | Replicas of landmarks (e.g., Eiffel Tower in Las Vegas), souvenirs | Same piece of apparel of different material or different color; visually very similar pieces with a small distinguishing detail (e.g., a small brand logo); different pieces of apparel worn by the same model | ||||
| Variation among domains for landmark and apparel examples. |
Learning Multi-domain Representations
After a collection of images covering a variety of domains is created, the next challenge is to train a single, universal model. Some features and tasks, such as representing color, are useful across many domains, and thus adding training data from any domain will likely help the model improve at distinguishing colors. Other features may be more specific to selected domains, thus adding more training data from other domains may deteriorate the model’s performance. For example, while for 2D artwork it may be very useful for the model to learn to find near duplicates, this may deteriorate the performance on clothing, where deformed and occluded instances need to be recognized.
The large variety of possible input objects and tasks that need to be learned require novel approaches for selecting, augmenting, cleaning and weighing the training data. New approaches for model training and tuning, and even novel architectures may be required.
Universal Image Embedding Challenge
To help motivate the research community to address these challenges, we are hosting the Google Universal Image Embedding Challenge. The challenge was launched on Kaggle in July and will be open until October, with cash prizes totaling $50k. The winning teams will be invited to present their methods at the Instance-Level Recognition workshop at ECCV 2022.
Participants will be evaluated on a retrieval task on a dataset of ~5,000 test query images and ~200,000 index images, from which similar images are retrieved. In contrast to ImageNet, which includes categorical labels, the images in this dataset are labeled at the instance level.
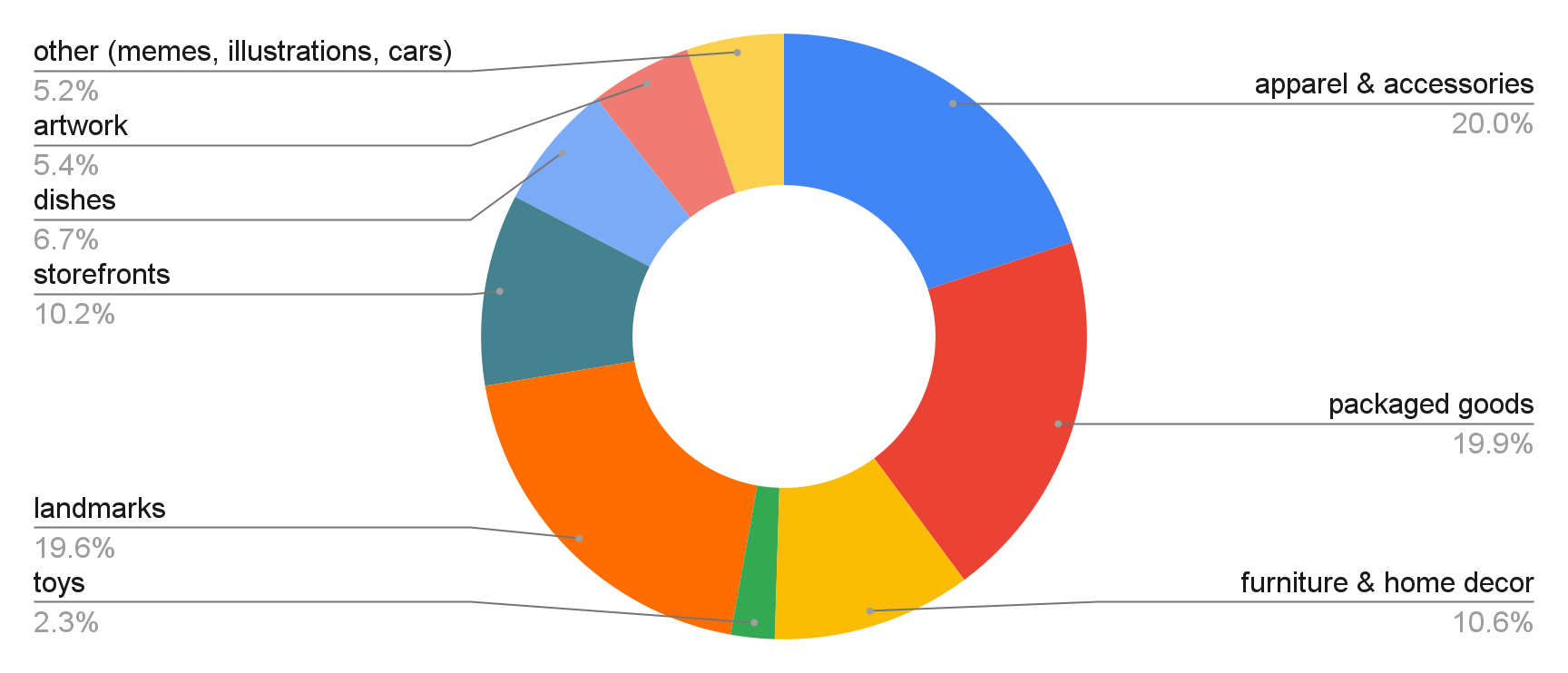
The evaluation data for the challenge is composed of images from the following domains: apparel and accessories, packaged goods, furniture and home goods, toys, cars, landmarks, storefronts, dishes, artwork, memes and illustrations.
 |
| Distribution of domains of query images. |
We invite researchers and machine learning enthusiasts to participate in the Google Universal Image Embedding Challenge and join the Instance-Level Recognition workshop at ECCV 2022. We hope the challenge and the workshop will advance state-of-the-art techniques on multi-domain representations.
Acknowledgement
The core contributors to this project are Andre Araujo, Boris Bluntschli, Bingyi Cao, Kaifeng Chen, Mário Lipovský, Grzegorz Makosa, Mojtaba Seyedhosseini and Pelin Dogan Schönberger. We would like to thank Sohier Dane, Will Cukierski and Maggie Demkin for their help organizing the Kaggle challenge, as well as our ECCV workshop co-organizers Tobias Weyand, Bohyung Han, Shih-Fu Chang, Ondrej Chum, Torsten Sattler, Giorgos Tolias, Xu Zhang, Noa Garcia, Guangxing Han, Pradeep Natarajan and Sanqiang Zhao. Furthermore we are thankful to Igor Bonaci, Tom Duerig, Vittorio Ferrari, Victor Gomes, Futang Peng and Howard Zhou who gave us feedback, ideas and support at various points of this project.
1 Image credits: Chris Schrier, CC-BY; Petri Krohn, GNU Free Documentation License; Drazen Nesic, CC0; Marco Verch Professional Photographer, CCBY; Grendelkhan, CCBY; Bobby Mikul, CC0; Vincent Van Gogh, CC0; pxhere.com, CC0; Smart Home Perfected, CC-BY. ↩
2 Image credit: Bobby Mikul, CC0. ↩
3 Image credit: Chris Schrier, CC-BY. ↩
-
Labels:
- Machine Perception
- Programs
Quick links
Other posts of interest
-

February 17, 2026
Teaching AI to read a map- Machine Perception ·
- Open Source Models & Datasets
-

January 22, 2026
Small models, big results: Achieving superior intent extraction through decomposition- Generative AI ·
- Machine Perception ·
- Mobile Systems
-

October 23, 2025
Google Earth AI: Unlocking geospatial insights with foundation models and cross-modal reasoning- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Machine Perception
.jpg)
.jpg)