Introducing the CVPR 2018 On-Device Visual Intelligence Challenge
April 20, 2018
Posted by Bo Chen, Software Engineer and Jeffrey M. Gilbert, Member of Technical Staff, Google Research
Quick links
Over the past year, there have been exciting innovations in the design of deep networks for vision applications on mobile devices, such as the MobileNet model family and integer quantization. Many of these innovations have been driven by performance metrics that focus on meaningful user experiences in real-world mobile applications, requiring inference to be both low-latency and accurate. While the accuracy of a deep network model can be conveniently estimated with well established benchmarks in the computer vision community, latency is surprisingly difficult to measure and no uniform metric has been established. This lack of measurement platforms and uniform metrics have hampered the development of performant mobile applications.
Today, we are happy to announce the On-device Visual Intelligence Challenge (OVIC), part of the Low-Power Image Recognition Challenge Workshop at the 2018 Computer Vision and Pattern Recognition conference (CVPR2018). A collaboration with Purdue University, the University of North Carolina and IEEE, OVIC is a public competition for real-time image classification that uses state-of-the-art Google technology to significantly lower the barrier to entry for mobile development. OVIC provides two key features to catalyze innovation: a unified latency metric and an evaluation platform.
A Unified Metric
OVIC focuses on the establishment of a unified metric aligned directly with accurate and performant operation on mobile devices. The metric is defined as the number of correct classifications within a specified per-image average time limit of 33ms. This latency limit allows every frame in a live 30 frames-per-second video to be processed, thus providing a seamless user experience1. Prior to OVIC, it was tricky to enforce such a limit due to the difficulty in accurately and uniformly measuring latency as would be experienced in real-world applications on real-world devices. Without a repeatable mobile development platform, researchers have relied primarily on approximate metrics for latency that are convenient to compute, such as the number of multiply-accumulate operations (MACs). The intuition is that multiply-accumulate constitutes the most time-consuming operation in a deep neural network, so their count should be indicative of the overall latency. However, these metrics are often poor predictors of on-device latency due to many aspects of the models that can impact the average latency of each MAC in typical implementations.
 |
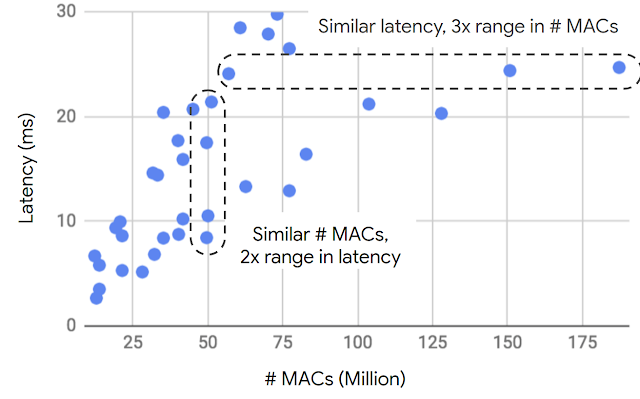
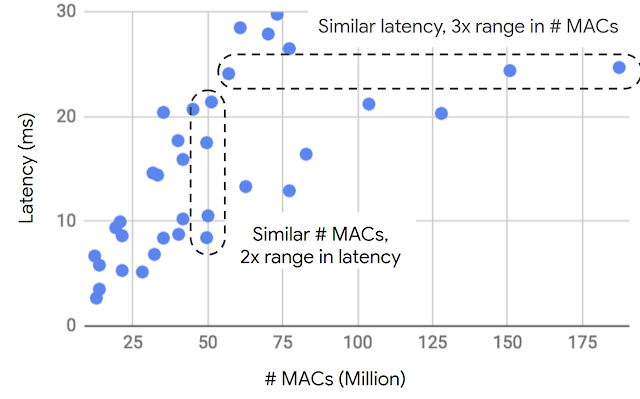
| Even though the number of multiply-accumulate operations (# MACs) is the most commonly used metric to approximate on-device latency, it is a poor predictor of latency. Using data from various quantized and floating point MobileNet V1 and V2 based models, this graph plots on-device latency on a common reference device versus the number of MACs. It is clear that models with similar latency can have very different MACs, and vice versa. |
An Evaluation Platform
As mentioned above, a primary issue with latency is that it has previously been challenging to measure reliably and repeatably, due to variations in implementation, running environment and hardware architectures. Recent successes in mobile development overcome these challenges with the help of a convenient mobile development platform, including optimized kernels for mobile CPUs, light-weight portable model formats, increasingly capable mobile devices, and more. However, these various platforms have traditionally required resources and development capabilities that are only available to larger universities and industry.
With that in mind, we are releasing OVIC’s evaluation platform that includes a number of components designed to make mobile development and evaluations that can be replicated and compared accessible to the broader research community:
- TOCO compiler for optimizing TensorFlow models for efficient inference
- TensorFlow Lite inference engine for mobile deployment
- A benchmarking SDK that can be run locally on any Android phone
- Sample models to showcase successful mobile architectures that run inference in floating-point and quantized modes
- Google’s benchmarking tool for reliable latency measurements on specific Pixel phones (available to registered contestants).
With OVIC, we encourage the entire research community to improve the classification performance of low-latency high-accuracy models towards new frontiers, as shown in the following graphic.
 |
| Sampling of current MobileNet mobile models illustrating the tradeoff between increased accuracy and reduced latency. |
Acknowledgements
We would like to acknowledge our core contributors Achille Brighton, Alec Go, Andrew Howard, Hartwig Adam, Mark Sandler and Xiao Zhang. We would also like to acknowledge our external collaborators Alex Berg and Yung-Hsiang Lu. We give special thanks to Andre Hentz, Andrew Selle, Benoit Jacob, Brad Krueger, Dmitry Kalenichenko, Megan Cummins, Pete Warden, Rajat Monga, Shiyu Hu and Yicheng Fan.
1 Alternatively the same metric could encourage even lower power operation by only processing a subset of the images in the input stream.↩
Quick links
Other posts of interest
-

February 17, 2026
Teaching AI to read a map- Machine Perception ·
- Open Source Models & Datasets
-

January 22, 2026
Small models, big results: Achieving superior intent extraction through decomposition- Generative AI ·
- Machine Perception ·
- Mobile Systems
-

January 13, 2026
Hard-braking events as indicators of road segment crash risk- Algorithms & Theory ·
- Product
×
❮
❯