Introducing PlaNet: A Deep Planning Network for Reinforcement Learning
February 15, 2019
Posted by Danijar Hafner, Student Researcher, Google AI
Quick links
Research into how artificial agents can improve their decisions over time is progressing rapidly via reinforcement learning (RL). For this technique, an agent observes a stream of sensory inputs (e.g. camera images) while choosing actions (e.g. motor commands), and sometimes receives a reward for achieving a specified goal. Model-free approaches to RL aim to directly predict good actions from the sensory observations, enabling DeepMind's DQN to play Atari and other agents to control robots. However, this blackbox approach often requires several weeks of simulated interaction to learn through trial and error, limiting its usefulness in practice.
Model-based RL, in contrast, attempts to have agents learn how the world behaves in general. Instead of directly mapping observations to actions, this allows an agent to explicitly plan ahead, to more carefully select actions by "imagining" their long-term outcomes. Model-based approaches have achieved substantial successes, including AlphaGo, which imagines taking sequences of moves on a fictitious board with the known rules of the game. However, to leverage planning in unknown environments (such as controlling a robot given only pixels as input), the agent must learn the rules or dynamics from experience. Because such dynamics models in principle allow for higher efficiency and natural multi-task learning, creating models that are accurate enough for successful planning is a long-standing goal of RL.
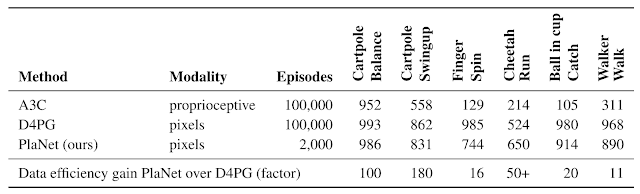
To spur progress on this research challenge and in collaboration with DeepMind, we present the Deep Planning Network (PlaNet) agent, which learns a world model from image inputs only and successfully leverages it for planning. PlaNet solves a variety of image-based control tasks, competing with advanced model-free agents in terms of final performance while being 5000% more data efficient on average. We are additionally releasing the source code for the research community to build upon.
| The PlaNet agent learning to solve a variety of continuous control tasks from images in 2000 attempts. Previous agents that do not learn a model of the environment often require 50 times as many attempts to reach comparable performance. |
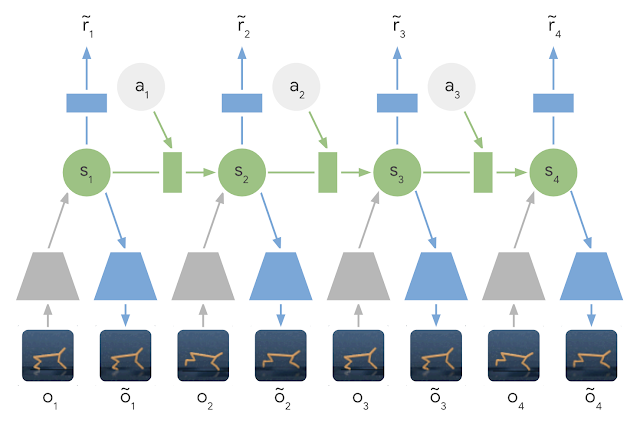
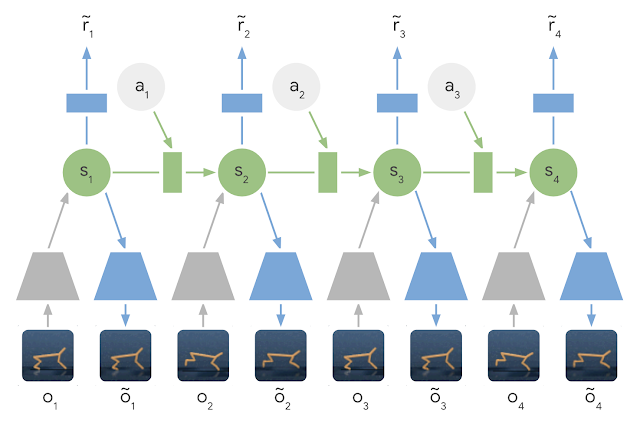
In short, PlaNet learns a dynamics model given image inputs and efficiently plans with it to gather new experience. In contrast to previous methods that plan over images, we rely on a compact sequence of hidden or latent states. This is called a latent dynamics model: instead of directly predicting from one image to the next image, we predict the latent state forward. The image and reward at each step is then generated from the corresponding latent state. By compressing the images in this way, the agent can automatically learn more abstract representations, such as positions and velocities of objects, making it easier to predict forward without having to generate images along the way.
 |
| Learned Latent Dynamics Model: In a latent dynamics model, the information of the input images is integrated into the hidden states (green) using the encoder network (grey trapezoids). The hidden state is then projected forward in time to predict future images (blue trapezoids) and rewards (blue rectangle). |
- A Recurrent State Space Model: A latent dynamics model with both deterministic and stochastic components, allowing to predict a variety of possible futures as needed for robust planning, while remembering information over many time steps. Our experiments indicate both components to be crucial for high planning performance.
- A Latent Overshooting Objective: We generalize the standard training objective for latent dynamics models to train multi-step predictions, by enforcing consistency between one-step and multi-step predictions in latent space. This yields a fast and effective objective that improves long-term predictions and is compatible with any latent sequence model.
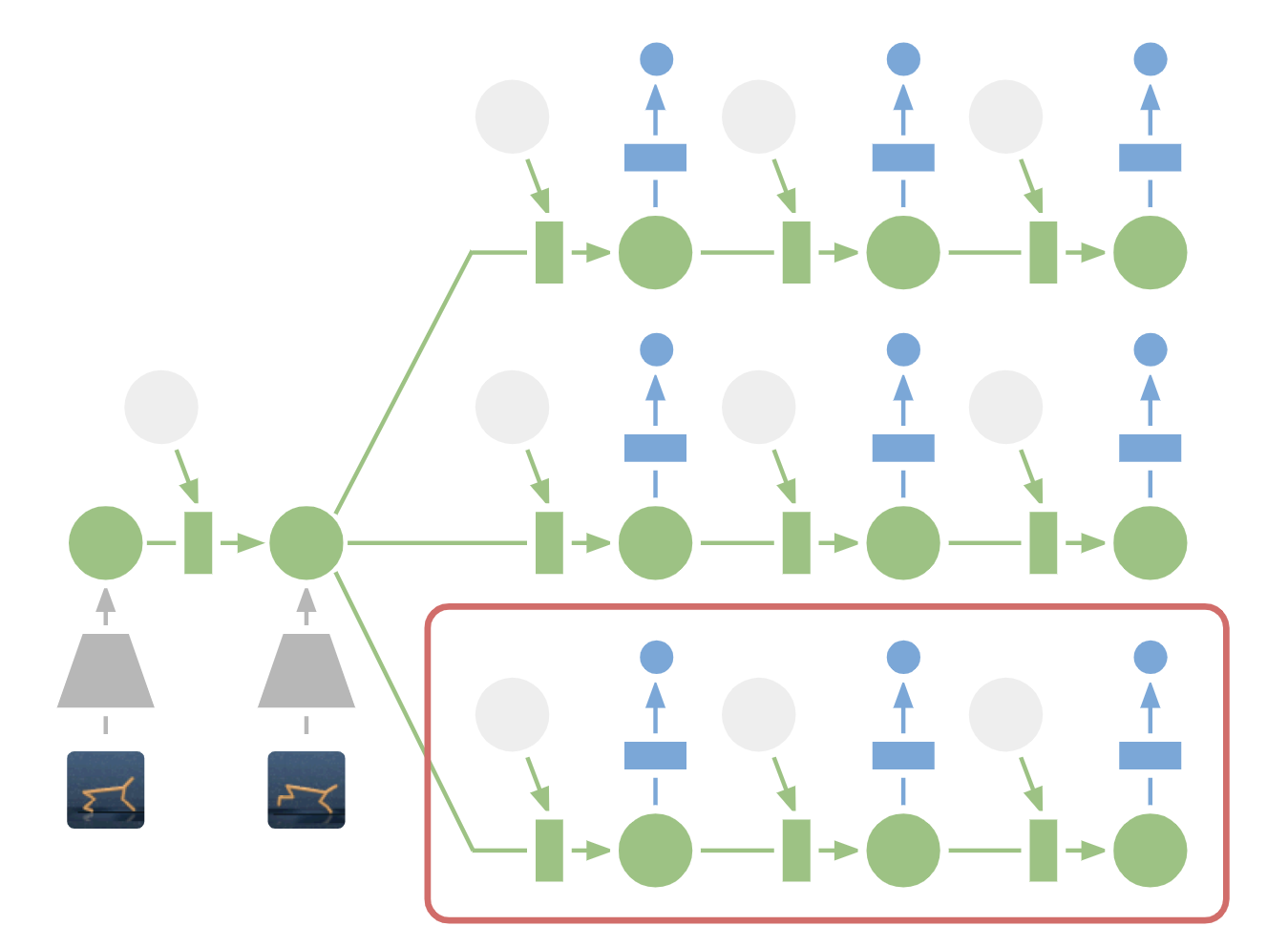 |
| Planning in Latent Space: For planning, we encode past images (gray trapezoid) into the current hidden state (green). From there, we efficiently predict future rewards for multiple action sequences. Note how the expensive image decoder (blue trapezoid) from the previous figure is gone. We then execute the first action of the best sequence found (red box). |
PlaNet vs. Model-Free Methods
We evaluate PlaNet on continuous control tasks. The agent is only given image observations and rewards. We consider tasks that pose a variety of different challenges:
- A cartpole swing-up task, with a fixed camera, so the cart can move out of sight. The agent thus must absorb and remember information over multiple frames.
- A finger spin task that requires predicting two separate objects, as well as the interactions between them.
- A cheetah running task that includes contacts with the ground that are difficult to predict precisely, calling for a model that can predict multiple possible futures.
- A cup task, which only provides a sparse reward signal once a ball is caught. This demands accurate predictions far into the future to plan a precise sequence of actions.
- A walker task, in which a simulated robot starts off by lying on the ground, and must first learn to stand up and then walk.
 |
| PlaNet agents trained on a variety of image-based control tasks. The animation shows the input images as the agent is solving the tasks. The tasks pose different challenges: partial observability, contacts with the ground, sparse rewards for catching a ball, and controlling a challenging bipedal robot. |
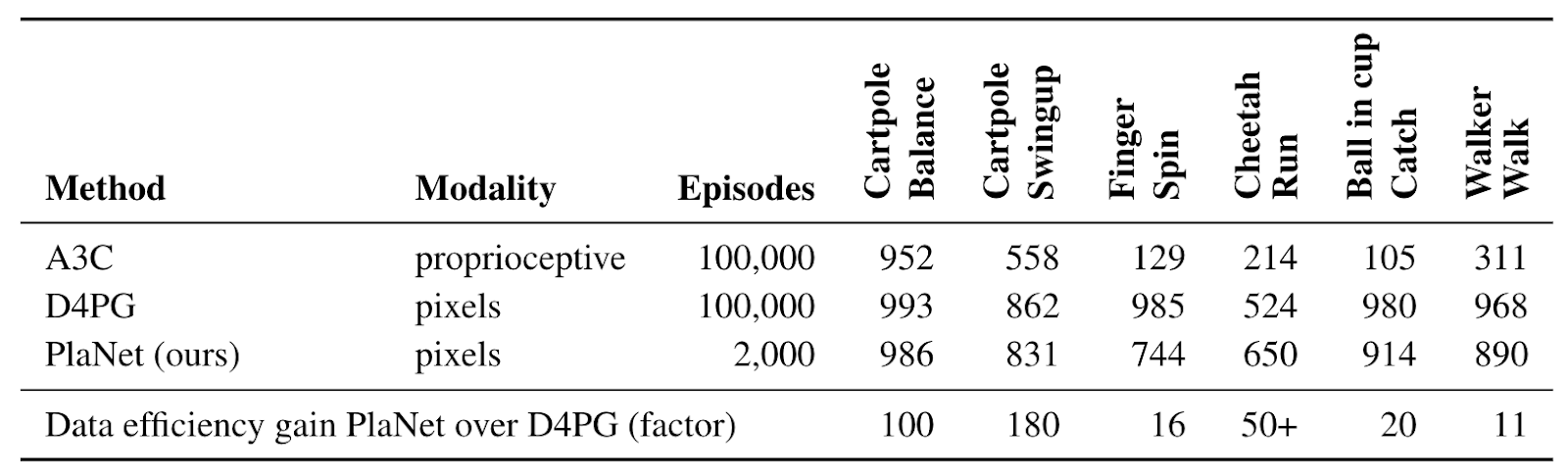
Additionally, we train a single PlaNet agent to solve all six tasks. The agent is randomly placed into different environments without knowing the task, so it needs to infer the task from its image observations. Without changes to the hyper parameters, the multi-task agent achieves the same mean performance as individual agents. While learning slower on the cartpole tasks, it learns substantially faster and reaches a higher final performance on the challenging walker task that requires exploration.
 |
| Video predictions of the PlaNet agent trained on multiple tasks. Holdout episodes collected with the trained agent are shown above and open-loop agent hallucinations below. The agent observes the first 5 frames as context to infer the task and state and accurately predicts ahead for 50 steps given a sequence of actions. |
Our results showcase the promise of learning dynamics models for building autonomous RL agents. We advocate for further research that focuses on learning accurate dynamics models on tasks of even higher difficulty, such as 3D environments and real-world robotics tasks. A possible ingredient for scaling up is the processing power of TPUs. We are excited about the possibilities that model-based reinforcement learning opens up, including multi-task learning, hierarchical planning and active exploration using uncertainty estimates.
Acknowledgements
This project is a collaboration with Timothy Lillicrap, Ian Fischer, Ruben Villegas, Honglak Lee, David Ha and James Davidson. We further thank everybody who commented on our paper draft and provided feedback at any point throughout the project.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯