Introducing interactive on-device segmentation in Snapseed
October 1, 2025
Ben Hahn and Florian Kübler, Software Engineers, Google Cloud
A novel mobile technology that facilitates real-time image segmentation, thereby improving the user experience for photo editing within Snapseed.
The key to elevating a good photo often lies in selective image adjustments: brightening a subject in the foreground, enhancing the sky, or making the color of a jacket pop. Yet, isolating specific elements with existing tools that offer subject, background, sky, or color-based selections has remained a frustrating and complex endeavor. This challenge has been particularly acute on mobile devices, where imprecise touch input and limited processing have made detailed selections and edits very difficult.
Now, we have made object-based image adjustments quick and easy. The new Object Brush in Snapseed on iOS, accessible in the "Adjust" tool, now lets you edit objects intuitively. It allows you to simply draw a stroke on the object you want to edit and then adjust how you want it to look, separate from the rest of the image. Give it a try as we roll this new capability out in the coming week!
Selective editing using Snapseed's Object Brush.
Intuitive editing through interactive on-device segmentation
At its core, Object Brush is powered by our Interactive Segmenter, a powerful AI model that runs entirely on device. With a simple gesture — just a tap or tracing a quick line — you can choose an object or person in the frame. The model will then immediately detect and select the complete object or person, in less than 20ms. The model generates a mask for the object, which accurately matches its boundaries, whether it's a person, a pet, or the clouds in the sky. This real-time feedback lets you refine your selection on the fly, easily adding or subtracting areas until it's just right. This entire process is powered by MediaPipe and LiteRT’s GPU acceleration for a fast and seamless experience.
This powerful fusion of a simple, intuitive user interface with an effective and efficient machine learning model makes advanced photo editing more accessible, enjoyable, and more precise than ever before, all running seamlessly on your own device.
Use foreground prompts (green) to select parts of an image and background prompts (red) to refine the selection.
Training the Interactive Segmenter model
The Interactive Segmenter model is designed to be a universally capable segmentation model, not limited to any specific class of objects or scenes. To avoid having to annotate large amounts of data to cover all areas, we chose to follow the Big Transfer approach and use a general pre-trained image encoder for pseudo-annotation to complement small amounts of manually annotated images.
Teacher for Interactive Segmenter
We started with a pre-trained and highly-generalizable model, fine-tuned for interactive segmentation. We took samples for 350+ different object categories and asked annotators to precisely annotate object masks with pixel-perfect quality. Through this process, we obtained ~30,000 high-quality image masks for these categories. While insufficient for direct training of a small mobile model, large pre-trained models can successfully be fine-tuned on this data to predict high accuracy masks. Using this dataset we trained an interactive segmentation model, which we call “Interactive Segmenter: Teacher”.
Interactive Segmenter: Teacher produces high-quality segmentation masks; however, its speed and size hinder its use in on-device scenarios. To overcome this challenge, we developed “Interactive Segmenter: Edge”, a specialized model tailored for on-device use cases by leveraging the knowledge distilled from the original Interactive Segmenter: Teacher model.
Distillation
Since the on-device model is significantly smaller, it has limited generalization capabilities, and the 30,000 annotated images we used for fine-tuning aren't sufficient to train a new model. At the same time the small model size implies we won’t see significant gains from pre-training on different domains or tasks.
For knowledge transfer from Interactive Segmenter: Teacher to Interactive Segmenter: Edge, we need millions of images and realistic prompts for a diverse range of object categories. So, we leveraged a large, weakly annotated dataset, which contains over 2 million images with masks across hundreds of different categories.

Interactive Segmenter: Edge yields a similar quality as Interactive Segmenter: Teacher for a given, fixed input prompt, as measured by the intersection over union (IOU) metric.
Prompt generation
The segmentation masks in the distillation dataset are not pixel-perfect, because they were generated through automated or semi-automated procedures, and are not ideal for training high-quality segmenters. Nevertheless, they are suitable for creating realistic prompts for interactive segmentation. In this process, the ground truth mask is produced on-the-fly by Interactive Segmenter: Teacher, which acts as a teacher model in a process known as knowledge distillation. Importantly, both the teacher as well as the student model use the same prompts during training, ensuring consistency across models.
We attempt to simulate a user selecting objects in an image. We draw random scribbles within the (eroded) ground truth mask to get foreground prompts (i.e., what the user wants to select, shown in red in the image below) and random scribbles outside the ground truth mask to get background prompts (i.e., what the user explicitly does not want to select, shown in blue). We simulate tapping by drawing random points as well as random scribbles. Furthermore, to support lasso selection we also expose the model during training to box prompts around an object.

By utilizing a teacher model we can train on data with low-quality ground truth annotations, reducing labeling costs without sacrificing model quality.
High quality vs. low latency
A central challenge was reconciling the conflicting demands of segmentation quality versus real-time, interactive latency. To reach the right balance, we decouple image and prompt understanding into distinct sub-models. First, a powerful, heavyweight image encoder is run once per image to extract a rich set of semantic features. This image encoder can be run as soon as the user’s intent to use interactive segmentation becomes apparent, thus effectively hiding the latency from the user. Second, a lightweight interactive encoder-decoder operates on these pre-computed features. This network takes the user's touch prompts and generates the final segmentation mask, executing well under our 20ms budget. This separation into two models allows Interactive Segmenter to harness the image understanding of a large model while delivering the instantaneous responsiveness of a small one.
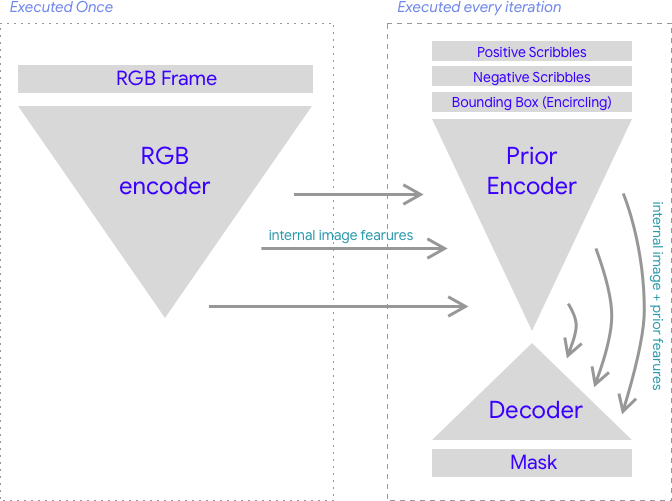
Interactive Segmenter neural network architecture.

Model inference latency when running Interactive Segmenter: Edge on-device.
The final student models (encoder + super decoder) are quantized to 8 bits and both run on LiteRT's GPU acceleration with decoder inference latencies of 7.4ms on an iPhone 16 Pro, enabling seamless and intuitive image editing.
Image-size mask upsampling
To preserve the best image editing quality on high-resolution images, we need high-resolution segmentation masks. To achieve this, we train our segmentation model to predict a mask in 768x768 resolution and further upsample it to image resolution (capped at 4k to have it fit within a single GPU buffer). We use an efficient GPU implementation of the edge-preserving joint-bilateral upsampling method. To improve latency, we only apply upsampling once a user completes a gesture by lifting their finger.

Original Interactive Segmenter mask (left) and upsampled mask (right).
Conclusion
With the new Interactive Segmenter in Snapseed image editing has become easier and more powerful than ever. Simple taps and strokes are translated into accurate selections, allowing users to translate their editing ideas into reality. Download Snapseed for iOS here and let your photos shine. Object Brush will be rolled out to more tools in Snapseed in the coming months. The underlying model powers a wide range of image editing and manipulation tasks and serves as a foundational technology for intuitive selective editing. It has also been shipped in the new Chromebook Plus 14 to power AI image editing in the Gallery app. Next, we plan to integrate it across more image and creative editing products at Google.
Acknowledgments
Special thanks to all members who worked on the tech with us: Valentin Bazarevsky, Daniel Fenner, Lutz Justen, Ronald Wotzlaw, Tai-Yu Daniel Pan, Jason Chang, Matthew Harries, Giles Ochs, Jonathan Horsman, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Karthik Raveendran, Matsvei Zhdanovich, Mogan Shieh, Chris Parsons, Jianing Wei, and Matthias Grundmann.
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-
March 17, 2026
Improving breast cancer screening workflows with machine learning- Health & Bioscience ·
- Human-Computer Interaction and Visualization




