InstructPipe: Generating Visual Blocks pipelines with human instructions and LLMs
April 18, 2025
Zhongyi Zhou, Research Scientist, and Ruofei Du, Interactive Perception & Graphics Lead, Google XR
InstructPipe is a research prototype that enables visual programming users to generate AI pipelines from human instructions by automating node selection and connection.
Quick links
To accelerate machine learning (ML) prototyping with interactive tools, we previously introduced Visual Blocks for ML at CHI 2023 and WebAI Summit 2024. Visual Blocks is a visual programming framework that lets you program in a visual editor by connecting blocks on a workspace into a flow of blocks, which we call a node-graph diagram, or an AI pipeline (see our live demo and Colab examples). Visual programming provides programmers with a low-code experience to program using only building blocks. However, novice users still sometimes struggle with setting up and linking appropriate nodes from a blank workspace.
In “InstructPipe: Generating Visual Blocks Pipelines with Human Instructions and LLMs”, awarded an Honorable Mention at CHI 2025, we further introduce InstructPipe, an AI assistant for prototyping machine learning pipelines with text instructions. We contribute three modules — two large language model (LLM) modules and a code interpreter — as part of this framework. The LLM modules generate pseudocode for a target pipeline, and the interpreter renders the pipeline in the visual editor for human-AI collaboration. Both technical and user evaluation shows that InstructPipe empowers users to streamline their ML pipeline workflow, reduce their learning curve, and leverage open-ended commands to spark innovative ideas.
InstructPipe Demo: The user can generate a Visual Blocks pipeline by simply prompting our AI model.
Pipeline generation from instructions
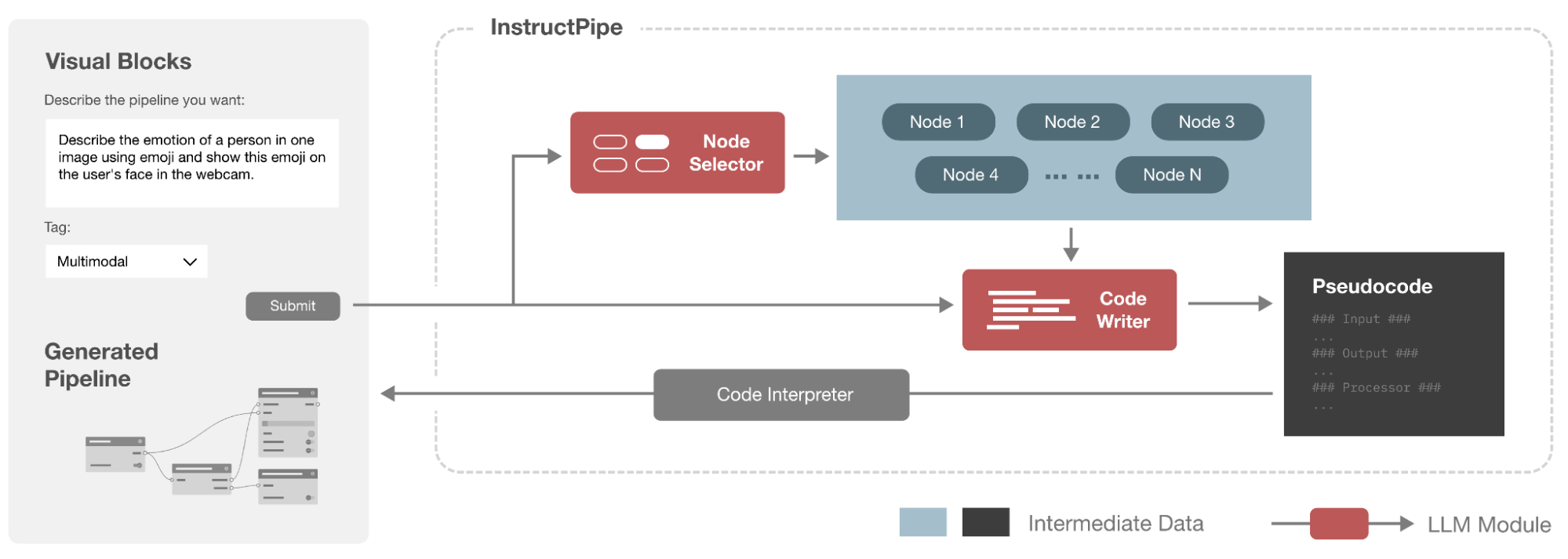
We implement InstructPipe with a two-stage LLM refinement prompting strategy, followed by a pseudocode interpretation step to render a pipeline. The figure below illustrates the high-level workflow of the InstructPipe implementation. InstructPipe leverages two LLM modules (highlighted in red) — a Node Selector, and a Code Writer. Given a user instruction and a pipeline tag (e.g., a multimodal pipeline), we first devise the Node Selector to identify a list of potential nodes that would be used according to the instructions. In the Node Selector, we prompt the LLM with a very brief description of each node, aiming to filter out unrelated nodes for a target pipeline. The selected nodes and the original user input (the prompt and the tag) are then fed into the Code Writer, which generates pseudocode (i.e., a succinct code format that defines the selections and connections of the essential nodes) for the desired pipeline. In Code Writer, we provide the LLM with detailed descriptions and examples of each selected node to ensure the LLM has extensive context for each candidate node. Finally, we employ a Code Interpreter to parse the pseudocode and render a visual programming pipeline with which the user may interact.
Users describe a desired pipeline in natural language, and InstructPipe automatically generates a corresponding, editable pipeline by selecting nodes, writing pseudocode, and interpreting it into a JSON format within Visual Blocks.
Pipeline representation
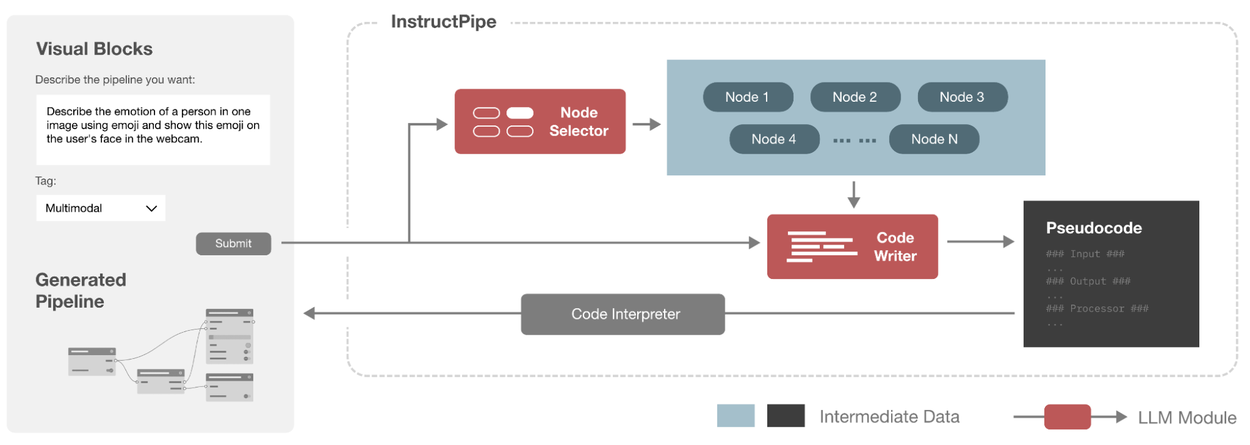
The Visual Blocks system represents a pipeline as a directed acyclic graph (DAG) in JSON format. To compress the verbose JSON file, InstructPipe represents pipelines as pseudocode, which can be further compiled into a JSON-formatted pipeline. Pseudocode representation is highly token-efficient, it compresses the pipeline from 2.8k tokens to 123 tokens.
See an example of a pipeline and its corresponding pseudocode in the figure below. We highlighted the first line under the processor module (i.e., the operation of the PaLI node) in four different colors, representing four different components in the programming language.
- “pali_1_out” represents the output variable name of the node.
- “pali_1” is the unique ID of the node.
- The green symbol after the colon, i.e., “pali”, specifies the type of the node. In this example, the node with the ID of “pali_1” is a “pali” node.
- The rest in the bracket, i.e.,“image=input_image_1, prompt=input_text_1”, defines the arguments of the nodes.
Example pipeline.

Example pseudocode.
Node selector
The Node Selector aims to filter unrelated nodes by providing an LLM with a short description of each node. The prompt we used for the LLM includes:
- A general task description and guidelines.
- A list of node types with a short description that explains the function of each node.
- [Optional] Some nodes have recommended pairs.
- In-context examples.
The intuition of this prompt design is based on how the existing open-source libraries (e.g., Numpy) present a high-level overview of all functions. This documentation typically provides a list of supported functions (in each category), followed by a short description, so that developers can quickly find their desired functions.
Code writer
With a pool of selected nodes, the Code Writer module is able to write pseudocode for rendering a target pipeline. The prompt contains:
- A general introduction and several guidelines.
- A detailed node configuration, including:
- Input data types.
- Output data types.
- An example, represented in pseudocode, showing how this node connects to other nodes.
The design Intuition comes from the low-level function-specific documentation, which typically includes a detailed description and data types in the input/output followed by one or more examples of how developers can use this function with a few lines of code.
Code interpreter
Finally, InstructPipe employs a code interpreter to parse the generated pseudocode, correct errors, and compile a JSON-formatted pipeline with automatic layout. We delineate the graph compilation and rendering procedure below:
- Lexical analysis: Using a series of regular expressions, the pseudocode is tokenized into node type, node name, and node parameters.
- Graph generation with default node parameters: A DAG is generated based on the tokenized results and predefined default node parameters are applied in each generated node.
- Graph rendering and optimization: Finally, the generated graph is traversed using a breadth-first search algorithm, and the nodes are laid out with grid alignment in the node-graph editor within Visual Blocks.
Technical evaluations
We organized a two-day hybrid workshop using the latest iteration of Visual Blocks with the goals of assessing the efficacy of InstructPipeand implementation space and collecting data for technical evaluation.
Results
We collected 48 annotated pipelines from the workshop. InstructPipe allowed the user to complete a pipeline with 18.9% of the user interactions in the baseline condition (e.g., building Visual Blocks pipelines from scratch without AI support), demonstrating the potential of InstructPipe to require many fewer interactions. Seven generated pipelines were directly satisfied with instructions without user interactions in all six trials, and 38 generated pipelines completed at least once in any of the six trials.
User evaluations
Study design and procedure
We designed a user study in which we began by providing 10–15 minutes of hands-on training both with InstructPipe and without it. Participants then progressed to building pipelines under both conditions.
The experiment was designed as a within-subject study with counterbalance, which reduces users’ learning effects in the study. Each participant built two pipelines with two conditions, so in total, they were assigned four tasks. The pipelines were carefully selected to ensure a fair comparison as well as to provide users a diverse experience of InstructPipe.
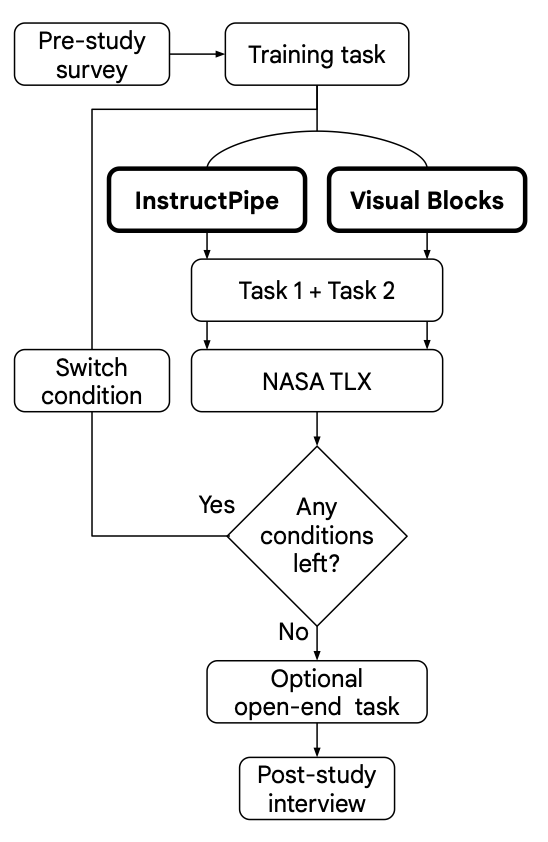
The user study workflow, where participants either built a pipeline using InstructPipe or without (i.e., using Visual Blocks).
Results
We introduced three quantitative metrics in our user study: 1) task completion time, 2) the number of user interactions, and 3) perceived workload, i.e., RAW-TLX questionnaires, aiming to understand users’ workload in their creative processes both subjectively and objectively.
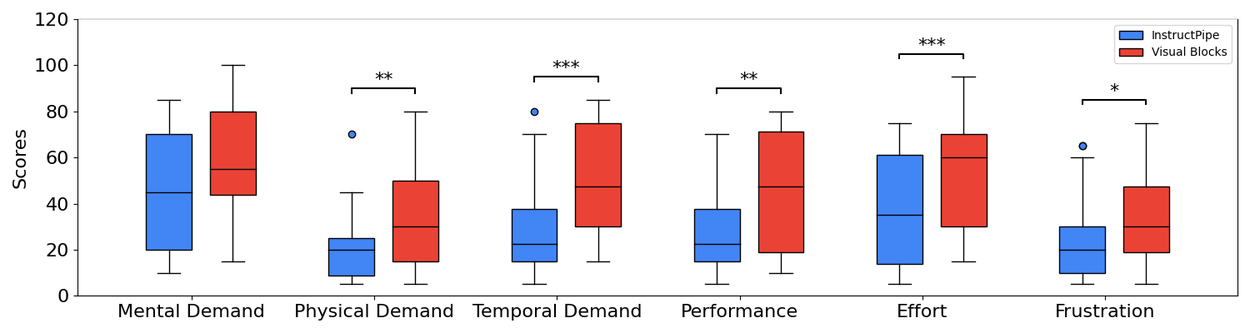
Raw-TLX results. The statistic significance is annotated with ∗, ∗∗, or ∗∗∗ (representing 𝑝<.05, 𝑝<.01, and 𝑝<.001, respectively).
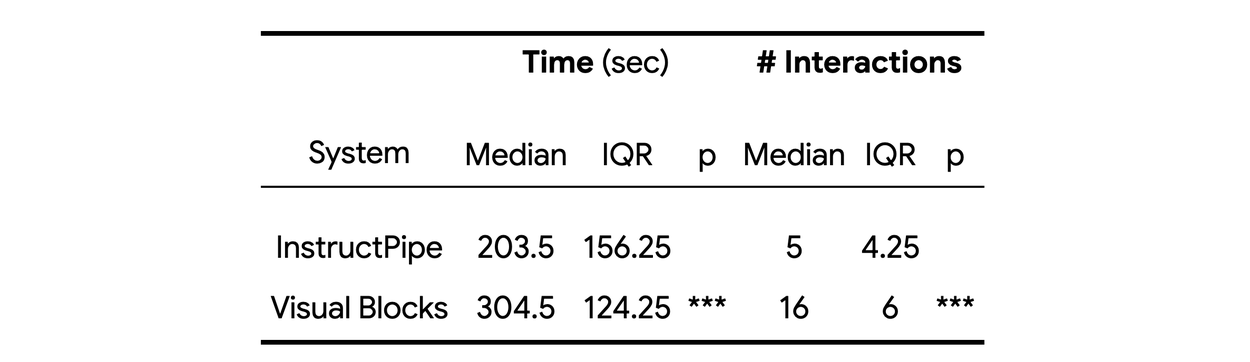
Task completion time and the number of human interactions in the user study. We use ∗ ∗ ∗ to denote 𝑝 < .001.
As is shown in the figure and table above, the NASA-TLX, time completion and the number of human interactions results demonstrate that InstructPipe allows users to create AI pipelines with significantly lower workload. We also collected qualitative feedback that is summarized as follows:
- InstructPipe provides users with visual programming onboarding support.
- Users appreciate our integration into the existing visual programming workflow.
- InstructPipe can empower accessible ML prototyping and education.
Discussion
Our evaluations demonstrate that InstructPipe automates most pipeline components with a single prompt, but also that InstructPipe is not able to automate the entire pipeline creation processes.
While LLMs cannot always generate a fully executable pipeline, InstructPipe systems can successfully render a certain portion of a pipeline for users. Such generations provide crucial support for people to perform visual programming tasks in a human-AI collaborative process.
Conclusions and future directions
We introduced InstructPipe, an AI agent for visual ML pipeline design. With the power of text instructions, InstructPipe empowers users to build sophisticated workflows with lower workload. We've achieved this by developing a system with three core modules: a context-aware node selector, a powerful code writer, and a reliable code compiler. Our testing demonstrates that InstructPipe delivers a seamless onboarding experience to visual programming systems, enabling rapid idea prototyping and significantly reducing user interactions. We're also opening up a discussion on the unique challenges of integrating LLMs into visual programming environments, highlighting both human-centered and technical considerations. We hope InstructPipe serves as a catalyst for future research, fostering innovation in human-AI collaboration, and unlocking new levels of expressivity and creativity in machine learning and beyond.
Check out this video about InstructPipe.
Acknowledgements
This work is a collaboration across multiple teams at Google. Key contributors to the project include Zhongyi Zhou, Jing Jin, Vrushank Phadnis, Xiuxiu Yuan, Jun Jiang, Xun Qian, Jingtao Zhou, Yiyi Huang, Zheng Xu, Yinda Zhang, Kristen Wright, Jason Mayes, Mark Sherwood, Johnny Lee, Alex Olwal, David Kim, Ram Iyengar, Na Li, and Ruofei Du. We would like to extend our thanks to Adarsh Kowdle, Guru Somadder, Gong Xuan, Fengyuan Zhu, Kevin Zhang, Karl Rosenberg, Koji Yatani and Takeo Igarashi for their feedback on prototypes and the research paper.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product




