Unlocking dependable responses with Gemini Enterprise Agent Platform’s Agentic RAG
June 5, 2026
Cyrus Rashtchian, Research Scientist, and Da-Cheng Juan, Engineering Manager, Google Research
We introduce our new agentic RAG framework. Based on a collaboration between Google Research and Google Cloud, our multi-agent workflow goes beyond standard RAG by breaking down complex enterprise queries and iteratively searching for sufficient context before generating dependable responses.
Quick links
Current single-step retrieval-augmented generation (RAG) systems weren’t designed for the multi-source, multi-hop queries of modern business workflows. If, for example, the query is, "What are the specs of the server used in Project X?", the system might find documents about Project X, but those documents might only mention a server ID. It won't know to take that ID and perform a second search in another database to find the specs. The result is a partial answer or a "not found" response because the information is spread across different "islands" of data, requiring deeper exploration to find the facts.
Enter “agentic RAG”, which plans, reasons, and iteratively interacts with data sources, enabling the handling of complex queries to increase dependability and accuracy.
Today, we’re excited to introduce Google’s Gemini Enterprise Agent Platform-hosted version of Cross-Corpus Retrieval powered by Agentic RAG. Like other multi-agent RAG frameworks, ours employs various agents that work together to reliably answer complex queries. Unlike other multi-agent frameworks, ours incorporates sufficient context to confirm if there is enough information for an accurate answer. Compared to standard RAG, our framework increases accuracy on factuality datasets by up to 34%. We also evaluated our system with proprietary, internal datasets and found that we achieve better grounding and improved reasoning accuracy on multiple domain-specific tasks.
How multi-agent architectures work: Planning, rewriting, and routing
It helps to think of multi-agent RAG not as a single search engine but as an organized research department. In a "monolithic" or “Vanilla” RAG system, the retrieval component just looks at your question and tries to find matching documents before an LLM generates a response.
In a multi-agent framework, the system breaks the job down into specialized roles:
- The Orchestrator evaluates your complex request and decides, "This isn't a one-step job", and delegates the work to agents.
- The Planner Agent maps out the information pathways. If you ask about a project’s budget and its timeline, for example, the Planner Agent decides: "First, we need to check the finance database, then we need to check the project management logs."
- The Query Rewriter translates your request into multiple search queries. It turns "What's up with Project X?" into "Status report for Project X Q3" and "Key blockers for Project X team."
- The Search Fanout Agent takes those refined queries and sends them to various retrieval sources to collect snippets of information.
- Finally, an LLM aggregates all the context to deliver a final response.
Demonstrating a standard agentic RAG system. While this has multiple agents, it does not include iterative retrieval or specialized cross-corpus support.
What makes our agentic RAG different from others
The key difference with our new agentic RAG framework is persistence. Compared to other RAG solutions, our framework is effective because it knows when it is missing information and continues searching until the context is complete. This prevents the AI from "guessing" when the first search comes up empty, or from simply saying, “I don’t have enough information.” While this is an appropriate response in some cases, sometimes the information is there and we just need to find it.
For example, imagine a doctor asking about a patient’s medications, diet, and allergies:
"What are the discharge medications and dietary restrictions for John Doe after his knee surgery, and did he have any allergic reactions during his stay? Do not include medications only administered during hospital inpatient or emergency department visits except for heparin IV drip or Tenecteplase."
In response, our framework kicks off many specialized agents. We give an overview of our solution in the figure below and then describe it in more detail afterwards.
Illustrating our multi-agent RAG solution, which includes a sufficient context agent, as well as the ability to iteratively retrieve more information before answering the query.
Phase 1: Orchestration
The Root Agent parses the doctor's request and delegates the tasks to sub-agents. The Planner Agent identifies that it needs to check three distinct areas: Pharmacy, Nutrition, and Clinical Notes. The Query Rewriter breaks the long request into simple, searchable questions so the retriever can more accurately find relevant content.
Phase 2: Search (standard step)
The RAG Agent searches the patient's records for all the query fanouts at once. It finds the medications and the diet information, but it can’t find any mention of allergies in the most obvious files. In a standard or “Vanilla” RAG system, the process might end here with an incomplete answer.
Phase 3: Sufficient Context Agent (new research innovation)
Think of the Sufficient Context Agent as a quality-control inspector standing at the end of an assembly line. It examines three specific findings before allowing a response to be generated:
1. Retrieved snippets
The Sufficient Context Agent evaluates the actual text chunks pulled from the database by the RAG Agent. In the doctor's example, these could be the specific paragraphs found in the "Discharge Summary" and "Nutrition Notes." It reads these to see if the information needed to answer the query is present in those sentences.
2. Intermediate draft
The system also creates a "rough draft" response. The Sufficient Context Agent then reviews the prompt, draft, and retrieved snippets to evaluate whether the model has everything it needs to provide a comprehensive and grounded answer. If the prompt asks for three things (meds, diet, allergies) but the snippets only contain information about two, the Sufficient Context Agent flags it as “insufficient context.”
3. Missing pieces analysis
This is the most critical part. The Sufficient Context Agent identifies exactly what is not there. It doesn't just output that "this is insufficient"; it generates a specific "Reason" and "Feedback" log. For example:
Finding: "We have the medication list and the low-sodium diet instructions."
Gap: "We are missing information from the source documents about allergic reactions or adverse events during the stay."
The Sufficient Context Agent compares what was found against the original request and asks: "Did we answer the allergy question?” If not, it then issues an "Insufficient Context" signal and provides specific feedback: "You found meds and diet, but you missed allergies. Go back and search specifically for 'rashes' or 'adverse events'." In a multi-source situation, it can also request more information or decide that the source isn’t relevant to the query.
Phase 4: Iteration
Because of the Sufficient Context Agent feedback, the Query Rewriter creates a new search for "rashes." Then, the RAG Agent dives deeper into files it ignored the first time and finds the missing information.
Phase 5: Synthesis (final answer)
The Sufficient Context Agent checks the data one last time. Now that it has the meds, diet, and allergy info, it determines we can stop searching. Finally, the Synthesis Agent writes a clean, accurate summary for the doctor.
Experiments and results
We evaluated agentic RAG on FramesQA, which is based on the FRAMES paper. An example multi-hop question is:
“Of the top two most watched television season finales (as of June 2024), which finale ran the longest in length and by how much?”
The RAG system needs to perform multiple steps to arrive at the correct answer. First, it has to identify that the two most watched finales are from the shows M*A*S*H and Cheers. Then, it has to find their running times, and calculate the length difference. In many RAG settings (Vanilla RAG or agentic RAG without sufficient context), we could end up in a situation where the model says something like:
“Despite multiple scans, I found no explicit runtimes for M*A*S*H or Cheers. The documents provide viewership data, but not the duration in minutes or hours.”
This does not answer the question.
Fortunately, our agentic RAG can solve this by first searching for the TV shows, then using the Query Rewriter and Sufficient Context Agent to have a targeted search for the run time of M*A*S*H or Cheers. Then, Gemini can easily determine which finale ran the longest in length and by how much:
“The M*A*S*H finale ran for 150 minutes, making it the longest of the top two. It was 52 minutes longer than the Cheers finale, which ran for approximately 98 minutes.”
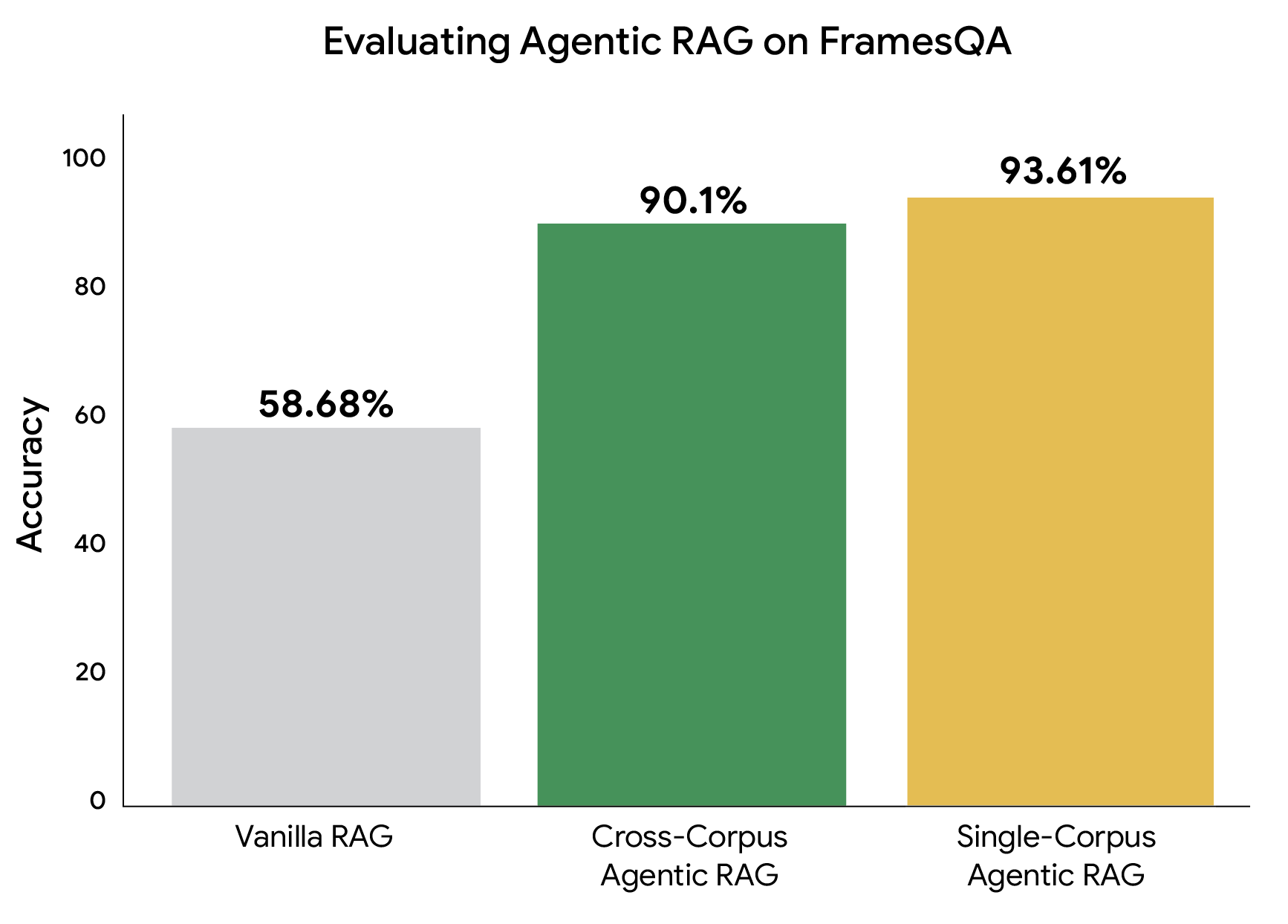
We ran an experiment to test this ability at scale (FramesQA has 824 queries along with a corpus containing 2,676 PDF documents). In the “Vanilla” RAG setting, we use Google’s RAG Engine (which has an advanced retrieval engine, LLM parser, and re-ranker). We compared this with our agentic RAG in two settings. In the single-corpus setting, we retrieve from the FramesQA documents. In the cross-corpus setting, we also include three other distracting datasets, where the Planner Agent must determine where to retrieve from. This cross-corpus setting mimics use cases where companies have databases managed by separate teams. We compute accuracy by using an LLM-as-a-judge to compare the system responses to the ground truth answers in the dataset.
In the cross-corpus setting, our system nearly matches its single-corpus accuracy. Even when the Planner Agent must select the correct corpus out of 4 possibilities, we successfully route the search queries and answer 90.1% of questions correctly. Also, the latency of both single- and cross-corpus versions is about the same (within 3% on average). This demonstrates that our Agentic RAG system can reason over multiple, unrelated data sources, which opens up possibilities for more flexible retrieval scenarios.
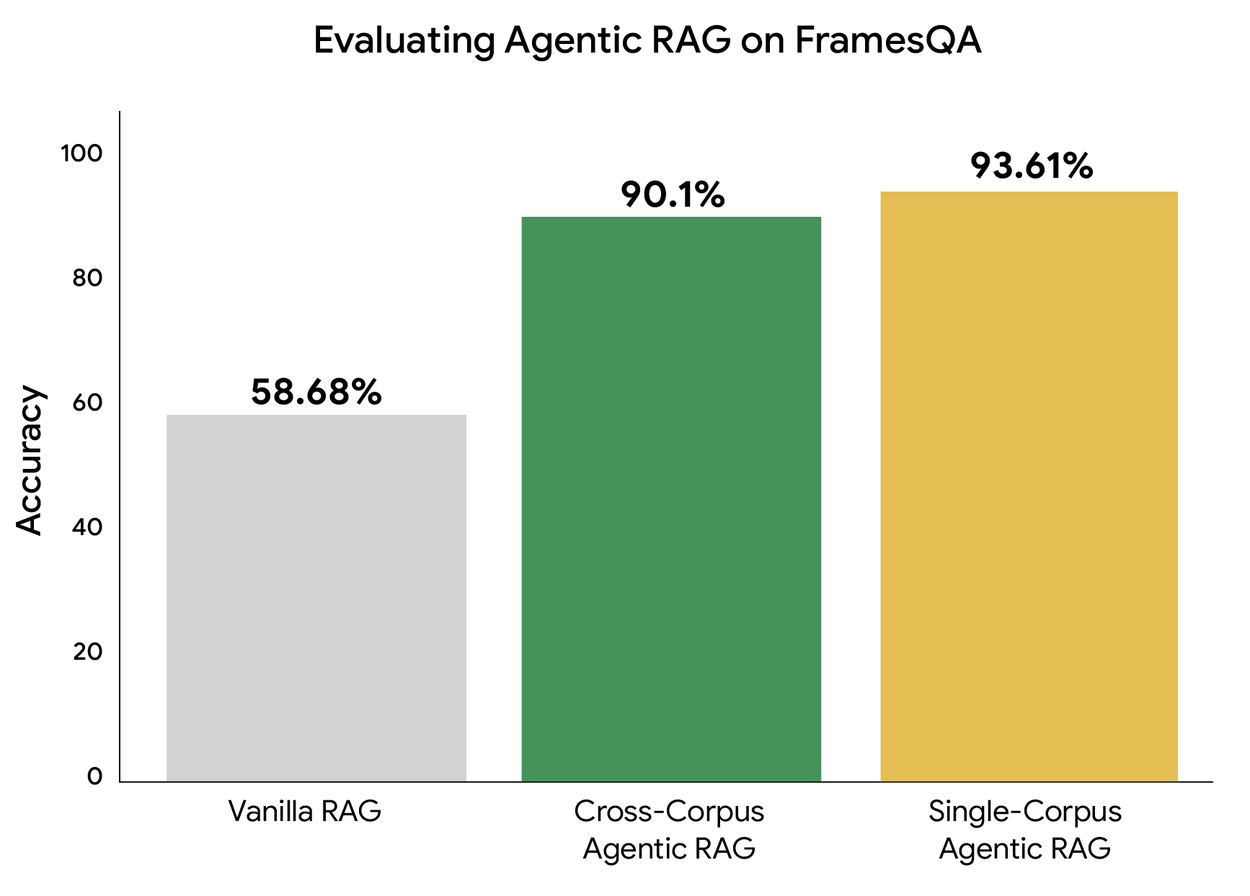
Comparison of cross-corpus retrieval versus single-corpus and Vanilla RAG on FramesQA, demonstrating that our agentic solutions achieve high accuracy.
Conclusion
By combining advanced query planning, routing, and sufficient context, our agentic RAG system ensures that AI-generated responses are auditable, traceable, and grounded. We look forward to seeing how the machine learning community leverages these new agentic capabilities to build the next generation of dependable AI systems. This new feature is now available as a public preview offering in Gemini Enterprise Agent Platform.
Acknowledgments
This project is joint work with Bo Li, Zhongjie Mao, Tiger Jin, Yuhong Kan, Mohd Abdullah (Obito), Chun-Sung Ferng, Pooneh Mortazavi, Roger (Peng) Yu, Eran Lewis, and Ivan Kuznetsov. We thank Kimberly Schwede for designing the graphics and Mark Simborg for writing assistance. We also thank our key enterprise partners for critical user feedback, data, and insights.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product