Insights into population dynamics: A foundation model for geospatial inference
November 14, 2024
David Schottlander, Product Manager, and Gautam Prasad, Software Engineer, Google Research, Health AI Team
We introduce a population dynamics foundation model and dataset able to easily be adapted to solve a wide array of geospatial problems across health, socioeconomic, and environmental tasks.
The relationships between a population of people, their health outcomes, and their local contexts can be very complex. Nevertheless, developing an understanding of these population dynamics can be crucial for addressing complex social problems, such as disease, economic security, disaster response, and much more. Despite the importance, however, accurate predictions for these population dynamics have been elusive for decades and remain a challenge for researchers, policymakers, and businesses.
Traditional approaches to understanding population dynamics tend to rely on data from censuses, surveys, or satellite imagery. While valuable, these types of data each have their own unique shortcomings. Censuses, though comprehensive, are infrequent and expensive; surveys can offer localized insights, but often lack scale and generalizability; and satellite imagery provides a broad overview, but lacks granular detail on human activity. In an effort to mitigate some of these shortcomings, over the years Google has designed, built, and shared a wealth of datasets that offer unique insights into population behavior, including Google Search Trends, COVID-19 Community Mobility Reports, and Access to Emergency Obstetrics Care.
In continued pursuit of this objective, today we are pleased to introduce a novel geospatial foundation model, built on aggregated data to preserve privacy, which we describe in “General Geospatial Inference with a Population Dynamics Foundation Model”. We designed the model (referred to as PDFM) so users could easily fine-tune it to a wide variety of downstream tasks. We are also releasing a dataset of unique location embeddings derived from the PDFM and code recipes users can employ to enhance their existing geospatial models. The dataset and code recipes aim to provide insights that can be applied to machine learning (ML) problems that rely on an understanding of populations and the characteristics of their local environments. They are easily adapted to many data science questions, enabling a more holistic and nuanced understanding of population dynamics around the world.
The Population Dynamics Foundation Model architecture
At the heart of the PDFM lies a graph neural network (GNN) that encodes the location embeddings into information-rich, lower-dimensional numerical vectors. For our first generation of PDFM, we construct a graph covering the continental United States with counties and postal codes as nodes. Each node contains corresponding human-centric data, environmental data, and local characteristics as features. These nodes are connected by two types of edges:
- Proximity-based edges: These connect locations of the same type (postal code ↔ postal code, county ↔ county) that lie within a 100 mile radius. Locations of different types (county ↔ postal code, and vice versa) are connected if they have overlapping geographic boundaries. In this way, the graph captures spatial relationships.
- Relationship-based edges: These edges are derived from the similarity of aggregated search trends.
Learning a geospatial foundation model. Each node represents either a postal code or county in the US and incorporates the corresponding aggregated search trends, maps, weather, air quality data, and general level of “busy-ness”. The GNN is able to incorporate network effects through spatial and affinity edges to learn a per node embedding used as the location encoding that powers downstream tasks.
The GNN uses self-supervision to learn the complex relationships between these locations via message passing and is not tied to any specific task. It incorporates information from each node’s neighbors to transform the original input signals at each node into embeddings that possess a rich understanding of population dynamics.
PDFM embeddings
The PDFM combines distinct sources of information to create unique embeddings for different locations, capturing their multifaceted characteristics and the complex interplay between human behavior and the environment. The spectrum of data types incorporated are:
- Population-centric data: This includes aggregated web search trends, which provide insights into the interests, concerns, and needs of different communities. It also incorporates aggregated metrics for how busy a location is, which can reveal how people interact with their environment and respond to events.
- Environmental data: This encompasses weather and air quality measurements that can influence population dynamics.
- Local characteristics: This includes data on point-of-interest categories, which provides valuable context about the amenities, services, and businesses available in different locations.
The embeddings from the PDFM are built from data that have already been aggregated over administrative regions and time horizons to preserve privacy.
Powering downstream geospatial modeling
We evaluated the PDFM's performance on four key geospatial tasks:
- Interpolation: Filling in missing locations within a dataset.
- Extrapolation: Generalizing to unseen locations over larger spatial distances.
- Forecasting: Predicting future timesteps of existing geospatial time series.
- Super-resolution: Generating high-resolution data from low-resolution sources.
Example of a super-resolution task using PDFM: Starting with county level median household income data in the state of New York, it is possible to map out postal codes with the PDFM. This county level data is used in conjunction with the PDFM embeddings in a simple downstream model to enable super-resolution by mapping out the finer level postal codes.
For each task, we trained a simple downstream supervised learning model using the PDFM embeddings as covariates. We tested each one on a diverse set of 29 geospatial variables using a benchmark that we published previously, including health, socioeconomic, and environmental categories.
The predictions from the supervised models were compared to existing state-of-the-art methods, including SatCLIP (a geographic encoder based on satellite imagery) and GeoCLIP (trained on millions of geotagged images). We also compared against more traditional interpolation techniques like inverse distance weighting (IDW). In all almost all cases, using the PDFM outperformed the other methods:
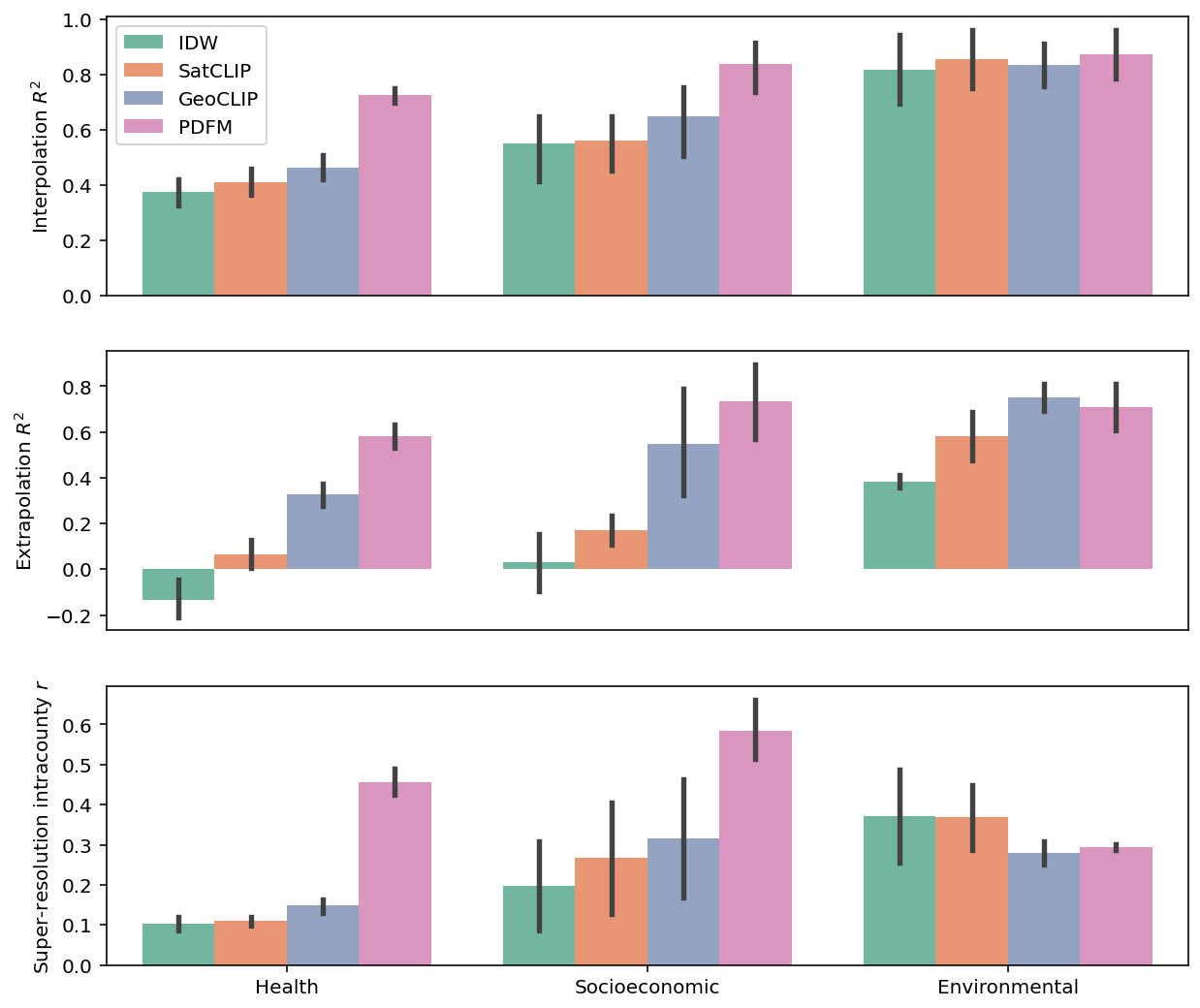
Performance of the PDFM on downstream tasks: Here we show the interpolation, extrapolation, and super-resolution performance across health, socioeconomic, and environmental categories of target variables. The PDFM embeddings are compared with inverse distance weighting (IDW), SatCLIP, and GeoCLIP approaches. Our metrics include coefficient of determination (R2) for interpolation/extrapolation and Pearson's correlation coefficient (r) for super-resolution, where higher is better in both cases.
Although the results shown above reflect specific choices of downstream models, further experiments showed comparable results across various choices of supervised learning algorithms. This reflects the PDFM’s ability to provide versatility and flexibility without compromising on performance.
Enhancing forecasting with the PDFM embeddings
We also tested whether the location embeddings of the PDFM could contribute to the accuracy of temporal forecasting models. For this we integrated the PDFM embeddings with TimesFM, a general-purpose univariate forecasting foundation model. We trained a simple adapter — a two-layer multilayer perceptron (MLP) — to augment TimesFM forecasts using the PDFM embeddings, and we compared the result with a fully supervised approach, autoregressive integrated moving average (ARIMA). We then evaluated this approach on two variables: unemployment rates at the county level and poverty rates at the postal code level. TimesFM combined with the PDFM embeddings had the lowest mean absolute percentage error of the methods compared, achieving an error reduction of 5% for unemployment and 20% for poverty rate forecasts.
We are also able to complement and enhance performance of our original modalities by incorporating SatCLIP features as another input signal into the PDFM, resulting in significant performance gains across socioeconomic and environmental tasks.
PDFM applications
We believe that the PDFM can be applied to a range of applications spanning various domains, including:
- Public health: The PDFM could be used in models that predict the prevalence and spread of diseases to help inform public health policy and resource allocation decisions.
- Retail: The PDFM could be used by retail analysts to take into account factors like population density, consumer interests, and competitor presence in their decision making.
- Climate risk impact analysis: Environmental scientists could apply the PDFM to models that monitor the human impact of deforestation, air quality changes, and the impact of climate change on different regions.
- Macro- and socioeconomic indicators: The PDFM could be used to characterize regions with embeddings in order to optimize macro- and socioeconomic indicators such as GDP or unemployment.
PDFM availability
To develop models for your own geospatial tasks you can check out example Google Colab Notebooks (including recipes for interpolation and extrapolation, super-resolution, nowcasting, and enhancing forecasting with an existing model), and use this form to request access to the PDFM embeddings that we are piloting for the United States. We believe the PDFM has the potential to enhance geospatial modeling and unlock new possibilities for understanding and supporting populations around the world. But we can’t realize that potential alone, and so, we invite the community to explore and build on this work and to share feedback and suggestions to further improve the embeddings.
Acknowledgements
This work was done in collaboration with Mohit Agarwal, Mimi Sun, Chaitanya Kamath, Arbaaz Muslim, Prithul Sarker, Joydeep Paul, Hector Yee, Marcin Sieniek, Kim Jablonski, Yael Mayer, David Fork, Sheila de Guia, Jamie McPike, Adam Boulanger, Tomer Shekel, Yao Xiao, Manjit Chakravarthy Manukonda, Yun Liu, Neslihan Bulut, Sami Abu-el-haija, Arno Eigenwillig, Parth Kothari, Bryan Perozzi, Monica Bharel, Von Nguyen, Luke Barrington, Niv Efron, Yossi Matias, Greg S. Corrado, Krish Eswaran, Shruthi Prabhakara, Shravya Shetty. Visual design by John Guilyard.
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
