Improving Mobile App Accessibility with Icon Detection
January 28, 2021
Posted by Gilles Baechler and Srinivas Sunkara, Software Engineers, Google Research
Quick links
Voice Access enables users to control their Android device hands free, using only verbal commands. In order to function properly, it needs on-screen user interface (UI) elements to have reliable accessibility labels, which are provided to the operating system’s accessibility services via the accessibility tree. Unfortunately, in many apps, adequate labels aren’t always available for UI elements, e.g. images and icons, reducing the usability of Voice Access.
 |
| The Voice Access app extracts elements from the view hierarchy to localize and annotate various UI elements. It can provide a precise description for elements that have an explicit content description. On the other hand, the absence of content description can result in many unrecognized elements undermining the ability of Voice Access to function with some apps. |
Addressing this challenge requires a system that can automatically detect icons using only the pixel values displayed on the screen, regardless of whether icons have been given suitable accessibility labels. What little research exists on this topic typically uses classifiers, sometimes combined with language models to infer classes and attributes from UI elements. However, these classifiers still rely on the accessibility tree to obtain bounding boxes for UI elements, and fail when appropriate labels do not exist.
Here, we describe IconNet, a vision-based object detection model that can automatically detect icons on the screen in a manner that is agnostic to the underlying structure of the app being used, launched as part of the latest version of Voice Access. IconNet can detect 31 different icon types (to be extended to more than 70 types soon) based on UI screenshots alone. IconNet is optimized to run on-device for mobile environments, with a compact size and fast inference time to enable a seamless user experience. The current IconNet model achieves a mean average precision (mAP) of 94.2% running at 9 FPS on a Pixel 3A.
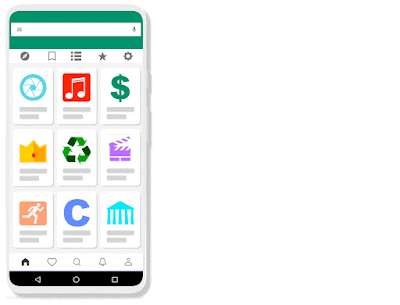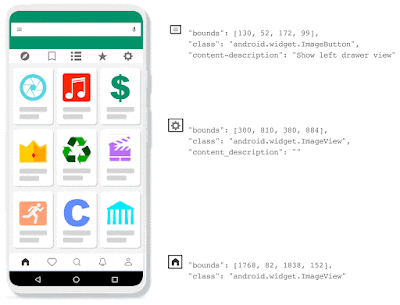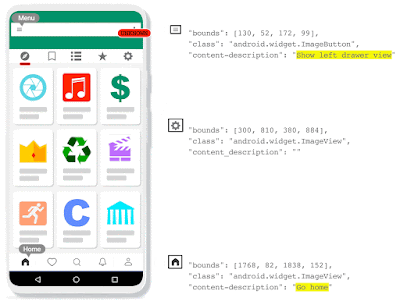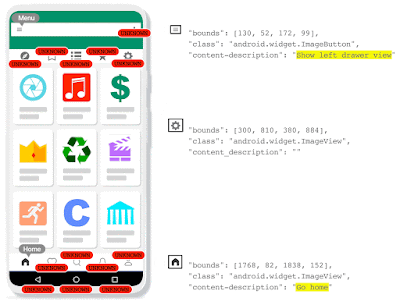
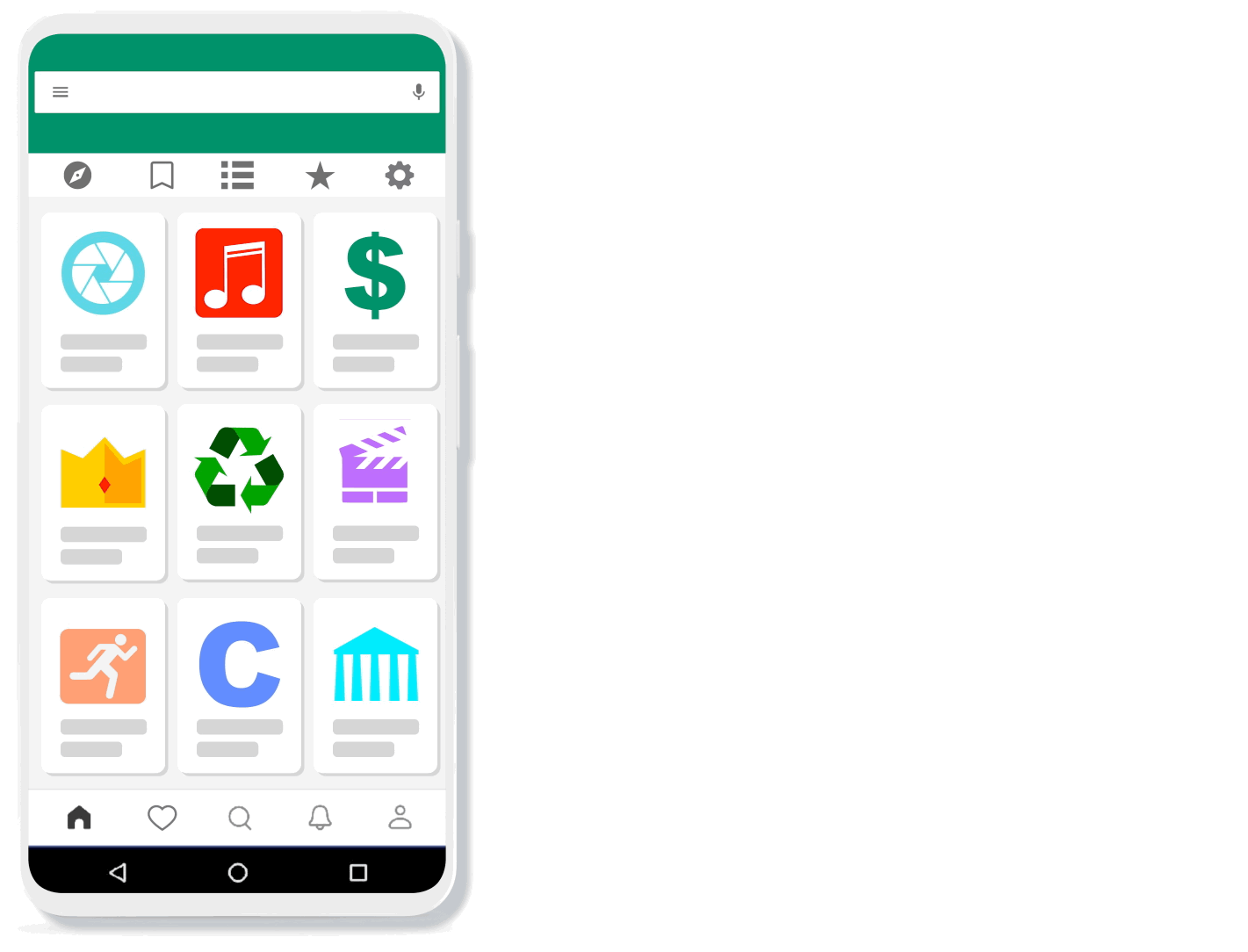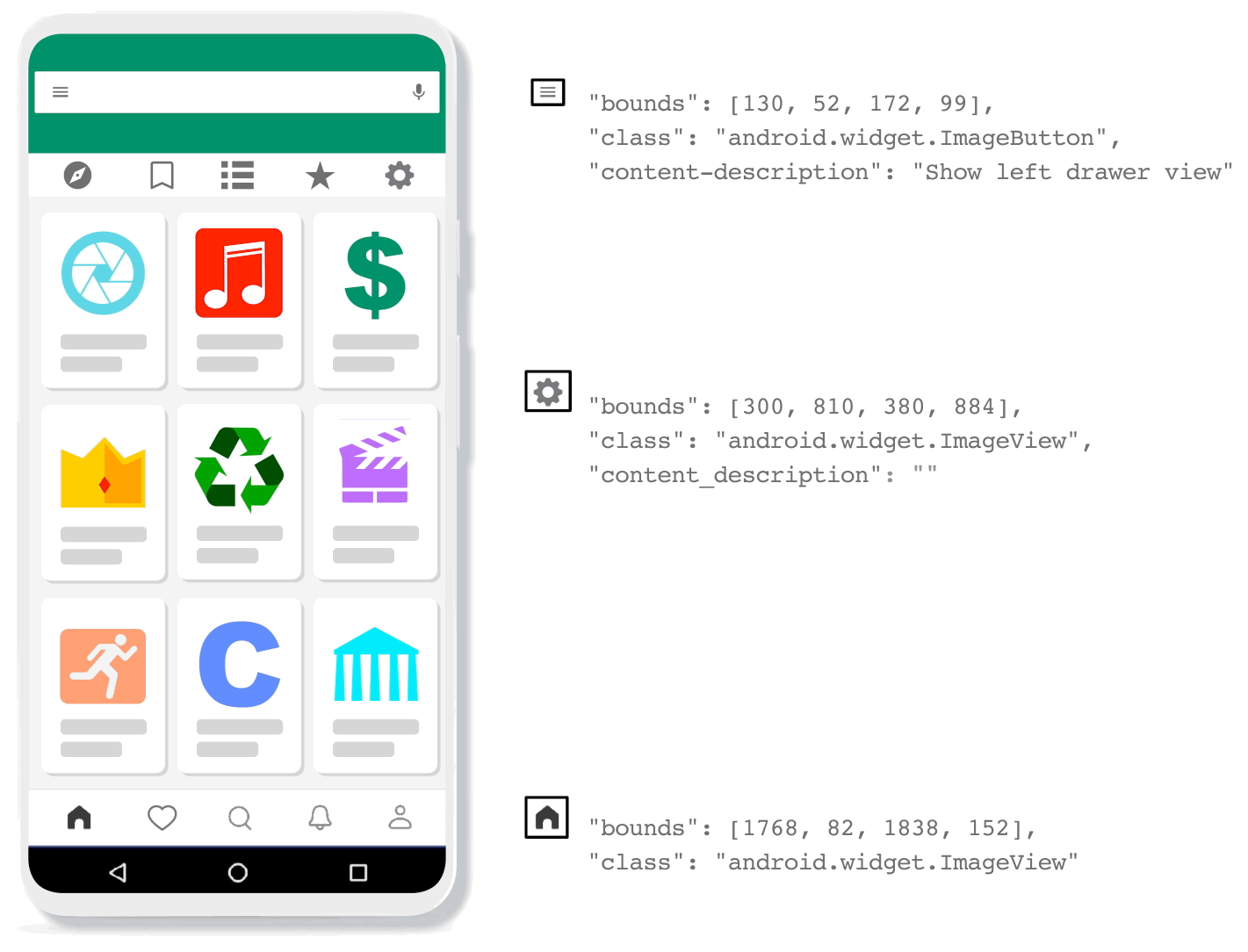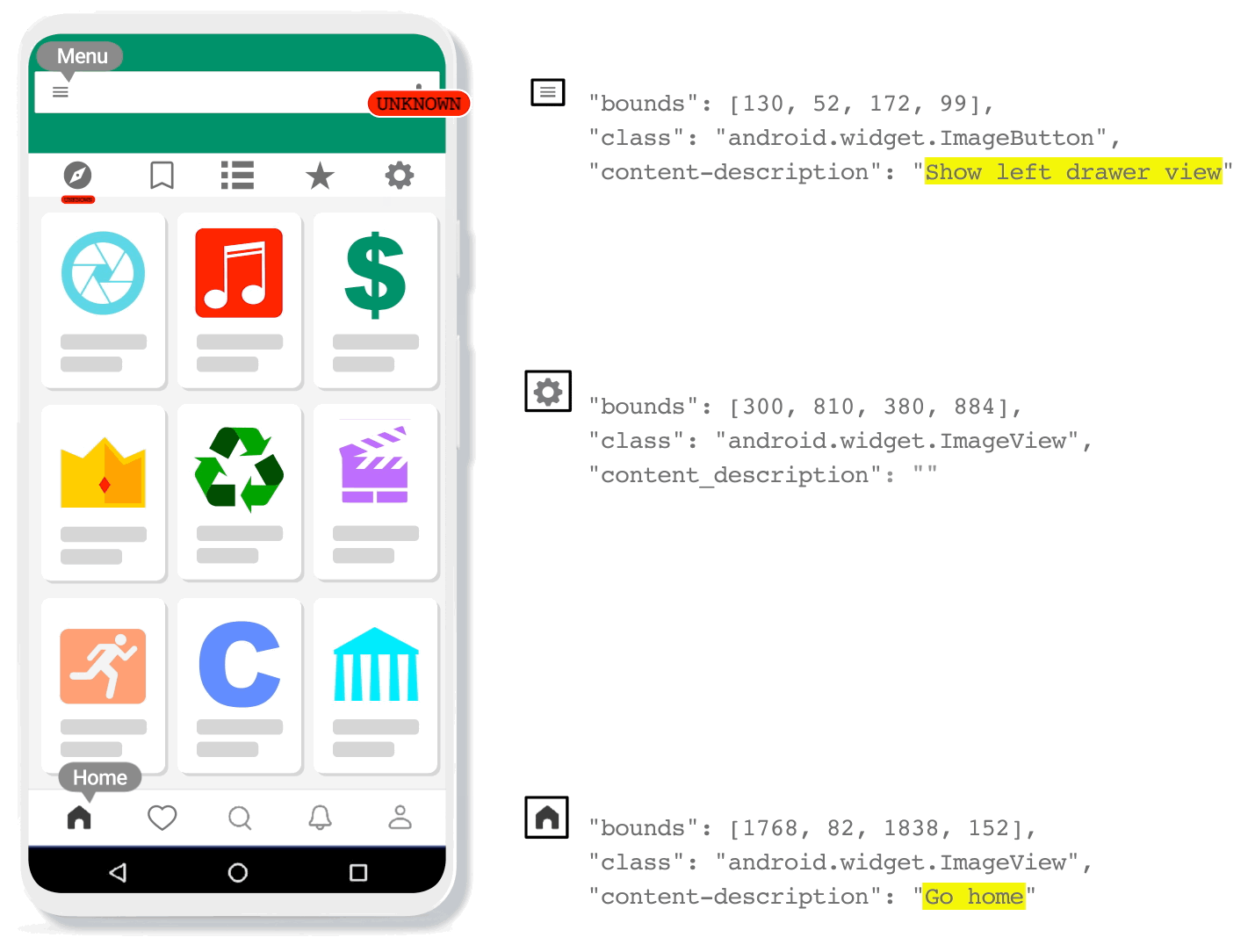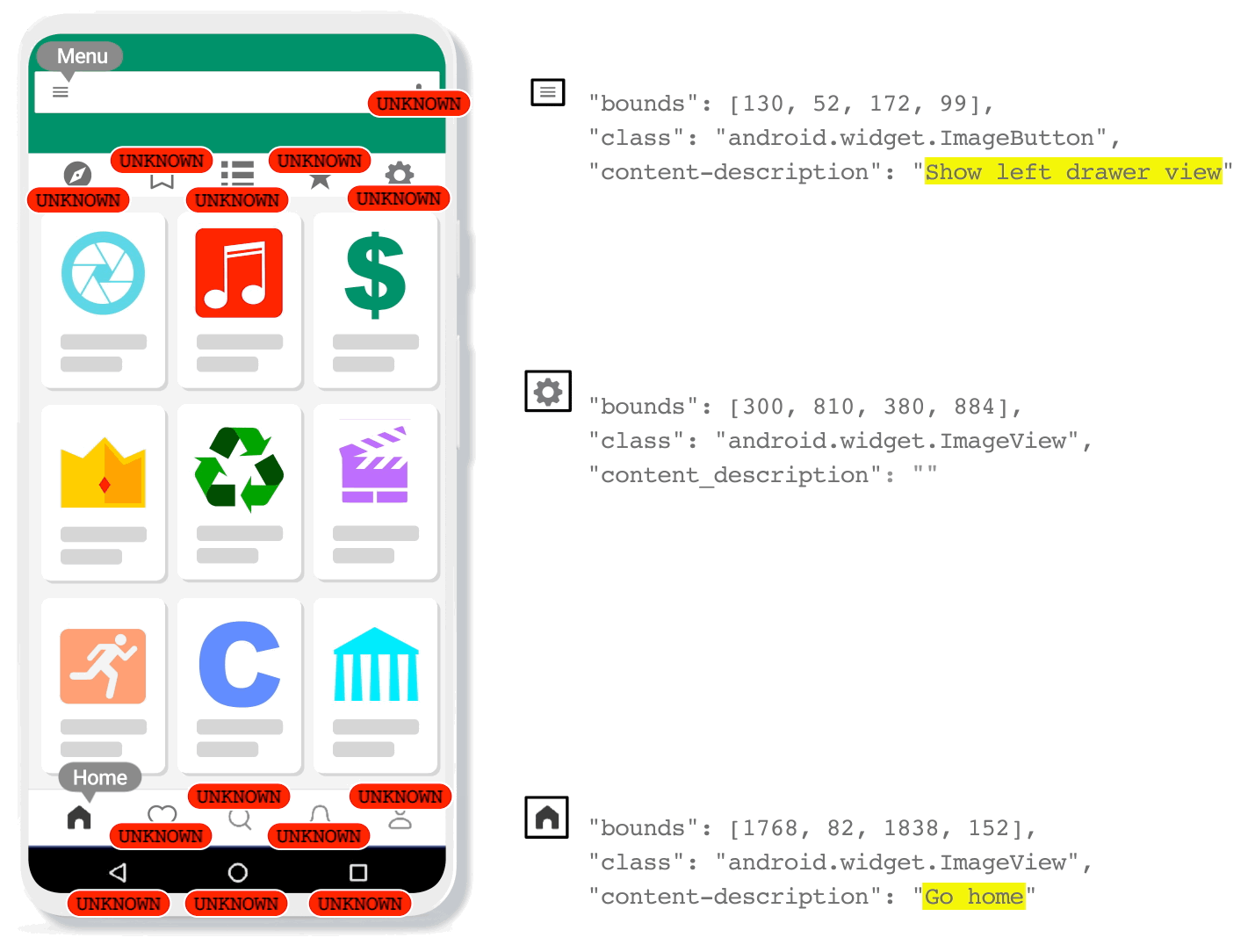
| Voice Access 5.0: the icons detected by IconNet can now be referred to by their names. |
Detecting Icons in Screenshots
From a technical perspective, the problem of detecting icons on app screens is similar to classical object detection, in that individual elements are labelled by the model with their locations and sizes. But, in other ways, it’s quite different. Icons are typically small objects, with relatively basic geometric shapes and a limited range of colors, and app screens widely differ from natural images in that they are more structured and geometrical.
A significant challenge in the development of an on-device UI element detector for Voice Access is that it must be able to run on a wide variety of phones with a range of performance performance capabilities, while preserving the user’s privacy. For a fast user experience, a lightweight model with low inference latency is needed. Because Voice Access needs to use the labels in response to an utterance from a user (e.g., “tap camera”, or “show labels”) inference time needs to be short (<150 ms on a Pixel 3A) with a model size less than 10 MB.
IconNet
IconNet is based on the novel CenterNet architecture, which extracts features from input images and then predicts appropriate bounding box centers and sizes (in the form of heatmaps). CenterNet is particularly suited here because UI elements consist of simple, symmetric geometric shapes, making it easier to identify their centers than for natural images. The total loss used is a combination of a standard L1 loss for the icon sizes and a modified CornerNet Focal loss for the center predictions, the latter of which addresses icon class imbalances between commonly occurring icons (e.g., arrow backward, menu, more, and star) and underrepresented icons (end call, delete, launch apps, etc.)..
After experimenting with several backbones (MobileNet, ResNet, UNet, etc), we selected the most promising server-side architecture — Hourglass — as a starting point for designing a backbone tailored for icon and UI element detection. While this architecture is perfectly suitable for server side models, vanilla Hourglass backbones are not an option for a model that will run on a mobile device, due to their large size and slow inference time. We restricted our on-device network design to a single stack, and drastically reduced the width of the backbone. Furthermore, as the detection of icons relies on more local features (compared to real objects), we could further reduce the depth of the backbone without adversely affecting the performance. Ablation studies convinced us of the importance of skip connections and high resolution features. For example, trimming skip connections in the final layer reduced the mAP by 1.5%, and removing such connections from both the final and penultimate layers resulted in a decline of 3.5% mAP.
 |
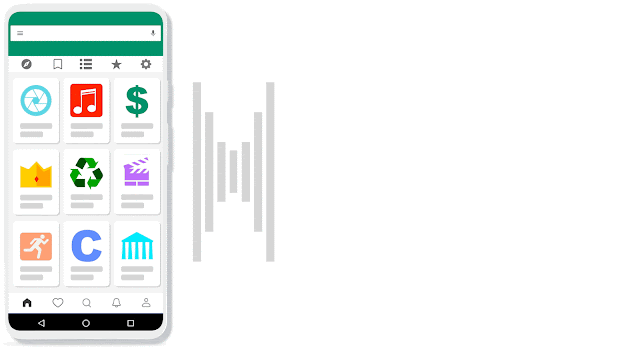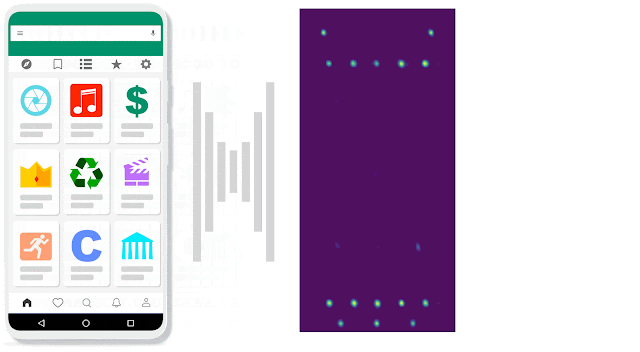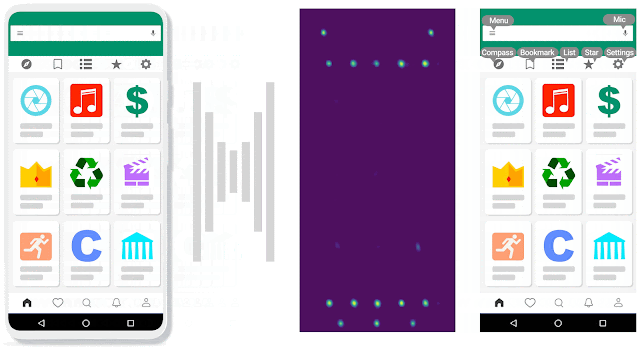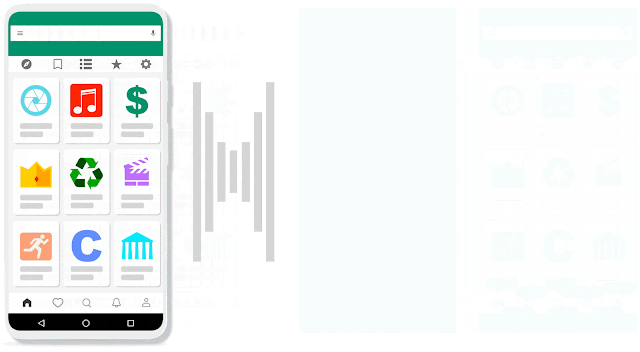
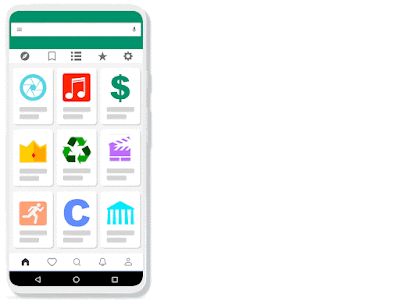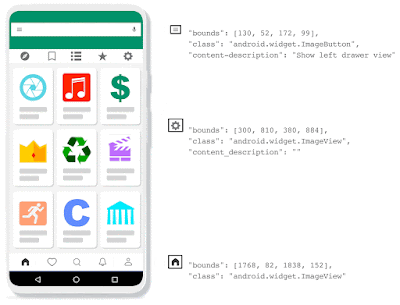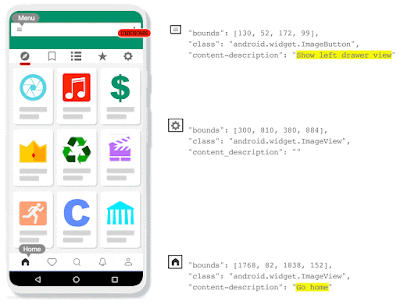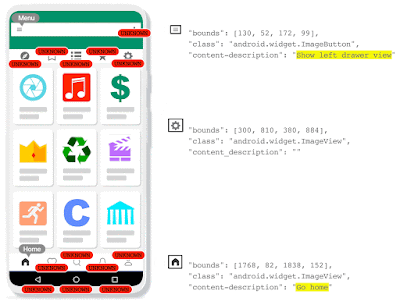
| IconNet analyzes the pixels of the screen and identifies the centers of icons by generating heatmaps, which provide precise information about the position and type of the different types of icons present on the screen. This enables Voice Access users to refer to these elements by their name (e.g., “Tap ‘menu”). |
Model Improvements
Once the backbone architecture was selected, we used neural architecture search (NAS) to explore variations on the network architecture and uncover an optimal set of training and model parameters that would balance model performance (mAP) with latency (FLOPs). Additionally, we used Fine-Grained Stochastic Architecture Search (FiGS) to further refine the backbone design. FiGS is a differentiable architecture search technique that uncovers sparse structures by pruning a candidate architecture and discarding unnecessary connections. This technique allowed us to reduce the model size by 20% without any loss in performance, and by 50% with only a minor drop of 0.3% in mAP.
Improving the quality of the training dataset also played an important role in boosting the model performance. We collected and labeled more than 700K screenshots, and in the process, we streamlined data collection by using heuristics and auxiliary models to identify rarer icons. We also took advantage of data augmentation techniques by enriching existing screenshots with infrequent icons.
To improve the inference time, we modified our model to run using Neural Networks API (NNAPI) on a variety of Qualcomm DSPs available on many mobile phones. For this we converted the model to use 8-bit integer quantization which gives the additional benefit of model size reduction. After some experimentation, we used quantization aware training to quantize the model, while matching the performance of a server-side floating point model. The quantized model results in a 6x speed-up (700ms vs 110ms) and 50% size reduction while losing only ~0.5% mAP compared to the unquantized model.
Results
We use traditional object detection metrics (e.g., mAP) to measure model performance. In addition, to better capture the use case of voice controlled user actions, we define a modified version of a false positive (FP) detection, where we penalize more incorrect detections for icon classes that are present on the screen. For comparing detections with ground truth, we use the center in region of interest (CIROI), another metric we developed for this work, which returns in a positive match when the center of the detected bounding box lies inside the ground truth bounding box. This better captures the Voice Access mode of operation, where actions are performed by tapping anywhere in the region of the UI element of interest.
We compared the IconNet model with various other mobile compatible object detectors, including MobileNetEdgeTPU and SSD MobileNet v2. Experiments showed that for a fixed latency, IconNet outperformed the other models in terms of mAP@CIROI on our internal evaluation set.
| Model | mAP@CIROI | |
| IconNet (Hourglass) | 96% | |
| IconNet (HRNet) | 89% | |
| MobilenetEdgeTPU (AutoML) | 91% | |
| SSD Mobilenet v2 | 88% |
The performance advantage of IconNet persists when considering quantized models and models for a fixed latency budget.
| Models (Quantized) | mAP@CIROI | Model size | Latency* | |||
| IconNet (Currently deployed) | 94.20% | 8.5 MB | 107 ms | |||
| IconNet (XS) | 92.80% | 2.3 MB | 102 ms | |||
| IconNet (S) | 91.70% | 4.4 MB | 45 ms | |||
| MobilenetEdgeTPU (AutoML) | 88.90% | 7.8 MB | 26 ms |
| *Measured on Pixel 3A. |
Conclusion and Future Work
We are constantly working on improving IconNet. Among other things, we are interested in increasing the range of elements supported by IconNet to include any generic UI element, such as images, text, or buttons. We also plan to extend IconNet to differentiate between similar looking icons by identifying their functionality. On the application side, we are hoping to increase the number of apps with valid content descriptions by augmenting developer tools to suggest content descriptions for different UI elements when building applications.
Acknowledgements
This project is the result of joint work with Maria Wang, Tautvydas Misiūnas, Lijuan Liu, Ying Xu, Nevan Wichers, Xiaoxue Zang, Gabriel Schubiner, Abhinav Rastogi, Jindong (JD) Chen, Abhanshu Sharma, Pranav Khaitan, Matt Sharifi and Blaise Aguera y Arcas. We sincerely thank our collaborators Robert Berry, Folawiyo Campbell, Shraman Ray Chaudhuri, Nghi Doan, Elad Eban, Marybeth Fair, Alec Go, Sahil Goel, Tom Hume, Cassandra Luongo, Yair Movshovitz-Attias, James Stout, Gabriel Taubman and Anton Vayvod. We are very grateful to Tom Small for assisting us in preparing the post.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-
March 17, 2026
Improving breast cancer screening workflows with machine learning- Health & Bioscience ·
- Human-Computer Interaction and Visualization