Improving Generalization in Reinforcement Learning using Policy Similarity Embeddings
September 29, 2021
Posted by Rishabh Agarwal, Research Associate, Google Research, Brain Team
Quick links
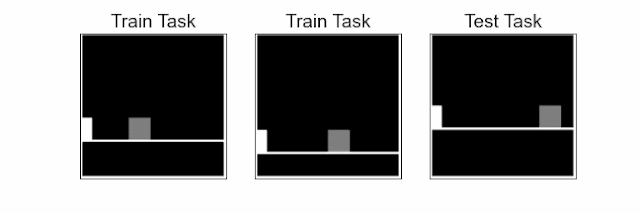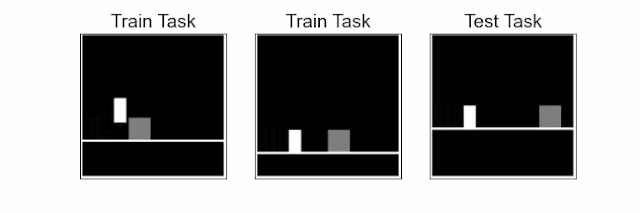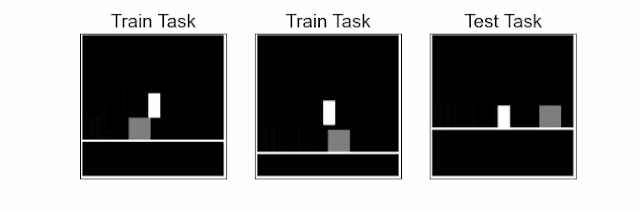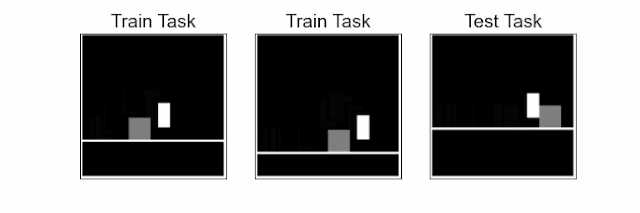
Reinforcement learning (RL) is a sequential decision-making paradigm for training intelligent agents to tackle complex tasks, such as robotic locomotion, playing video games, flying stratospheric balloons and designing hardware chips. While RL agents have shown promising results in a variety of activities, it is difficult to transfer the capabilities of these agents to new tasks, even when these tasks are semantically equivalent. For example, consider a jumping task, where an agent, learning from image observations, needs to jump over an obstacle. Deep RL agents trained on a few of these tasks with varying obstacle positions struggle to successfully jump with obstacles at previously unseen locations.
 |
| Jumping task: The agent (white block), learning from pixels, needs to jump over an obstacle (gray square). The challenge is to generalize to unseen obstacle positions and floor heights in test tasks using a small number of training tasks. In a given task, the agent needs to time the jump precisely, at a specific distance from the obstacle, otherwise it will eventually hit the obstacle. |
In “Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning”, presented as a spotlight at ICLR 2021, we incorporate the inherent sequential structure of RL into the representation learning process to enhance generalization in unseen tasks. This is orthogonal to the predominant approaches before this work, which were typically adapted from supervised learning, and, as such, largely ignore this sequential aspect. Our approach exploits the fact that an agent, when operating in tasks with similar underlying mechanics, exhibits at least short sequences of behaviors that are similar across these tasks.
 |
| Prior work on generalization was typically adapted from supervised learning and revolved around enhancing the learning process. These approaches rarely exploit properties of the sequential aspect such as similarity in actions across temporal observations. |
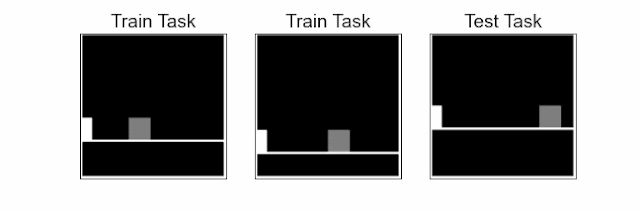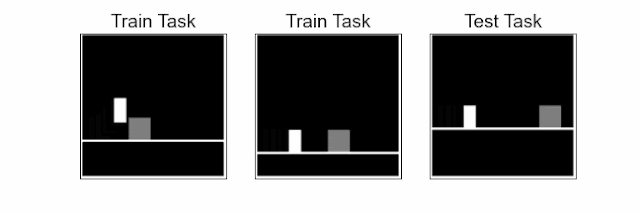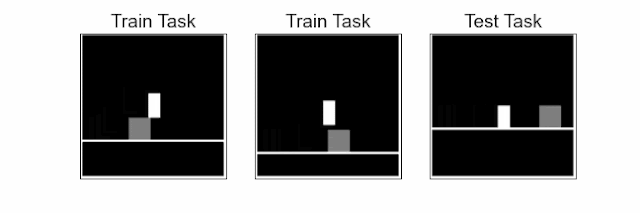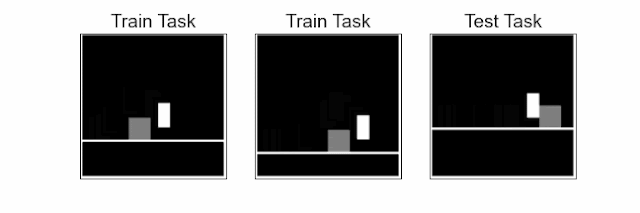
Our approach trains the agent to learn a representation in which states are close when the agent’s optimal behavior in these states and future states are similar. This notion of proximity, which we call behavioral similarity, generalizes to observations across different tasks. To measure behavioral similarity between states across various tasks (e.g., distinct obstacle positions in the jumping task), we introduce the policy similarity metric (PSM), a theoretically motivated state-similarity metric inspired by bisimulation. For example, the image below shows that the agent’s future actions in the two visually different states are the same, making these states similar according to PSM.
 |
| Understanding behavioral similarity. The agent (blue icon) needs to obtain the reward while maintaining distance from danger. Even though the initial states are visually different, they are similar in terms of their optimal behavior at current states as well as future states following the current state. Policy similarity metric (PSM) assigns high similarity to such behaviorally similar states and low similarity to dissimilar states. |
For enhancing generalization, our approach learns state embeddings, which correspond to neural-network–based representations of task states, that bring together behaviorally similar states (such as in the figure above) while pushing behaviorally dissimilar states apart. To do so, we present contrastive metric embeddings (CMEs) that harness the benefits of contrastive learning for learning representations based on a state-similarity metric. We instantiate contrastive embeddings with the policy similarity metric (PSM) to learn policy similarity embeddings (PSEs). PSEs assign similar representations to states with similar behavior at both those states and future states, such as the two initial states shown in the image above.
As shown in the results below, PSEs considerably enhance generalization on the jumping task from pixels mentioned earlier, outperforming prior methods.
| Method | Grid Configuration | ||
| “Wide” | “Narrow” | “Random” | |
| Regularization | 17.2 (2.2) | 10.2 (4.6) | 9.3 ( 5.4) |
| PSEs | 33.6 (10.0) | 9.3 (5.3) | 37.7 (10.4) |
| Data Augmentation | 50.7 (24.2) | 33.7 (11.8) | 71.3 (15.6) |
| Data Aug. + Bisimulation | 41.4 (17.6) | 17.4 (6.7) | 33.4 (15.6) |
| Data Aug. + PSEs | 87.0 (10.1) | 52.4 (5.8) | 83.4 (10.1) |
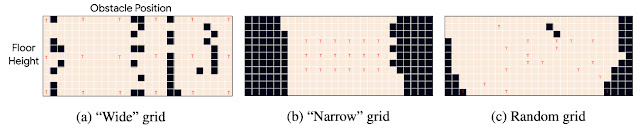
| Jumping Task Results: Percentage (%) of test tasks solved by different methods without and with data augmentation. The “wide”, “narrow”, and “random” grids are configurations shown in the figure below containing 18 training tasks and 268 test tasks. We report average performance across 100 runs with different random initializations, with standard deviation in parentheses. |
 |
| Jumping Task Grid Configurations: Visualization of average performance of PSEs with data augmentation across different configurations. For each grid configuration, the height varies along the y-axis (11 heights) while the obstacle position varies along the x-axis (26 locations). The red letter |
We also visualize the representations learned by PSEs and baseline methods by projecting them to 2D points with UMAP, a popular visualization technique for high dimensional data. As shown by the visualization, PSEs cluster behaviorally-similar states together and dissimilar states apart, unlike prior methods. Furthermore, PSEs partition the states into two sets: (1) all states before the jump and (2) states where actions do not affect the outcome (states after jump).
 |
| Visualizing learned representations. (a) Optimal trajectories on the jumping task (visualized as blocks of different colors) with varying obstacle positions. Points with the same number label correspond to the same distance of the agent from the obstacle, the underlying optimal invariant feature across various jumping tasks. (b-d) We visualize the hidden representations using UMAP, where the color of points indicate the tasks of the corresponding observations. (b) PSEs capture the correct invariant feature as can be seen from points with the same number label being clustered together. That is, after the jump action (numbered block 2), all other actions (non-numbered blocks) are similar as shown by the overlapping curve. Contrary to PSEs, baselines including (c) l2-loss embeddings (instead of contrastive loss) and (d) reward-based bisimulation metrics do not put behaviorally similar states with similar number labels together. Poor generalization for (c, d) is likely due to states with the similar optimal behavior ending up with distant embeddings. |
Conclusion
Overall, this work shows the benefits of exploiting the inherent structure in RL for learning effective representations. Specifically, this work advances generalization in RL by two contributions: the policy similarity metric and contrastive metric embeddings. PSEs combine these two ideas to enhance generalization. Exciting avenues for future work include finding better ways for defining behavior similarity and leveraging this structure for representation learning.
Acknowledgements
This is a joint work with Pablo Samuel Castro, Marlos C. Machado and Marc G. Bellemare. We would also like to thank David Ha, Ankit Anand, Alex Irpan, Rico Jonschkowski, Richard Song, Ofir Nachum, Dale Schuurmans, Aleksandra Faust and Dibya Ghosh for their insightful comments on this work.
Quick links