Improving breast cancer screening workflows with machine learning
March 17, 2026
Lihong Xi, Senior Technical Program Manager, and Daniel Golden, Engineering Manager, Google Research
A large-scale evaluation of our mammography system across multiple screening services demonstrates its potential to enhance cancer detection accuracy and reduce workload within complex double-reading workflows.
Quick links
Breast cancer is the leading cause of death for women aged 35–64 in the UK, but research has conclusively shown that early screening through mammography saves lives. The UK's National Health Service (NHS) Breast Screening Programme currently relies on a double-read workflow — two human mammography readers assess each case, and an arbitration panel reviews the case as needed based on local protocols and the results of the two initial reads. While this rigorous process is highly effective, a 30% shortfall of clinical radiologists — projected to reach 40% by 2028 — threatens the long-term sustainability of the program.
There has been increasing interest in research efforts that explore the potential of AI to help the breast cancer screening process. Building on our earlier work in this area, we partnered with several NHS organizations as part of the Artificial Intelligence in Mammography Screening (AIMS) study to further investigate AI’s potential in this area. As shared earlier this month, we published two companion studies in Nature Cancer that assessed different aspects of an AI-based breast cancer detection system. In the first study, we assessed standalone AI system performance and prospective integration feasibility. In the second, we performed an end-to-end reader study comparing the original double-read and arbitration process to one in which the AI system was used as a second reader. While additional work is needed to prove the effectiveness of this system in prospective clinical practice, these studies strengthen the evidence for the potential benefit of the use of AI in supporting breast cancer screening.
Study 1: Standalone performance and integration feasibility
The first study was split into two phases. In the first phase, we conducted a large-scale multi-center retrospective evaluation of the standalone performance of the AI system. In the second phase, we conducted a prospective, non-interventional deployment study to evaluate the feasibility and challenges associated with integrating a live system into real clinical workflows.
Phase 1: Multicenter standalone performance evaluation
The first, retrospective phase involved mammograms from 125,000 women (115,973 after applying inclusion/exclusion criteria) who were screened at five NHS screening services in the UK. The services covered three different clinical workflows, varying by whether the second reader was blinded to the first and how cases were selected for arbitration (see figure below). AI operating points (the threshold that determines the conservativeness with which the AI flags cases) were determined separately at each screening service to adjust for local differences in screening populations and workflows.
The primary endpoints of the study assessed the sensitivity and specificity of the AI system in detecting cancer compared to the historical (original) first reader for the case. The study used a rigorous ground truth, utilizing a 39-month follow-up window that allowed us to study the AI system's incremental benefit in detecting interval and next-round cancers long before they became clinically symptomatic. In addition to the primary endpoints, the study also assessed performance of the AI system compared to second and consensus readers, as well as lesion-level localization (whether the correct abnormality in the breast was identified) and fairness analyses. By incorporating rigorous lesion-level analysis, our study addressed whether the AI system was successfully localizing the precise regions of interest rather than relying on potentially spurious correlations. This phase of the study was retrospective to enable validation of AI performance at a large scale and did not involve collecting any additional interpretations from human readers or prospective deployment.
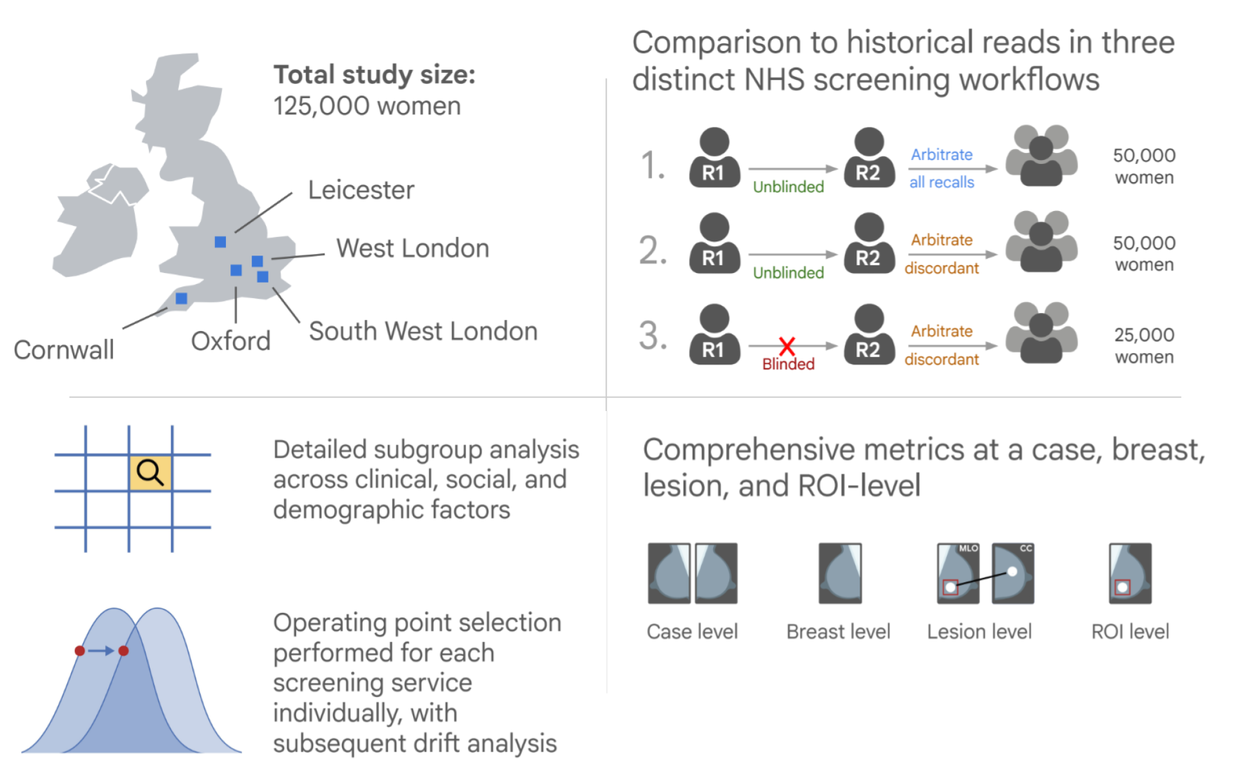
Overall design of the first phase of this study, illustrating retrospective evaluation across five screening services.
Phase 2: Prospective technical feasibility
In the second phase, to understand the practical considerations of incorporating AI into real screening workflows at different clinics, we conducted a prospective non-interventional deployment at 12 screening sites across 2 major screening services in London. This phase focused on demonstrating successful technical integration, assessing automated eligibility checks, and monitoring for distribution shifts.
At the sites, we pseudonymized screening mammograms before passing them to a secure Google Cloud–based AI system for processing. This study also evaluated an iterative operating point calibration process, in which researchers monitored recall rates and adjusted operating points during the study to better calibrate the system to the local environment and ensure operational safety.
Key results
In the standalone performance assessment, the AI system achieved significantly higher sensitivity than the original first human reader without compromising specificity. The overall cancer detection rate rose from from 7.54 to 9.33 per 1,000 women and, crucially, the AI system was able to detect 25% of the interval cancers that were missed in the original double read workflow.
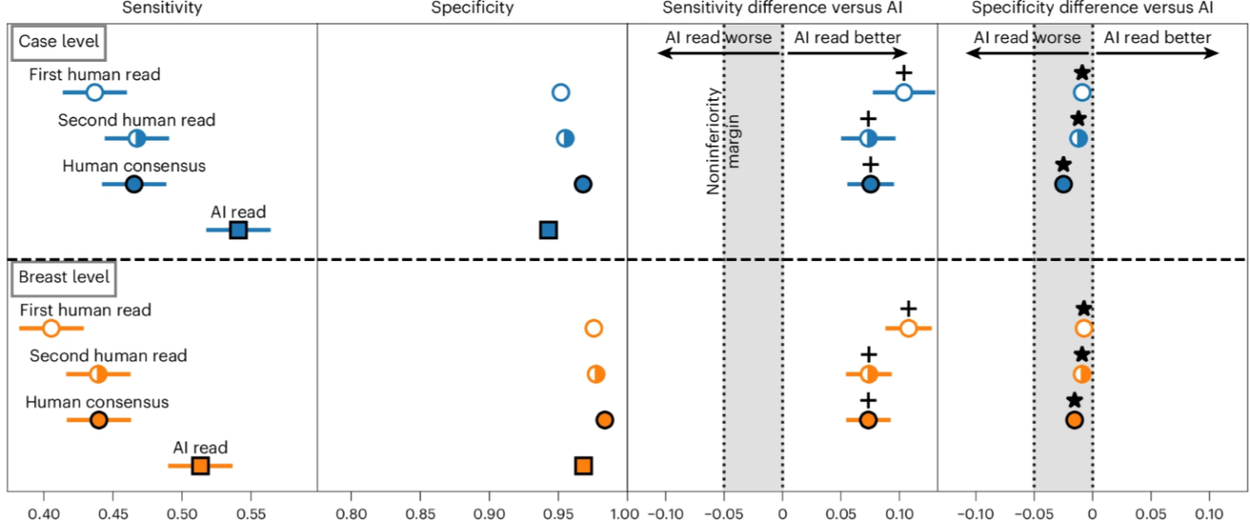
This figure highlights the AI system’s superior sensitivity and non-inferior sensitivity for cancer detection at both the case and breast level.
The AI was particularly adept at detecting invasive cancers, achieving superior sensitivity for these higher risk cancer types than the original human readers. It also performed exceptionally well for women attending their first screen, where it increased detection sensitivity while substantially reducing false positives. An exploratory analysis observed no notable systematic demographic disparities across age, ethnicity, breast density, or socioeconomic status.
In the prospective deployment phase, the AI system was successfully deployed non-interventionally across 12 live NHS screening sites, processing 9,266 cases at two services over a period of approximately two months per service. The time from a completed screen to a completed AI read was fast, with a median time of 17.7 minutes, compared to over 2 days for the first human read. Crucially, the live deployment successfully identified a “distribution shift” between historical training data and modern clinical data. By exposing this drift, the study demonstrates that safe AI deployment may be more effective if accompanied by a rigorous, phased approach to calibrate operating points to local workflows and requirements.
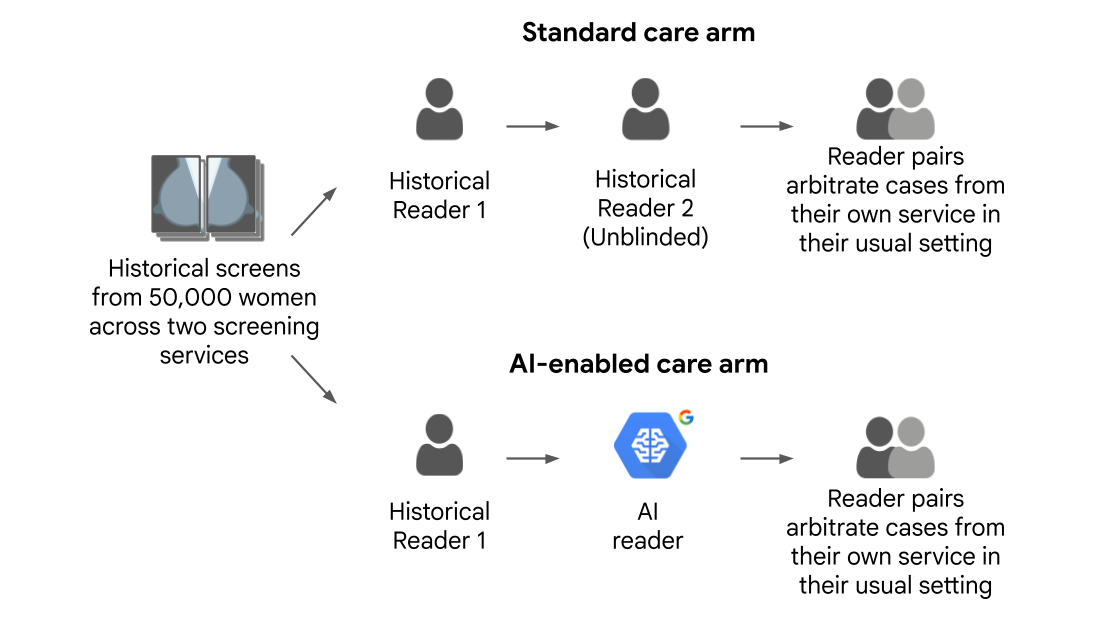
Study 2: Evaluation of integration into a double-reader workflows
While the first study involved a quantitative evaluation of standalone performance, it did not address the question of how human readers would perform when actually interacting with the AI output during the arbitration process. While previous retrospective studies have simulated arbitration, our second study was a large scale reader study where 22 human readers arbitrated thousands of cases using real local screening service rules, providing insight into real-world human-AI interaction. We compared two workflows:
- Standard care arm: Involving the historical decisions of the first and second human readers
- AI-enabled arm: Pairing the historical decision of the first human reader with our AI reader
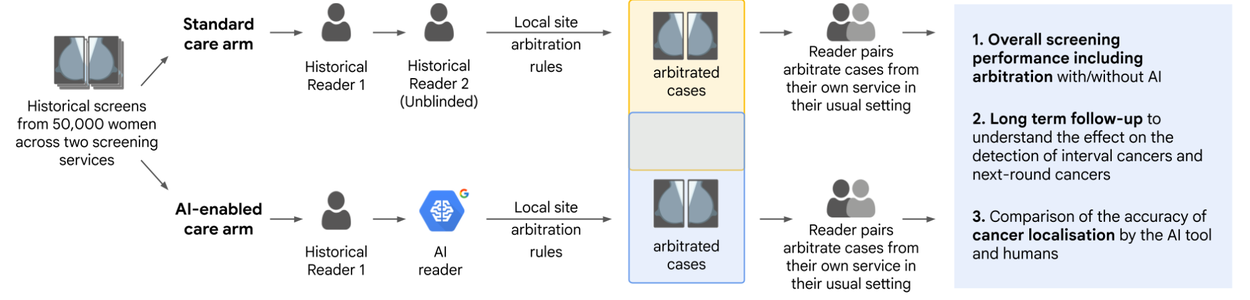
Study design for comparison between traditional human reader-based double-read (standard care) workflow and AI-enabled workflow.
This study involved cases from 50,000 women (45,602 after applying inclusion/exclusion criteria). 22 accredited mammography readers reviewed the 8,732 cases that required arbitration based on the local screening services’ rules — one service dictated arbitration when the two original readers disagreed on the recall recommendation and the other when either original reader recommended recalling. Arbitrators read in pairs to mimic clinical consensus panels. In the standard care arm, arbitrators reviewed the opinions of the two human readers, and in the AI-enabled arm, the arbitrators were shown the first human reader's opinion alongside the AI's output and its highlighted regions of interest. The arbitrators then made a final decision on whether to recall the woman. Analogous to the methodology from our first paper, the study had a robust ground truth involving 39-months of follow-up, allowing researchers to track whether the AI-enabled workflow could detect interval and next-round cancers earlier than standard care. The primary endpoint for the study was noninferiority of case-level cancer detection sensitivity and specificity for the AI-enabled care arm vs. the standard care arm.
Key results
After analyzing the full set of cases, including arbitrated and non-arbitrated cases, we found that the AI-enabled workflow was statistically non-inferior to the traditional two-human workflow in terms of overall sensitivity and specificity after arbitration. Beyond yielding similar outcomes to the traditional workflow, we estimate that the AI-enabled workflow would provide an estimated 46% reduction in total number of required human reads. This is slightly less than 50% because approximately 8.7% of complex cases, such as those involving breast implants, still required two human readers. After accounting for how arbitration reads are more time consuming than reads by the first or second reader, this translates to a 36–44% reduction in overall time spent by readers. This time savings for readers, without commensurate compromises in terms of outcomes, has the potential to help address the crisis of ever-increasing case burdens in the UK.

Visualization of the leftmost portion of the ROC curve showing the sensitivity and specificity of the first human reader, second human reader, AI reader, and consensus (labeled as “arm”) read for each of the two screening services involved in the study. The sensitivity and specificity of the AI-enabled workflow (“AI arm”) was non-inferior to that of the original human workflow (“Human arm”) at both services.
While arbitration successfully filtered out many false positives by both human readers and the AI system, the study revealed an associated downside: human arbitration panels mistakenly overruled the AI's correct recall decisions on 93 positive cancer cases, most of which were hard-to-spot interval and next-round cancers. This result highlights the need for continued research on how human readers interpret and handle AI predictions that may disagree with their own, focusing on both building trust among experts and on improving the explainability of AI results.
Conclusion
Taken together, these studies demonstrate that AI-based screening systems can provide superior cancer detection performance in individual reads and non-inferior performance in the full double reader workflow used in the UK. AI-enabled screening has the potential to significantly reduce overall human reading workload and reading time, while increasing cancer detection rates, particularly for invasive cancers and first-time screens. However, realizing AI's full potential will require overcoming operational issues such as managing increased arbitration volumes, improving model explainability, and actively managing data drift through continuous performance monitoring and local threshold calibration.
Ultimately, this work supports the idea that AI-enabled screening may enable a sustainable healthcare system, where technology and human expertise work in tandem to detect cancer earlier and, most importantly, save more lives.
Acknowledgements
We'd like to thank the many contributors across Google Research, the National Health Service, and our academic partners who made this work possible. We also thank staff at Imperial College London, Royal Surrey NHS Foundation Trust, St George’s University Hospitals, Cancer Research UK, and Cancer Research Horizons, who curated and facilitated access to the OPTIMAM data used in this study. We especially thank the patient and public involvement group for their invaluable advice and input. The AIMS study was funded by a National Institute for Health and Care Research (NIHR) award from the Secretary of State for Health and Social Care. Images were modified from those that appeared in the Nature Cancer publications under a Creative Commons Attribution 4.0 International License. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 17, 2026
Google Research at The Check Up: from healthcare innovation to real-world care settings- Health & Bioscience ·
- Machine Intelligence



