Image-Text Pre-training with Contrastive Captioners
May 24, 2022
Posted by Zirui Wang and Jiahui Yu, Research Scientists, Google Research, Brain Team
Quick links
Oftentimes, machine learning (ML) model developers begin their design using a generic backbone model that is trained at scale and with capabilities transferable to a wide range of downstream tasks. In natural language processing, a number of popular backbone models, including BERT, T5, GPT-3 (sometimes also referred to as “foundation models”), are pre-trained on web-scale data and have demonstrated generic multi-tasking capabilities through zero-shot, few-shot or transfer learning. Compared with training over-specialized individual models, pre-training backbone models for a large number of downstream tasks can amortize the training costs, allowing one to overcome resource limitations when building large scale models.
In computer vision, pioneering work has shown the effectiveness of single-encoder models pre-trained for image classification to capture generic visual representations that are effective for other downstream tasks. More recently, contrastive dual-encoder (CLIP, ALIGN, Florence) and generative encoder-decoder (SimVLM) approaches trained using web-scale noisy image-text pairs have been explored. Dual-encoder models exhibit remarkable zero-shot image classification capabilities but are less effective for joint vision-language understanding. On the other hand, encoder-decoder methods are good at image captioning and visual question answering but cannot perform retrieval-style tasks.
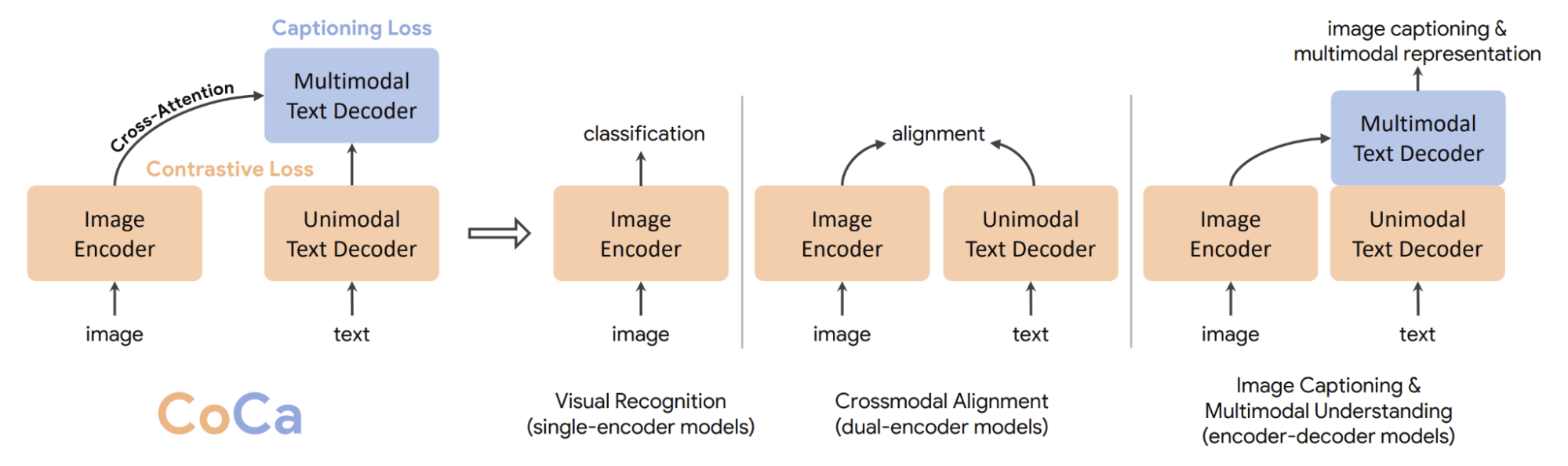
In “CoCa: Contrastive Captioners are Image-Text Foundation Models”, we present a unified vision backbone model called Contrastive Captioner (CoCa). Our model is a novel encoder-decoder approach that simultaneously produces aligned unimodal image and text embeddings and joint multimodal representations, making it flexible enough to be directly applicable for all types of downstream tasks. Specifically, CoCa achieves state-of-the-art results on a series of vision and vision-language tasks spanning vision recognition, cross-modal alignment, and multimodal understanding. Furthermore, it learns highly generic representations so that it can perform as well or better than fully fine-tuned models with zero-shot learning or frozen encoders.
 |
| Overview of Contrastive Captioners (CoCa) compared to single-encoder, dual-encoder and encoder-decoder models. |
Method
We propose CoCa, a unified training framework that combines contrastive loss and captioning loss on a single training data stream consisting of image annotations and noisy image-text pairs, effectively merging single-encoder, dual-encoder and encoder-decoder paradigms.
To this end, we present a novel encoder-decoder architecture where the encoder is a vision transformer (ViT), and the text decoder transformer is decoupled into two parts, a unimodal text decoder and a multimodal text decoder. We skip cross-attention in unimodal decoder layers to encode text-only representations for contrastive loss, and cascade multimodal decoder layers with cross-attention to image encoder outputs to learn multimodal image-text representations for captioning loss. This design maximizes the model's flexibility and universality in accommodating a wide spectrum of tasks, and at the same time, it can be efficiently trained with a single forward and backward propagation for both training objectives, resulting in minimal computational overhead. Thus, the model can be trained end-to-end from scratch with training costs comparable to a naïve encoder-decoder model.
 |
| Illustration of forward propagation used by CoCa for both contrastive and captioning losses. |
Benchmark Results
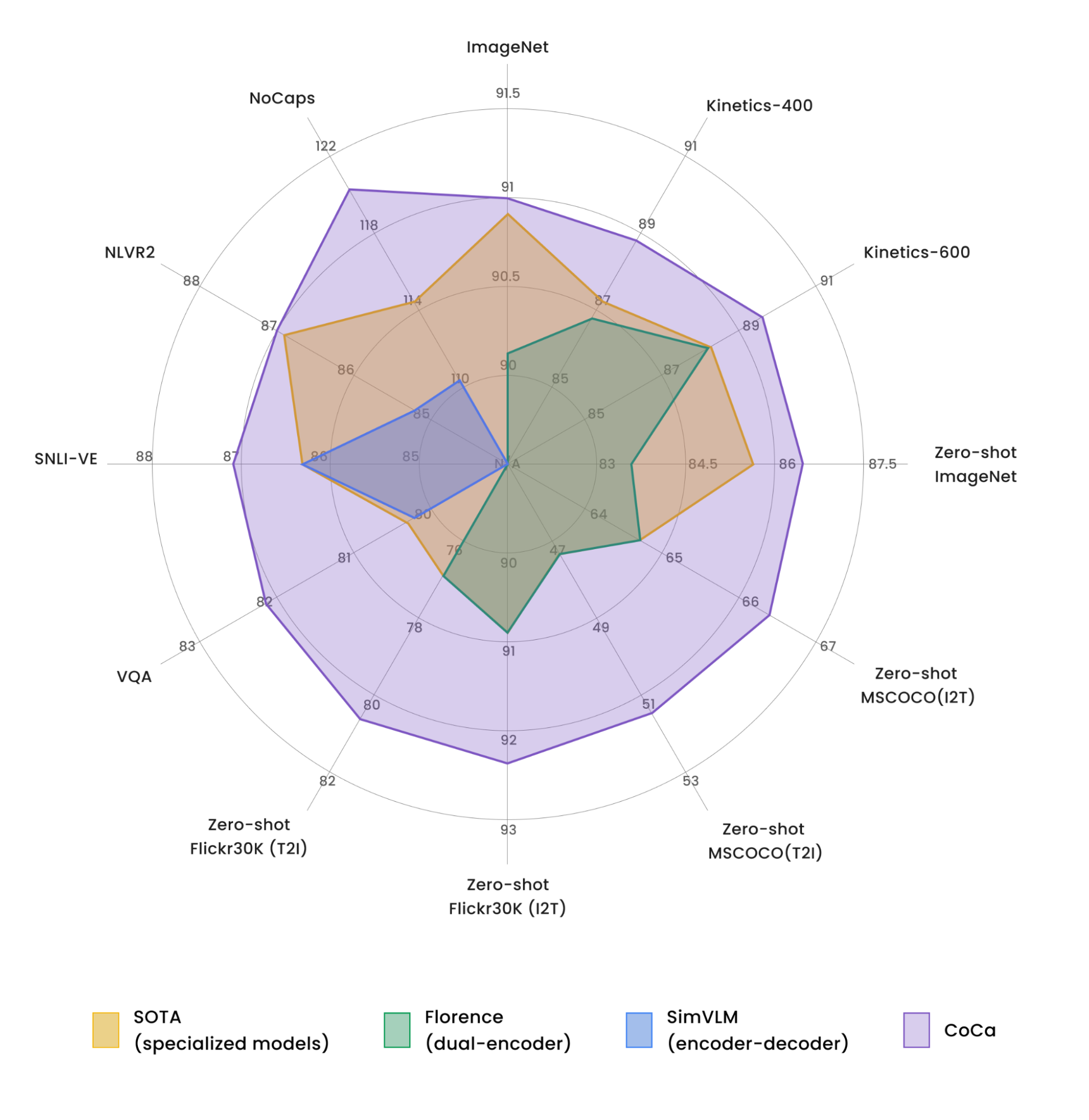
The CoCa model can be directly fine-tuned on many tasks with minimal adaptation. By doing so, our model achieves a series of state-of-the-art results on popular vision and multimodal benchmarks, including (1) visual recognition: ImageNet, Kinetics-400/600/700, and MiT; (2) cross-modal alignment: MS-COCO, Flickr30K, and MSR-VTT; and (3) multimodal understanding: VQA, SNLI-VE, NLVR2, and NoCaps.
 |
| Comparison of CoCa with other image-text backbone models (without task-specific customization) and multiple state-of-the-art task-specialized models. |
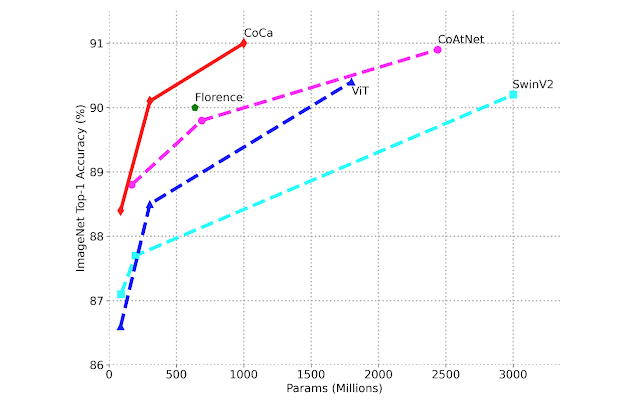
It is noteworthy that CoCa attains these results as a single model adapted for all tasks while often lighter than prior top-performing specialized models. For example, CoCa obtains 91.0% ImageNet top-1 accuracy while using less than half the parameters of prior state-of-the-art models. In addition, CoCa also obtains strong generative capability of high-quality image captions.
 |
| Image classification scaling performance comparing fine-tuned ImageNet top-1 accuracy versus model size. |
 |
| Text captions generated by CoCa with NoCaps images as input. |
Zero-Shot Performance
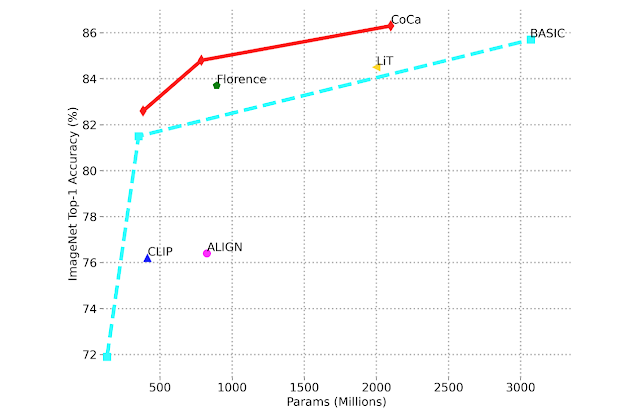
Besides achieving excellent performance with fine-tuning, CoCa also outperforms previous state-of-the-art models on zero-shot learning tasks, including image classification,and cross-modal retrieval. CoCa obtains 86.3% zero-shot accuracy on ImageNet while also robustly outperforming prior models on challenging variant benchmarks, such as ImageNet-A, ImageNet-R, ImageNet-V2, and ImageNet-Sketch. As shown in the figure below, CoCa obtains better zero-shot accuracy with smaller model sizes compared to prior methods.
 |
| Image classification scaling performance comparing zero-shot ImageNet top-1 accuracy versus model size. |
Frozen Encoder Representation
One particularly exciting observation is that CoCa achieves results comparable to the best fine-tuned models using only a frozen visual encoder, in which features extracted after model training are used to train a classifier, rather than the more computationally intensive effort of fine-tuning a model. On ImageNet, a frozen CoCa encoder with a learned classification head obtains 90.6% top-1 accuracy, which is better than the fully fine-tuned performance of existing backbone models (90.1%). We also find this setup to work extremely well for video recognition. We feed sampled video frames into the CoCa frozen image encoder individually, and fuse output features by attentional pooling before applying a learned classifier. This simple approach using a CoCa frozen image encoder achieves video action recognition top-1 accuracy of 88.0% on Kinetics-400 dataset and demonstrates that CoCa learns a highly generic visual representation with the combined training objectives.
 |
| Comparison of Frozen CoCa visual encoder with (multiple) best-performing fine-tuned models. |
Conclusion
We present Contrastive Captioner (CoCa), a novel pre-training paradigm for image-text backbone models. This simple method is widely applicable to many types of vision and vision-language downstream tasks, and obtains state-of-the-art performance with minimal or even no task-specific adaptations.
Acknowledgements
We would like to thank our co-authors Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu who have been involved in all aspects of the project. We also would like to thank Yi-Ting Chen, Kaifeng Chen, Ye Xia, Zhen Li, Chao Jia, Yinfei Yang, Zhengdong Zhang, Wei Han, Yuan Cao, Tao Zhu, Futang Peng, Soham Ghosh, Zihang Dai, Xin Li, Anelia Angelova, Jason Baldridge, Izhak Shafran, Shengyang Dai, Abhijit Ogale, Zhifeng Chen, Claire Cui, Paul Natsev, Tom Duerig for helpful discussions, Andrew Dai for help with contrastive models, Christopher Fifty and Bowen Zhang for help with video models, Yuanzhong Xu for help with model scaling, Lucas Beyer for help with data preparation, Andy Zeng for help with MSR-VTT evaluation, Hieu Pham and Simon Kornblith for help with zero-shot evaluations, Erica Moreira and Victor Gomes for help with resource coordination, Liangliang Cao for proofreading, Tom Small for creating the animations used in this blogpost, and others in the Google Brain team for support throughout this project.
Quick links
Other posts of interest
-

April 29, 2026
Four ways Google Research scientists have been using Empirical Research Assistance- Data Mining & Modeling ·
- General Science ·
- Generative AI ·
- Machine Intelligence
-

April 21, 2026
ReasoningBank: Enabling agents to learn from experience- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 16, 2026
Designing synthetic datasets for the real world: Mechanism design and reasoning from first principles- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing