Identifying Disfluencies in Natural Speech
June 30, 2022
Posted by Dan Walker and Dan Liebling, Software Engineers, Google Research
Quick links
People don’t write in the same way that they speak. Written language is controlled and deliberate, whereas transcripts of spontaneous speech (like interviews) are hard to read because speech is disorganized and less fluent. One aspect that makes speech transcripts particularly difficult to read is disfluency, which includes self-corrections, repetitions, and filled pauses (e.g., words like “umm”, and “you know”). Following is an example of a spoken sentence with disfluencies from the LDC CALLHOME corpus:
It takes some time to understand this sentence — the listener must filter out the extraneous words and resolve all of the nots. Removing the disfluencies makes the sentence much easier to read and understand:
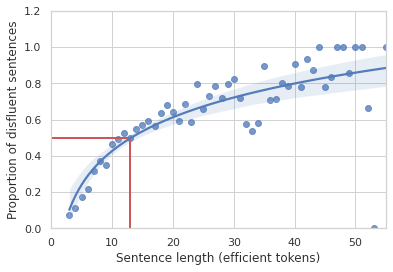
While people generally don't even notice disfluencies in day-to-day conversation, early foundational work in computational linguistics demonstrated how common they are. In 1994, using the Switchboard corpus, Elizabeth Shriberg demonstrated that there is a 50% probability for a sentence of 10–13 words to include a disfluency and that the probability increases with sentence length.
 |
| The proportion of sentences from the Switchboard dataset with at least one disfluency plotted against sentence length measured in non-disfluent (i.e., efficient) tokens in the sentence. The longer a sentence gets, the more likely it is to contain a disfluency. |
In “Teaching BERT to Wait: Balancing Accuracy and Latency for Streaming Disfluency Detection”, we present research findings on how to “clean up” transcripts of spoken text. We create more readable transcripts and captions of human speech by finding and removing disfluencies in people’s speech. Using labeled data, we created machine learning (ML) algorithms that identify disfluencies in human speech. Once those are identified we can remove the extra words to make transcripts more readable. This also improves the performance of natural language processing (NLP) algorithms that work on transcripts of human speech. Our work puts special priority on ensuring that these models are able to run on mobile devices so that we can protect user privacy and preserve performance in scenarios with low connectivity.
Base Model Overview
At the core of our base model is a pre-trained BERTBASE encoder with 108.9 million parameters. We use the standard per-token classifier configuration, with a binary classification head being fed by the sequence encodings for each token.
.png) |
| Illustration of how tokens in text become numerical embeddings, which then lead to output labels. |
We refined the BERT encoder by continuing the pretraining on the comments from the Pushrift Reddit dataset from 2019. Reddit comments are not speech data, but are more informal and conversational than the wiki and book data. This trains the encoder to better understand informal language, but may run the risk of internalizing some of the biases inherent in the data. For our particular use case, however, the model only captures the syntax or overall form of the text, not its content, which avoids potential issues related to semantic-level biases in the data.
We fine-tune our model for disfluency classification on hand-labeled corpora, such as the Switchboard corpus mentioned above. Hyperparameters (batch size, learning rate, number of training epochs, etc.) were optimized using Vizier.
We also produce a range of “small” models for use on mobile devices using a knowledge distillation technique known as “self training”. Our best small model is based on the Small-vocab BERT variant with 3.1 million parameters. This smaller model achieves comparable results to our baseline at 1% the size (in MiB). You can read more about how we achieved this model miniaturization in our 2021 Interspeech paper.
Streaming
Some of the latest use cases for automatic speech transcription include automated live captioning, such as produced by the Android “Live Captions” feature, which automatically transcribes spoken language in audio being played on the device. For disfluency removal to be of use in improving the readability of the captions in this setting, then it must happen quickly and in a stable manner. That is, the model should not change its past predictions as it sees new words in the transcript.
We call this live token-by-token processing streaming. Accurate streaming is difficult because of temporal dependencies; most disfluencies are only recognizable later. For example, a repetition does not actually become a repetition until the second time the word or phrase is said.
To investigate whether our disfluency detection model is effective in streaming applications, we split the utterances in our training set into prefix segments, where only the first N tokens of the utterance were provided at training time, for all values of N up to the full length of the utterance. We evaluated the model simulating a stream of spoken text by feeding prefixes to the models and measuring the performance with several metrics that capture model accuracy, stability, and latency including streaming F1, time to detection (TTD), edit overhead (EO), and average wait time (AWT). We experimented with look-ahead windows of either one or two tokens, allowing the model to “peek” ahead at additional tokens for which the model is not required to produce a prediction. In essence, we’re asking the model to “wait” for one or two more tokens of evidence before making a decision.
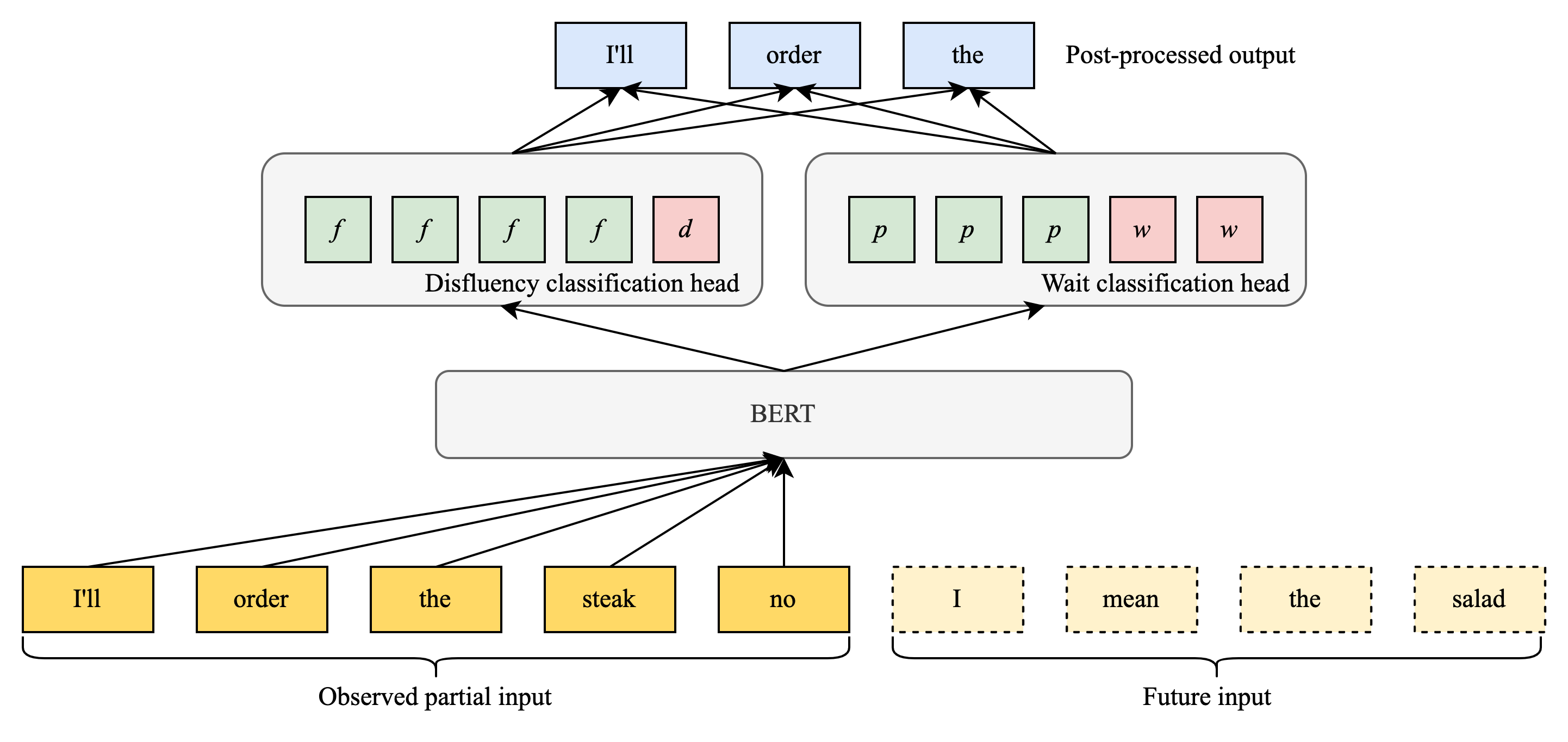
While adding this fixed look-ahead did improve the stability and streaming F1 scores in many contexts, we found that in some cases the label was already clear even without looking ahead to the next token and the model did not necessarily benefit from waiting. Other times, waiting for just one extra token was sufficient. We hypothesized that the model itself could learn when it should wait for more context. Our solution was a modified model architecture that includes a “wait” classification head that decides when the model has seen enough evidence to trust the disfluency classification head.
 |
| Diagram showing how the model labels input tokens as they arrive. The BERT embedding layers feed into two separate classification heads, which are combined for the output. |
We constructed a training loss function that is a weighted sum of three factors:
- The traditional cross-entropy loss for the disfluency classification head
- A cross-entropy term that only considers up to the first token with a “wait” classification
- A latency penalty that discourages the model from waiting too long to make a prediction
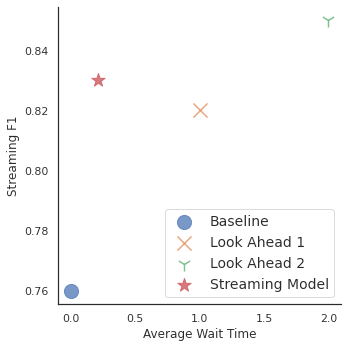
We evaluated this streaming model as well as the standard baseline with no look-ahead and with both 1- and 2-token look-ahead values:
 |
| Graph of the streaming F1 score versus the average wait time in tokens. Three data points indicate F1 scores above 0.82 across multiple wait times. The proposed streaming model achieves near top performance with much shorter wait times than the fixed look ahead models. |
The streaming model achieved a better streaming F1 score than both a standard baseline with no look ahead and a model with a look ahead of 1. It performed nearly as well as the variant with fixed look ahead of 2, but with much less waiting. On average the model waited for only 0.21 tokens of context.
Internationalization
Our best outcomes so far have been with English transcripts. This is mostly due to resourcing issues: while there are a number of relatively large labeled conversational datasets that include disfluencies in English, other languages often have very few such datasets available. So, in order to make disfluency detection models available outside English a method is needed to build models in a way that does not require finding and labeling hundreds of thousands of utterances in each target language. A promising solution is to leverage multi-language versions of BERT to transfer what a model has learned about English disfluencies to other languages in order to achieve similar performance with much less data. This is an area of active research, but we do have some promising results to outline here.
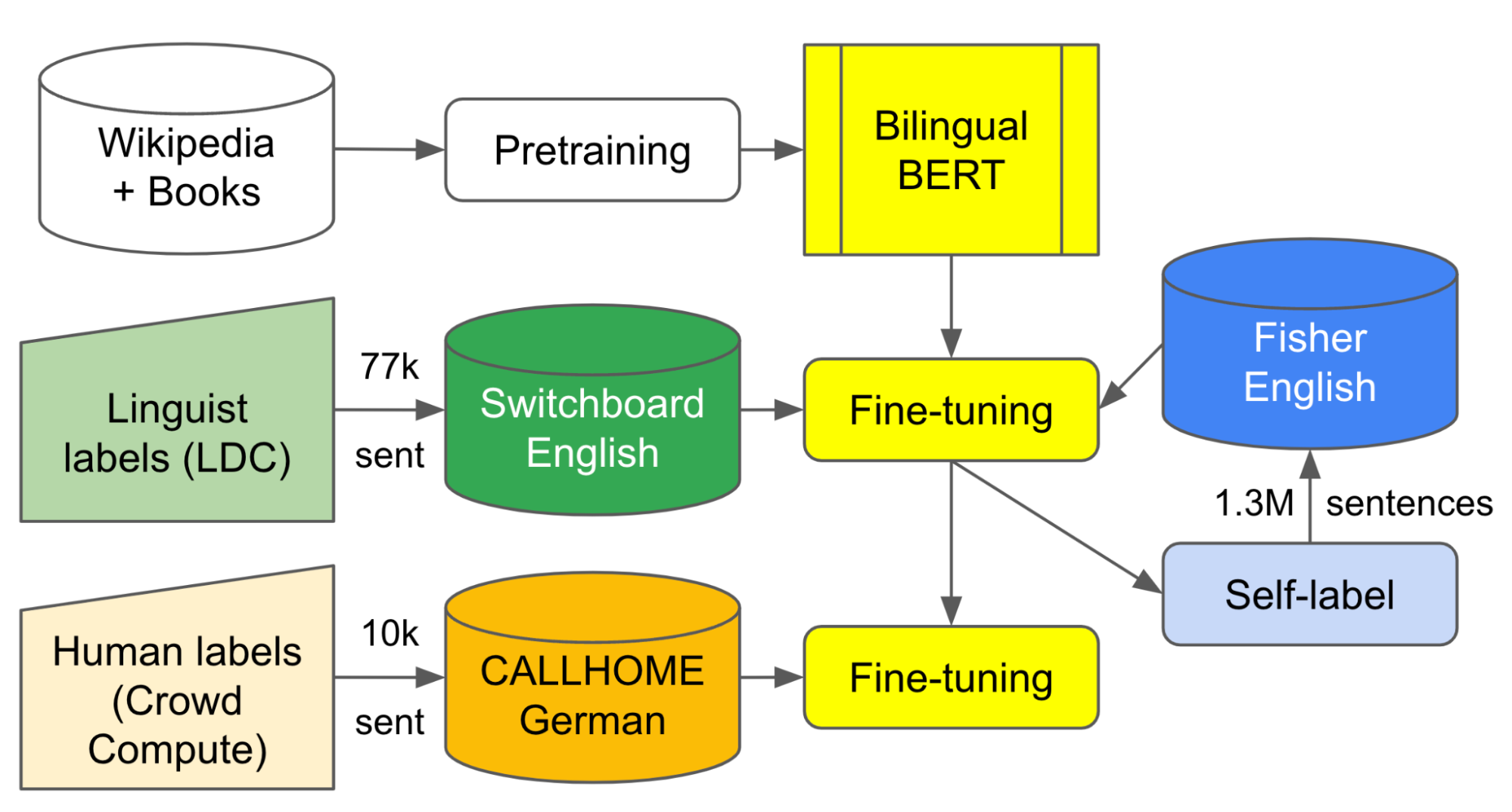
As a first effort to validate this approach, we added labels to about 10,000 lines of dialogue from the German CALLHOME dataset. We then started with the Geotrend English and German Bilingual BERT model (extracted from Multilingual BERT) and fine-tuned it with approximately 77,000 disfluency-labeled English Switchboard examples and 1.3 million examples of self-labeled transcripts from the Fisher Corpus. Then, we did further fine tuning with about 7,500 in-house–labeled examples from the German CALLHOME dataset.
 |
| Diagram illustrating the flow of labeled data and self-trained output in our best multilingual training setup. By training on both English and German data we are able to improve performance via transfer learning. |
Our results indicate that fine-tuning on a large English corpus can produce acceptable precision using zero-shot transfer to similar languages like German, but at least a modest amount of German labels were needed to improve recall from less than 60% to greater than 80%. Two-stage fine-tuning of an English-German bilingual model produced the highest precision and overall F1 score.
| Approach | Precision | Recall | F1 |
| German BERTBASE model fine-tuned on 7,300 human-labeled German CALLHOME examples | 89.1% | 81.3% | 85.0 |
| Same as above but with additional 7,500 self-labeled German CALLHOME examples | 91.5% | 83.3% | 87.2 |
| English/German Bilingual BERTbase model fine-tuned on English Switchboard+Fisher, evaluated on German CALLHOME (zero-shot language transfer) | 87.2% | 59.1% | 70.4 |
| Same as above but subsequently fine-tuned with 14,800 German CALLHOME (human- and self-labeled) examples | 95.5% | 82.6% | 88.6 |
Conclusion
Cleaning up disfluencies from transcripts can improve not just their readability for people, but also the performance of other models that consume transcripts. We demonstrate effective methods for identifying disfluencies and expand our disfluency model to resource-constrained environments, new languages, and more interactive use cases.
Acknowledgements
Thank you to Vicky Zayats, Johann Rocholl, Angelica Chen, Noah Murad, Dirk Padfield, and Preeti Mohan for writing the code, running the experiments, and composing the papers discussed here. We also thank our technical product manager Aaron Schneider, Bobby Tran from the Cerebra Data Ops team, and Chetan Gupta from Speech Data Ops for their support obtaining additional data labels.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
.png)