
Human I/O: Detecting situational impairments with large language models
June 14, 2024
Xingyu Bruce Liu, Student Researcher, and Ruofei Du, Interactive Perception & Graphics Lead, Google Augmented Reality
Quick links
Every day, we encounter temporary challenges that can affect our abilities to respond to different situations. These challenges, known as situationally induced impairments and disabilities (SIIDs), can be caused by various environmental factors like noise, lighting, temperature, stress, and even social norms. For example, imagine you're in a loud restaurant and you miss an important phone call because you simply could not hear your phone ring. Or picture yourself trying to respond to a text message while washing dishes; your wet hands and the task at hand make it hard to type a reply. These everyday scenarios show how our surroundings can momentarily reduce our physical, cognitive, or emotional abilities, leading to frustrating experiences.
In addition, situational impairments can vary greatly and change frequently, which makes it difficult to apply one-size-fits-all solutions that help users with their needs in real-time. For example, think about a typical morning routine: while brushing their teeth, someone might not be able to use voice commands with their smart devices. When washing their face, it could be hard to see and respond to important text messages. And while using a hairdryer, it might be difficult to hear any phone notifications. Even though various efforts have created solutions tailored for specific situations like these, creating manual solutions for every possible situation and combination of challenges isn't really feasible and doesn't work well on a large scale.
In “Human I/O: Towards a Unified Approach to Detecting Situational Impairments”, which received a Best Paper Honorable Mention Award at CHI 2024, we introduce a generalizable and extensible framework for detecting SIIDs. Rather than devising individual models for activities like face-washing, tooth-brushing, or hair-drying, Human Input/Output (Human I/O) universally assesses the availability of a user’s vision (e.g., to read text messages, watch videos), hearing (e.g., to hear notifications, phone calls), vocal (e.g., to have a conversation, use Google Assistant), and hand (e.g., to use touch screen, gesture control) input/output interaction channels. We describe how Human I/O leverages egocentric vision, multimodal sensing, and reasoning with large language models (LLMs) to achieve an 82% accuracy in availability prediction across 60 in-the-wild egocentric video recordings in 32 different scenarios, and validate it as an interactive system in a lab study with ten participants. We also open-sourced the code.
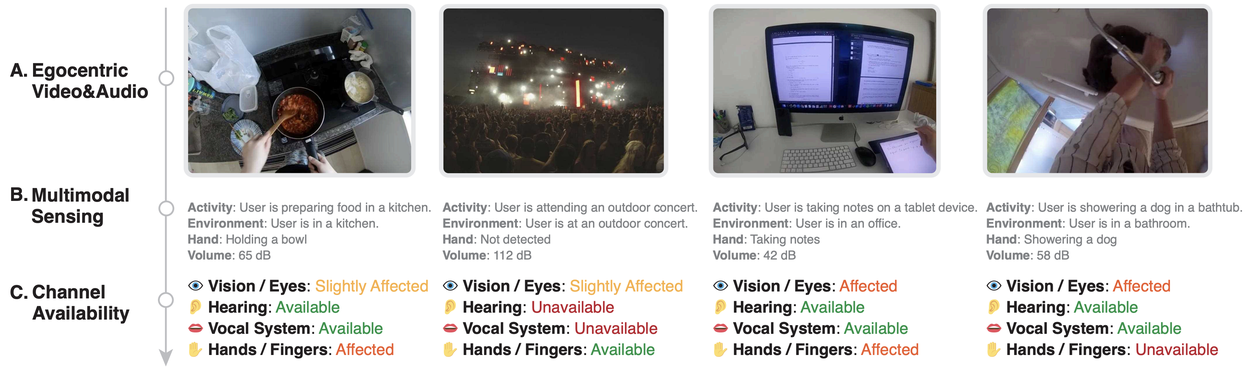
Leveraging multi-modal AI and large language models, we built a pipeline to computationally model these human input/output channels and achieved good real-time performance.
Formative study
Prior to developing Human I/O, we conducted a formative study involving ten participants to better understand how different impairments affected their interaction with technology. Our findings highlighted the need for a system that could dynamically adapt to the varying levels of channel availability rather than treating availability as a binary state. Specifically, Human I/O distinguishes between four levels of channel availability, which are crucial for understanding the degree to which a user can engage with their device. These levels include:
- Available
- The channel is currently not involved in any activity, or constrained by any environmental factors. It takes low to zero effort to use the channel to complete a new task.
- Example: A user is sitting at their desk with their hands free, eyes not engaged in a task, and no background noise interfering with their hearing or speech.
- Slightly affected
- The channel is engaged in an activity or constrained by an environmental factor. Given a new task that requires the channel, users can multitask, easily pause and resume the current activity, or easily overcome the situation.
- Example: A user is holding a remote control, which can be set aside to free up their hand for another task.
- Affected
- The channel is involved in an activity or constrained by an environmental factor. Given a new task, the user may experience inconvenience or require some effort to use the channel.
- Example: A user is using both hands to carry groceries, making it challenging to use their hands for other tasks without putting the bags down first.
- Unavailable
- The channel is completely unavailable due to an activity or environmental factor, and the user cannot use it for a new task without substantial changes, significant adaptation or changing the environment.
- Example: A user is attending a loud concert, making it impossible for them to hear incoming notifications or have a conversation.
Human I/O system pipeline
The Human I/O system incorporates a pipeline that streams real-time data, processes it to understand the context, and applies reasoning with LLMs to predict channel availability. Here’s a deeper look into the three core components of the system: data streaming, processing module, and reasoning module.
Data streaming
The system begins by streaming real-time video and audio data through an egocentric device that has a camera and microphone. This setup provides a first-person view of the user's environment, capturing both visual and auditory details necessary for assessing the context.
Processing module
This module processes the raw data to extract the following information:
- Activity recognition: Utilizes computer vision to identify the user's current activities, such as cooking or washing dishes.
- Environment assessment: Determines the setting, such as noisy or quiet environments, using both audio and visual data.
- Direct sensing: Detects finer details, such as whether the user’s hands are occupied, ambient noise levels, and lighting conditions.
Reasoning module
The final stage involves analyzing the structured data from the processing module to predict the availability of input/output channels using an LLM with chain-of-thought reasoning. This module processes contextual information and determines how impaired each channel is, guiding how the device should adapt its interactions accordingly. By integrating data streaming, processing, and reasoning, Human I/O dynamically predicts the availability of the user’s input and output channels. We further incorporate a smoothing algorithm for enhanced system stability.
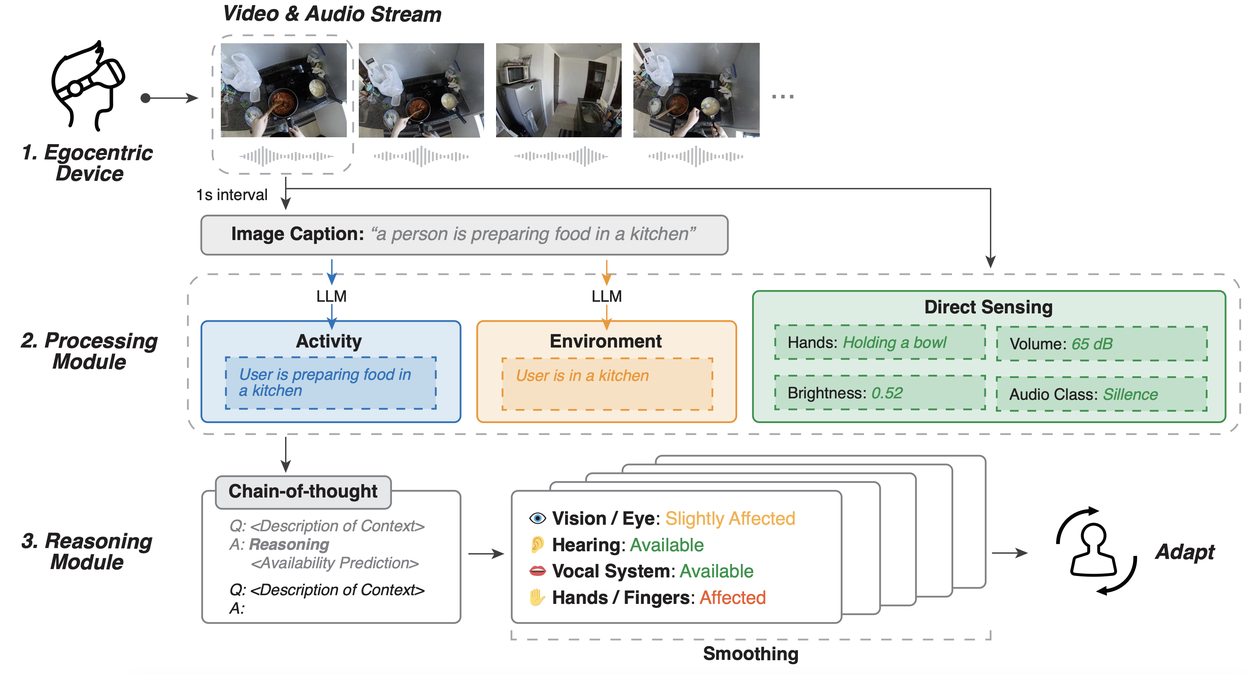
The Human I/O pipeline comprises an egocentric device, processing modules that obtains activity, environment, and sensor data, and reasoning module that predicts human channel availability.
Evaluation
To validate Human I/O, we conducted an evaluation with 300 clips selected from 60 in-the-wild egocentric video recordings. The system archives a 0.22 mean absolute error (MAE) and an 82% accuracy in predicting channel availability, with 96% of predictions within one step of the actual availability level. These low MAE values indicate that our system’s predictions closely align with the actual availability, with deviations being less than a third of the actual level on average.
In addition, we conducted an ablation study by introducing Human I/O Lite, which replaces the chain-of-thought reasoning module with a one-shot prompt. For Human I/O Lite, we observe overall slightly inferior performance compared to the full model. However, the MAE for Human I/O Lite is still at a low level around 0.44, showing a promising ability to predict SIIDs even with reduced computational resources.
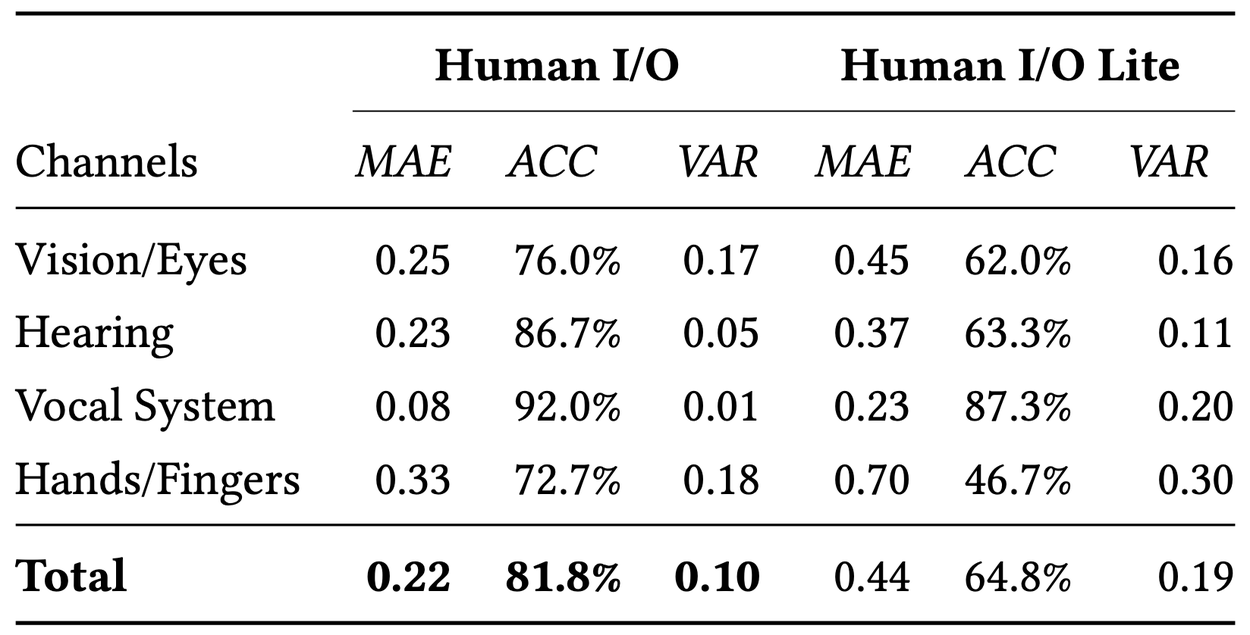
Technical evaluation of Human I/O and Human I/O Lite. We report the MAE, average classification accuracy (ACC), and average intra-video variance (VAR) for four channels and the overall results. Our system estimates availability levels with small margins of error and variance. In Human I/O, 96.0% of predictions are within a discrepancy of 1 step from the actual availability value.
Additionally, a user study with ten participants showed that Human I/O significantly reduced effort and enhanced user experience in the presence of SIIDs. Participants particularly valued how the system adapted to their real-time context, making digital interactions more seamless and less disruptive. Participants completed the NASA Task Load Index questionnaire, assessing mental demand, physical demand, temporal demand, overall performance, effort, and frustration level on a 7-point scale (from 1–Lowest to 7–Highest). Results suggest that Human I/O significantly reduces effort and improves user experience in the presence of SIIDs. Furthermore, Human I/O users reported a raised awareness of SIIDs that opened up new interaction possibilities.
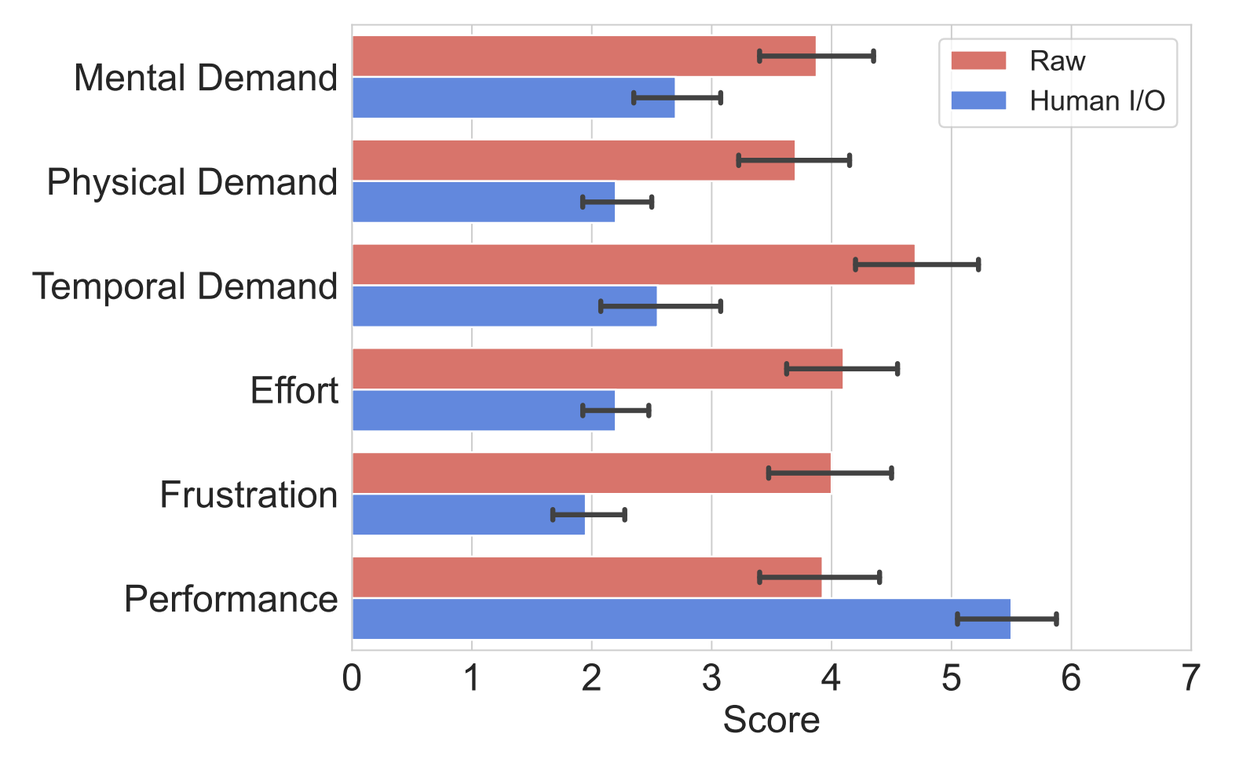
Participants’ ratings to Task Load Index questions (on a scale of 1–low to 7–high) for their experience with SIIDs with and without Human I/O in user study. All rating differences are statistically significant with 𝑝 < 0.001 via Wilcoxon signed-rank tests.
Conclusion & future work
Human I/O represents a leap forward in our ability to interact with technology in a context-aware and adaptive manner. By understanding and predicting the availability of our input and output channels, it paves the way for smarter, more intuitive user interfaces that can enhance productivity and accessibility for everyone, regardless of the situational challenges they face.
Meanwhile, maintaining privacy and upholding ethical standards are crucial in the design and deployment of SIIDs systems with active cameras and microphones on wearables. For example, a combination of on-device inference (e.g., Gemini Nano) and federated learning can forestall potential data breaches. Future research may incorporate more sensing techniques, such as depth sensing, ultra-wideband, and eye tracking, to provide users with finer controls over how their devices adapt to their changing needs and situations.
We envision this technology not only improving individual device interactions but also serving as a foundation for future developments in ubiquitous computing.
Acknowledgements
This research has been largely conducted by Xingyu Bruce Liu, Jiahao Nick Li, David Kim, Xiang 'Anthony' Chen, and Ruofei Du. We would like to extend our thanks to Guru Somadder, Adarsh Kowdle, Siyou Pei, Xiuxiu Yuan, Alex Olwal, Eric Turner, and Federico Tombari for providing feedback or assistance for the manuscript and the blog post.
Quick links
Other posts of interest
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-
March 17, 2026
Improving breast cancer screening workflows with machine learning- Health & Bioscience ·
- Human-Computer Interaction and Visualization

Leveraging multi-modal AI and large language models, we built a pipeline to computationally model these human input/output channels and achieved good real-time performance.
The Human I/O pipeline comprises an egocentric device, processing modules that obtains activity, environment, and sensor data, and reasoning module that predicts human channel availability.

Technical evaluation of Human I/O and Human I/O Lite. We report the MAE, average classification accuracy (ACC), and average intra-video variance (VAR) for four channels and the overall results. Our system estimates availability levels with small margins of error and variance. In Human I/O, 96.0% of predictions are within a discrepancy of 1 step from the actual availability value.

Participants’ ratings to Task Load Index questions (on a scale of 1–low to 7–high) for their experience with SIIDs with and without Human I/O in user study. All rating differences are statistically significant with 𝑝 < 0.001 via Wilcoxon signed-rank tests.