How to measure translation quality in your user interfaces
October 30, 2015
Posted by Javier Bargas-Avila, User Experience Research at Google
Quick links
Worldwide, there are about 200 languages that are spoken by at least 3 million people. In this global context, software developers are required to translate their user interfaces into many languages. While graphical user interfaces have evolved substantially when compared to text-based user interfaces, they still rely heavily on textual information. The perceived language quality of translated user interfaces (UIs) can have a significant impact on the overall quality and usability of a product. But how can software developers and product managers learn more about the quality of a translation when they don’t speak the language themselves?
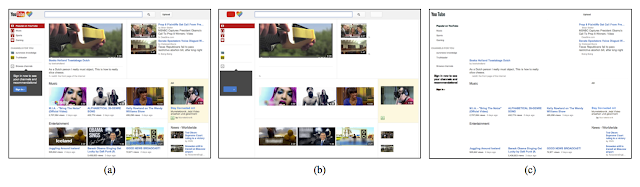
Key information in interaction elements and content are mostly conveyed through text. This aspect can be illustrated by removing text elements from a UI, as shown in the the figure below.
 |
| Three versions of the YouTube UI: (a) the original, (b) YouTube without text elements, and (c) YouTube without graphic elements. It gets apparent how the textless version is stripped of the most useful information: it is almost impossible to choose a video to watch and navigating the site is impossible. |
UIs are generally developed in one source language and translated afterwards string by string. The process of translation is prone to errors and might introduce problems that are not present in the source. These problems are most often due to difficulties in the translation process. For example, the word “auto” can be translated to French as automatique (automatic) or automobile (car), which obviously has a different meaning. Translators might chose the wrong term if context is missing during the process. Another problem arises from words that behave as a verb when placed in a button or as a noun if part of a label. For example, “access” can stand for “you have access” (as a label) or “you can request access” (as a button).
Further pitfalls are gender, prepositions without context or other characteristics of the source text that might influence translation. These problems sometimes even get aggravated by the fact that translations are made by different linguists at different points in time. Such mistranslations might not only negatively affect trustworthiness and brand perception, but also the acceptance of the product and its perceived usefulness.
This work was motivated by the fact that in 2012, the YouTube internationalization team had anecdotal evidence which suggested that some language versions of YouTube might benefit from improvement efforts. While expert evaluations led to significant improvements of text quality, these evaluations were expensive and time-consuming. Therefore, it was decided to develop a survey that enables users to provide feedback about the language quality of the user interface to allow a scalable way of gathering quantitative data about language quality.
The Language Quality Survey (LQS) contains 10 questions about language quality. The first five questions form the factor “Readability”, which describes how natural and smooth to read the used text is. For instance, one question targets ease of understanding (“How easy or difficult to understand is the text used in the [product name] interface?”). Questions 6 to 9 summarize the frequency of (in)consistencies in the text, called “Linguistic Correctness”. The full survey can be found in the publication.
Case study: applying the LQS in the field
As the LQS was developed to discover problematic translations of the YouTube interface and allow focused quality improvement efforts, it was made available in over 60 languages and data were gathered for all these versions of the YouTube interface. To understand the quality of each UI version, we compared the results for the translated versions to the source language (here: US-English). We inspected first the global item, in combination with Linguistic Correctness and Readability. Second, we inspected each item separately, to understand which notion of Linguistic Correctness or Readability showed worse (or better) values. Here are some results:
- The data revealed that about one third of the languages showed subpar language quality levels, when compared to the source language.
- To understand the source of these problems and fix them, we analyzed the qualitative feedback users had provided (every time someone selected the lower two end scale points, pointing at a problem in the language, a text box was surfaced, asking them to provide examples or links to illustrate the issues).
- The analysis of these comments provided linguists with valuable feedback of various kinds. For instance, users pointed to confusing terminology, untranslated words that were missed during translation, typographical or grammatical problems, words that were translated but are commonly used in English, or screenshots in help pages that were in English but needed to be localized. Some users also pointed to readability aspects such as sections with old fashioned or too formal tone as well as too informal translations, complex technical or legal wordings, unnatural translations or rather lengthy sections of text. In some languages users also pointed to text that was too small or criticized the readability of the font that was used.
- In parallel, in-depth expert reviews (so-called “language find-its”) were organized. In these sessions, a group of experts for each language met and screened all of YouTube to discover aspects of the language that could be improved and decided on concrete actions to fix them. By using the LQS data to select target languages, it was possible to reduce the number of language find-its to about one third of the original estimation (if all languages had been screened).
Quick links
Other posts of interest
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-
March 17, 2026
Improving breast cancer screening workflows with machine learning- Health & Bioscience ·
- Human-Computer Interaction and Visualization
-

February 10, 2026
Beyond one-on-one: Authoring, simulating, and testing dynamic human-AI group conversations- Human-Computer Interaction and Visualization ·
- Machine Intelligence
×
❮
❯
