High-Quality, Robust and Responsible Direct Speech-to-Speech Translation
September 23, 2021
Posted by Ye Jia and Michelle Tadmor Ramanovich, Software Engineers, Google Research
Quick links
Speech-to-speech translation (S2ST) is key to breaking down language barriers between people all over the world. Automatic S2ST systems are typically composed of a cascade of speech recognition, machine translation, and speech synthesis subsystems. However, such cascade systems may suffer from longer latency, loss of information (especially paralinguistic and non-linguistic information), and compounding errors between subsystems.
In 2019, we introduced Translatotron, the first ever model that was able to directly translate speech between two languages. This direct S2ST model was able to be efficiently trained end-to-end and also had the unique capability of retaining the source speaker’s voice (which is non-linguistic information) in the translated speech. However, despite its ability to produce natural sounding translated speech in high fidelity, it still underperformed compared to a strong baseline cascade S2ST system (e.g., composed of a direct speech-to-text translation model [1, 2] followed by a Tacotron 2 TTS model).
In “Translatotron 2: Robust direct speech-to-speech translation”, we describe an improved version of Translatotron that significantly improves performance while also applying a new method for transferring the source speakers’ voices to the translated speech. The revised approach to voice transference is successful even when the input speech contains multiple speakers speaking in turns while also reducing the potential for misuse and better aligning with our AI Principles. Experiments on three different corpora consistently showed that Translatotron 2 outperforms the original Translatotron by a large margin on translation quality, speech naturalness, and speech robustness.
Translatotron 2
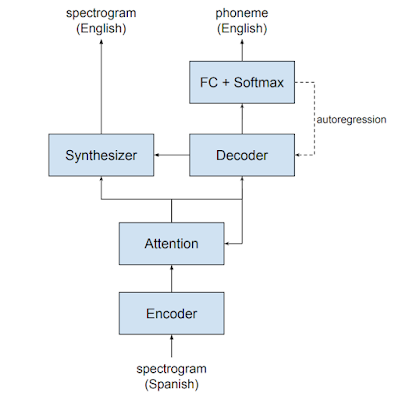
Translatotron 2 is composed of four major components: a speech encoder, a target phoneme decoder, a target speech synthesizer, and an attention module that connects them together. The combination of the encoder, the attention module, and the decoder is similar to a typical direct speech-to-text translation (ST) model. The synthesizer is conditioned on the output from both the decoder and the attention.
 |
| Model architecture of Translatotron 2 (for translating Spanish speech into English speech). |
There are three novel changes between Translatotron and Translatotron 2 that are key factors in improving the performance:
- While the output from the target phoneme decoder is used only as an auxiliary loss in the original Translatotron, it is one of the inputs to the spectrogram synthesizer in Translatotron 2. This strong conditioning makes Translatotron 2 easier to train and yields better performance.
- The spectrogram synthesizer in the original Translatotron is attention-based, similar to the Tacotron 2 TTS model, and as a consequence, it also suffers from the robustness issues exhibited by Tacotron 2. In contrast, the spectrogram synthesizer employed in Translatotron 2 is duration-based, similar to that used by Non-Attentive Tacotron, which drastically improves the robustness of the synthesized speech.
- Both Translatotron and Translatotron 2 use an attention-based connection to the encoded source speech. However, in Translatotron 2, this attention is driven by the phoneme decoder instead of the spectrogram synthesizer. This ensures the acoustic information that the spectrogram synthesizer sees is aligned with the translated content that it’s synthesizing, which helps retain each speaker’s voice across speaker turns.
More Powerful and Responsible Voice Retention
The original Translatotron was able to retain the source speaker's voice in the translated speech, by conditioning its decoder on a speaker embedding generated from a separately trained speaker encoder. However, this approach also enabled it to generate the translated speech in a different speaker's voice if a clip of the target speaker's recording were used as the reference audio to the speaker encoder, or if the embedding of the target speaker were directly available. While this capability was powerful, it had the potential to be misused to spoof audio with arbitrary content, which posed a concern for production deployment.
To address this, we designed Translatotron 2 to use only a single speech encoder, which is responsible for both linguistic understanding and voice capture. In this way, the trained models cannot be directed to reproduce non-source voices. This approach can also be applied to the original Translatotron.
To retain speakers' voices across translation, researchers generally prefer to train S2ST models on parallel utterances with the same speaker's voice on both sides. Such a dataset with human recordings on both sides is extremely difficult to collect, because it requires a large number of fluent bilingual speakers. To avoid this difficulty, we use a modified version of PnG NAT, a TTS model that is capable of cross-lingual voice transferring to synthesize such training targets. Our modified PnG NAT model incorporates a separately trained speaker encoder in the same way as in our previous TTS work — the same strategy used for the original Translatotron — so that it is capable of zero-shot voice transference.
Following are examples of direct speech-to-speech translation from Translatotron 2 in which the source speaker’s voice is retained:
| Input (Spanish): |
| TTS-synthesized reference (English): |
| Translatotron 2 prediction (English): |
| Translatotron prediction (English): |
To enable S2ST models to retain each speaker’s voice in the translated speech when the input speech contains multiple speakers speaking in turns, we propose a simple concatenation-based data augmentation technique, called ConcatAug. This method augments the training data on the fly by randomly sampling pairs of training examples and concatenating the source speech, the target speech, and the target phoneme sequences into new training examples. The resulting samples contain two speakers’ voices in both the source and the target speech, which enables the model to learn on examples with speaker turns. Following are audio samples from Translatotron 2 with speaker turns:
| Input (Spanish): |
| TTS-synthesized reference (English): |
| Translatotron 2 (with ConcatAug) prediction (English): |
| Translatotron 2 (without ConcatAug) prediction (English): |
More audio samples are available here.
Performance
Translatotron 2 outperforms the original Translatotron by large margins in every aspect we measured: higher translation quality (measured by BLEU, where higher is better), speech naturalness (measured by MOS, higher is better), and speech robustness (measured by UDR, lower is better). It particularly excelled on the more difficult Fisher corpus. The performance of Translatotron 2 on translation quality and speech quality approaches that of a strong baseline cascade system, and is better than the cascade baseline on speech robustness.
 |
| Translation quality (measured by BLEU, where higher is better) evaluated on two Spanish-English corpora. |
 |
| Speech naturalness (measured by MOS, where higher is better) evaluated on two Spanish-English corpora. |
 |
| Speech robustness (measured by UDR, where lower is better) evaluated on two Spanish-English corpora. |
Multilingual Speech-to-Speech Translation
Besides Spanish-to-English S2ST, we also evaluated the performance of Translatotron 2 on a multilingual set-up in which the model took speech input from four different languages and translated them into English. The language of the input speech was not provided, which forced the model to detect the language by itself.
| Source Language | fr | de | es | ca |
| Translatotron 2 | 27.0 | 18.8 | 27.7 | 22.5 |
| Translatotron | 18.9 | 10.8 | 18.8 | 13.9 |
| ST (Wang et al. 2020) | 27.0 | 18.9 | 28.0 | 23.9 |
| Training Target | 82.1 | 86.0 | 85.1 | 89.3 |
| Performance of multilingual X=>En S2ST on the CoVoST 2 corpus. |
On this task, Translatotron 2 again outperformed the original Translatotron by a large margin. Although the results are not directly comparable between S2ST and ST, the close numbers suggest that the translation quality from Translatotron 2 is comparable to a baseline speech-to-text translation model, These results indicate that Translatotron 2 is also highly effective on multilingual S2ST.
Acknowledgments
The direct contributors to this work include Ye Jia, Michelle Tadmor Ramanovich, Tal Remez, Roi Pomerantz. We also thank Chung-Cheng Chiu, Quan Wang, Heiga Zen, Ron J. Weiss, Wolfgang Macherey, Yu Zhang, Yonghui Wu, Hadar Shemtov, Ruoming Pang, Nadav Bar, Hen Fitoussi, Benny Schlesinger, Michael Hassid for helpful discussions and support.
Quick links



