Harnessing Organizational Knowledge for Machine Learning
March 14, 2019
Posted by Alex Ratner, Stanford University and Cassandra Xia, Google AI
Quick links
One of the biggest bottlenecks in developing machine learning (ML) applications is the need for the large, labeled datasets used to train modern ML models. Creating these datasets involves the investment of significant time and expense, requiring annotators with the right expertise. Moreover, due to the evolution of real-world applications, labeled datasets often need to be thrown out or re-labeled.
In collaboration with Stanford and Brown University, we present "Snorkel Drybell: A Case Study in Deploying Weak Supervision at Industrial Scale," which explores how existing knowledge in an organization can be used as noisier, higher-level supervision—or, as it is often termed, weak supervision—to quickly label large training datasets. In this study, we use an experimental internal system, Snorkel Drybell, which adapts the open-source Snorkel framework to use diverse organizational knowledge resources—like internal models, ontologies, legacy rules, knowledge graphs and more—in order to generate training data for machine learning models at web scale. We find that this approach can match the efficacy of hand-labeling tens of thousands of data points, and reveals some core lessons about how training datasets for modern machine learning models can be created in practice.
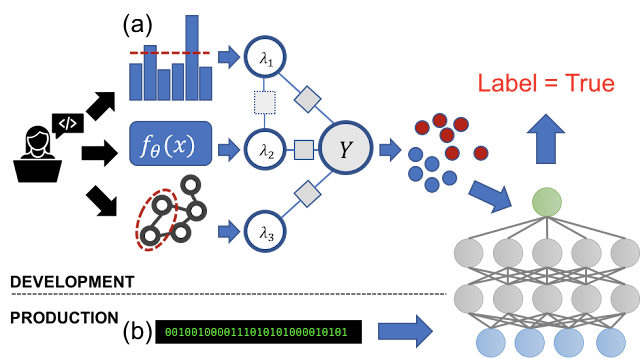
Rather than labeling training data by hand, Snorkel DryBell enables writing labeling functions that label training data programmatically. In this work, we explored how these labeling functions can capture engineers' knowledge about how to use existing resources as heuristics for weak supervision. As an example, suppose our goal is to identify content related to celebrities. One can leverage an existing named-entity recognition (NER) model for this task by labeling any content that does not contain a person as not related to celebrities. This illustrates how existing knowledge resources (in this case, a trained model) can be combined with simple programmatic logic to label training data for a new model. Note also, importantly, that this labeling function returns None---i.e. abstains---in many cases, and thus only labels some small part of the data; our overall goal is to use these labels to train a modern machine learning model that can generalize to new data.
 |
| In our example of a labeling function, rather than hand-labeling a data point (1), one utilizes an existing knowledge resource—in this case, a NER model (2)—together with some simple logic expressed in code (3) to heuristically label data. |
To solve the problem of noisy and correlated labels, Snorkel DryBell uses a generative modeling technique to automatically estimate the accuracies and correlations of the labeling functions in a provably consistent way—without any ground truth training labels—then uses this to re-weight and combine their outputs into a single probabilistic label per data point. At a high level, we rely on the observed agreements and disagreements between the labeling functions (the covariance matrix), and learn the labeling function accuracy and correlation parameters that best explain this observed output using a new matrix completion-style approach. The resulting labels can then be used to train an arbitrary model (e.g. in TensorFlow), as shown in the system diagram below.
Using Diverse Knowledge Sources as Weak Supervision
To study the efficacy of Snorkel Drybell, we used three production tasks and corresponding datasets, aimed at classifying topics in web content, identifying mentions of certain products, and detecting certain real-time events. Using Snorkel DryBell, we were able to make use of various existing or quickly specified sources of information such as:
- Heuristics and rules: e.g. existing human-authored rules about the target domain.
- Topic models, taggers, and classifiers: e.g. machine learning models about the target domain or a related domain.
- Aggregate statistics: e.g. tracked metrics about the target domain.
- Knowledge or entity graphs: e.g. databases of facts about the target domain.
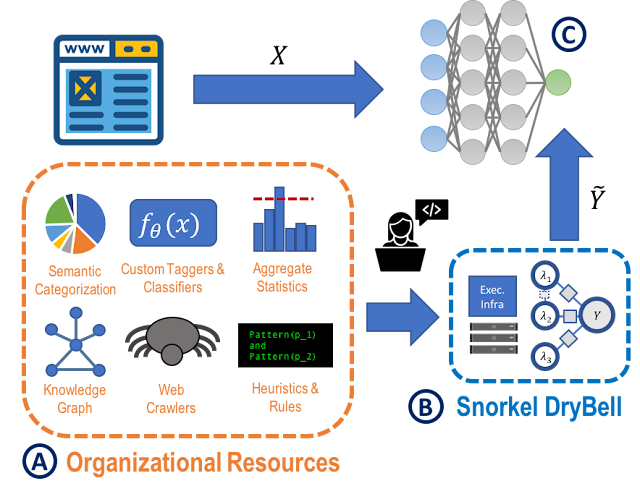
 |
| In Snorkel DryBell, the goal is to train a machine learning model (C), for example to do content or event classification over web data. Rather than hand-labeling training data to do this, in Snorkel DryBell users write labeling functions that express various organizational knowledge resources (A), which are then automatically reweighted and combined (B). |
Modeling the Accuracies to Combine & Repurpose Existing Sources
To handle these noisy labels, the next stage of Snorkel DryBell combines the outputs from the labeling functions into a single, confidence-weighted training label for each data point. The challenging technical aspect is that this must be done without any ground-truth labels. We use a generative modeling technique that learns the accuracy of each labeling function using only unlabeled data. This technique learns by observing the matrix of agreements and disagreements between the labeling functions' outputs, taking into account known (or statistically estimated) correlation structures between them. In Snorkel DryBell, we also implement a new faster, sampling-free version of this modeling approach, implemented in TensorFlow, in order to handle web-scale data.
By combining and modeling the output of the labeling functions using this procedure in Snorkel DryBell, we were able to generate high-quality training labels. In fact, on the two applications where hand-labeled training data was available for comparison, we achieved the same predictive accuracy training a model with Snorkel DryBell's labels as we did when training that same model with 12,000 and 80,000 hand-labeled training data points.
Transferring Non-Servable Knowledge to Servable Models
In many settings, there is also an important distinction between servable features—which can be used in production—and non-servable features, that are too slow or expensive to be used in production. These non-servable features may have very rich signal, but a general question is how to use them to train or otherwise help servable models that can be deployed in production?
 |
| In many settings, users write labeling functions that leverage organizational knowledge resources that are not servable in production (a)—e.g. aggregate statistics, internal models, or knowledge graphs that are too slow or expensive to use in production—in order to train models that are only defined over production-servable features (b), e.g. cheap, real-time web signals. |
Next Steps
Moving forward, we're excited to see what other types of organizational knowledge can be used as weak supervision, and how the approach used by Snorkel DryBell can enable new modes of information reuse and sharing across organizations. For more details, check out our paper, and for further technical details, blog posts, and tutorials, check out the open-source Snorkel implementation at snorkel.stanford.edu.
Acknowledgments
This research was done in collaboration between Google, Stanford, and Brown. We would like to thank all the people who were involved, including Stephen Bach (Brown), Daniel Rodriguez, Yintao Liu, Chong Luo, Haidong Shao, Souvik Sen, Braden Hancock (Stanford), Houman Alborzi, Rahul Kuchhal, Christopher Ré (Stanford), Rob Malkin.
Quick links
Other posts of interest
-

July 30, 2026
Science One Framework: A verifiable autonomous research framework via Chain-of-Evidence- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯