HALVA: Hallucination Attenuated Language and Vision Assistant
August 9, 2024
Pritam Sarkar, Student Researcher, and Sayna Ebrahimi, Research Scientist, Cloud AI Research
Quick links
Recent advancements in Large Language Models (LLMs) have laid the foundation for the development of highly capable multimodal LLMs (MLLMs) like Gemini. MLLMs can process additional modalities, such as images or videos, while retaining language understanding and generation capabilities. Despite the impressive performance of MLLMs across a variety of tasks, the issue of object hallucination presents a significant challenge to their widespread adoption. Object hallucination refers to generated language that includes descriptions of objects or their attributes that are not present in or cannot be verified by the given input.
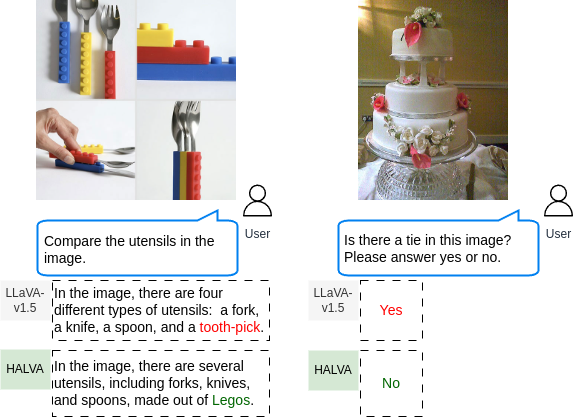
Examples of object hallucinations. Left: When asked to compare the utensils in an image, LLaVA-v1.5 inaccurately mentions the presence of a toothpick and fails to mention the presence of Legos. Right: LLaVA-v1.5 incorrectly confirms the presence of a ‘tie’ in an image of a wedding cake.
Prior works have attempted to address object hallucination in one of three key stages: inference (e.g., Woodpecker), pretraining (e.g., HACL), or fine tuning (e.g., HA-DPO). Fine-tuning methods are a more efficient approach as they require neither training from scratch (unlike pre-training–based methods) nor changes in the serving infrastructure (unlike inference-based methods). However, existing fine-tuning approaches prioritize object hallucination mitigation at the expense of deteriorating performance of the base model when solving general vision and language tasks.
To that end, in “Mitigating Object Hallucination via Data Augmented Contrastive Tuning”, we introduce a contrastive tuning method that can be applied to off-the-shelf MLLMs to mitigate hallucinations, while preserving their general vision-language capabilities. For a given factual token (i.e., words or word segments within the ground-truth caption), we create a hallucinated token through generative data augmentation by selectively altering the ground-truth information. This approach operates between a pair of tokens with the goal of boosting the probability that the model will output factual tokens over hallucinated tokens. We demonstrate that the method is simple, fast, and requires minimal training with no additional overhead at inference.
Data augmented contrastive tuning
Our method consists of two key steps: (1) generative data augmentation and (2) contrastive tuning. For a given pair of vision-language instructions and a corresponding correct answer, generative data augmentation is applied to obtain hallucinated responses. We selectively alter ground-truth objects and object-related attributes from the correct answer to introduce hallucinated concepts that are not present in the input images.
A contrastive loss is then calculated between a pair of factual and hallucinated tokens. Our objective is to minimize the likelihood of generating hallucinated tokens and correspondingly, maximize the likelihood of generating factual tokens. We train the MLLM with a KL-divergence regularizer that ensures that the MLLM retains its original performance in general vision-language tasks by preventing it from diverging from the base model. We refer to MLLMs trained with the contrastive tuning framework as Hallucination Attenuated Language and Vision Assistants (HALVA).
Given a pair of vision-language instructions and a corresponding correct answer, we perform generative data augmentation to construct a hallucinated response, selectively altering the ground-truth objects and related attributes.
Results
We use LLaVA-v1.5, a widely used open-sourced MLLM, as our base model and train it using our contrastive tuning framework (HALVA). We then evaluate its performance on object hallucination mitigation and general visual question answering tasks (VQA) against fine-tuning–based approaches, HA-DPO and EOS. We consider LLaVA-v1.5 as the lower bound and GPT-4V as a strong reference point given its performance on standard benchmarks.
We use the AMBER benchmark and Caption Hallucination Assessment with Image Relevance (CHAIR) metric to evaluate MLLM performance on image description tasks, assessing both hallucination rate and the level of detail of their generated image descriptions. The latter aspect is quantified by calculating the percentage of ground-truth objects present in the image that are accurately captured in the model’s output. Our goal is to mitigate hallucinations while retaining or improving the richness of image descriptions. As shown in the left plot below, HALVA captures more ground-truth objects while hallucinating less than HA-DPO. Moreover, while EOS achieves a slightly lower hallucination rate, it degrades the level of detail in the image descriptions, performing worse than HALVA.
We also use the F1-score to compare the performance of MLLMs on visual question answering tasks using the AMBER benchmark for object hallucination and TextVQA benchmark for general vision language accuracy. As shown in the right plot below, both HA-DPO and EOS underperform HALVA in mitigating object hallucination and even deteriorate general vision-language abilities compared to the base model.
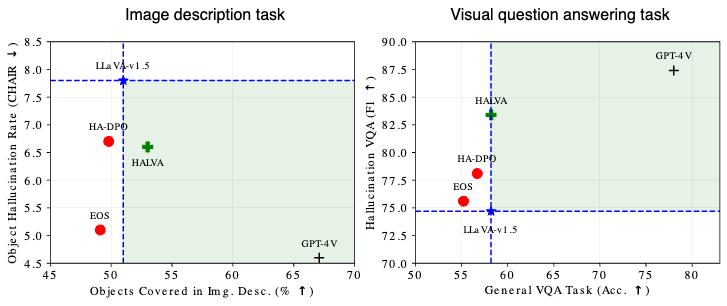
A high-level overview comparing the performance of HALVA with existing fine-tuning methods. Mitigating object hallucination in image description tasks (left). Performance on general vision-language tasks (right).
Evaluation of object hallucination on image description tasks
When evaluating performance on image description tasks, we use CHAIR to measure hallucination at two levels: instance-level and sentence-level. In this task, HALVA is prompted with “Describe the image in detail”, which triggers it to generate detailed image descriptions. On the MS COCO dataset, HALVA substantially reduces hallucination compared to the base variants. For instance, compared to LLaVA-v1.5, the 7B (HALVA-7B) and 13B (HALVA-13B) variants reduce instance-level hallucinations from 15.4 to 11.7 points and from 13 to 12.8 points, respectively. On the AMBER benchmark, the frequency of hallucinated objects in image descriptions is also captured by CHAIR, where HALVA-7B and HALVA-13B reduce hallucinations from 7.8 and 6.6 points to 6.6 and 6.4 points, respectively.
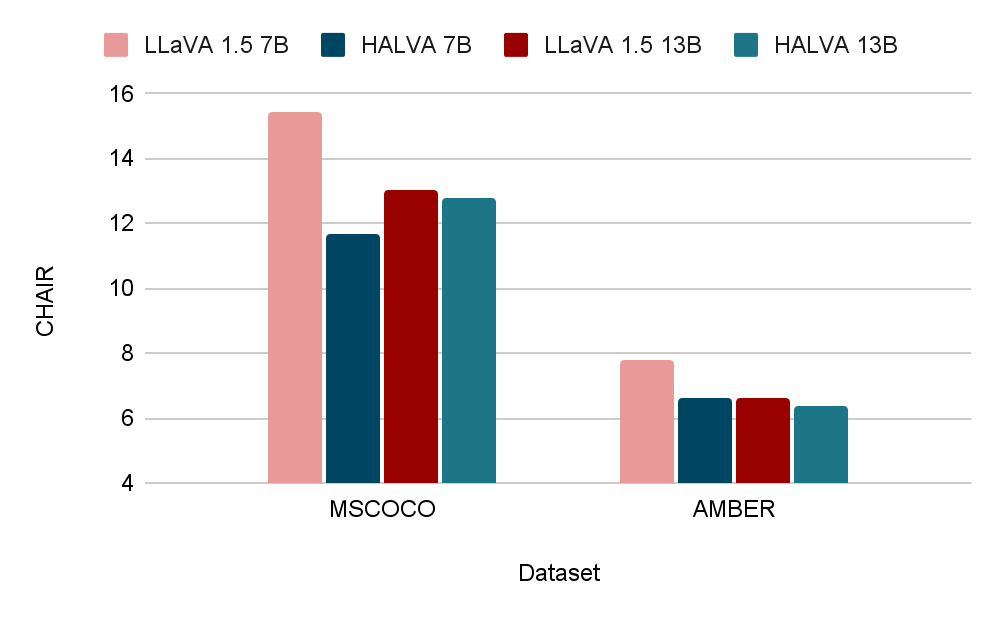
Quantitative results demonstrating reduced object hallucination rate in HALVA compared to the base model LLaVA-v1.5 in image description tasks. We measure the CHAIR at the instance level where lower is better.

A sample qualitative demonstration of HALVA in comparison to the base model LLaVA-v1.5 on an image description task.
Evaluation on object hallucination on visual question answering tasks
We evaluate HALVA on discriminative tasks using the MME benchmark. Specifically, we utilize the hallucination subset of MME, which consists of four object-related subtasks — existence, count, position, and color — referred to as MME-Hall. The results presented below demonstrate that HALVA substantially improves performance compared to the base model, LLaVA-v1.5. For instance, HALVA-13B achieves a score of 675 out of 800, resulting in a performance gain of 31.7 points compared to the base model.
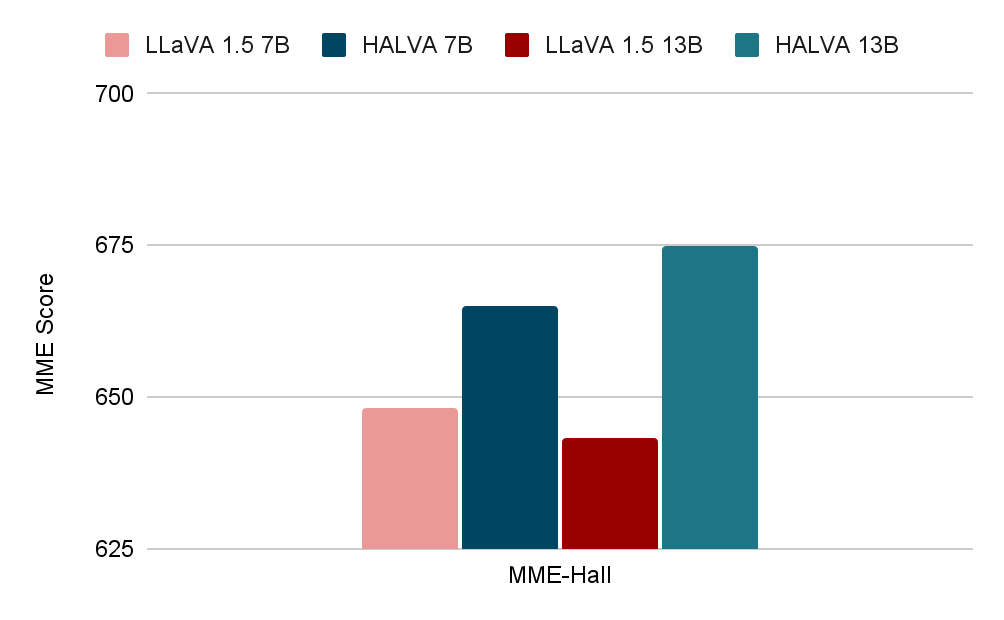
Quantitative results demonstrating reduced object hallucination in HALVA compared to the base model LLaVA-v1.5 on visual question answering tasks. The maximum score is 800; higher is better.
On the AMBER benchmark, HALVA 7B and 13B improve the F1 score of LLaVA-v1.5 7B and 13B by a large margin of 8.7 and 13.4 points.
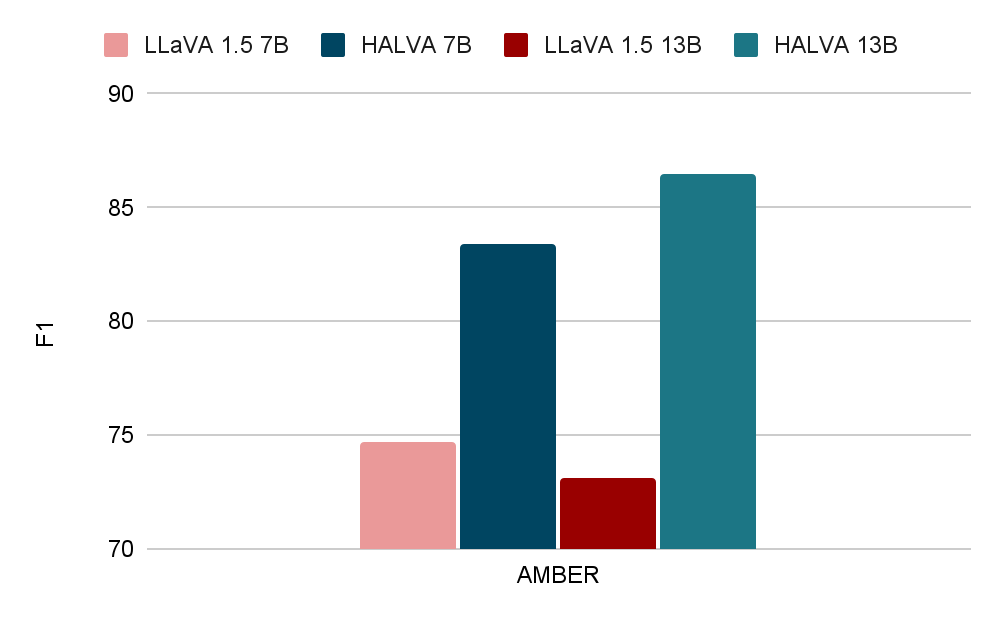
Quantitative results demonstrating reduced object hallucination by HALVA compared to the base model LLaVA-v1.5 in visual question answering tasks. The maximum score is 100 and higher is better.
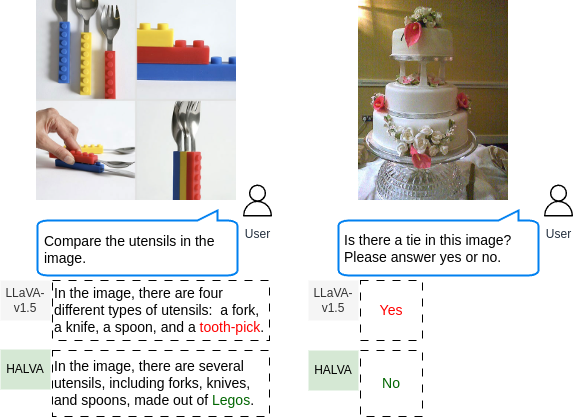
In the qualitative example below, we show how HALVA captures the details in the image to provide a factual answer to the given question.

A sample qualitative demonstration of HALVA in comparison to the base model LLaVA-v1.5 on visual question answering.
Evaluation of mitigating hallucination beyond object hallucination
To further stress-test our method on other forms of vision-language hallucinations that are not restricted to objects and may occur due to visual illusions, we evaluate performance using the HallusionBench benchmark. Our results demonstrate that HALVA also directly benefits other forms of vision-language hallucinations. HALVA 7B and 13B variants improve overall accuracy by 1.86% and 2.16%, respectively, compared to their base models.
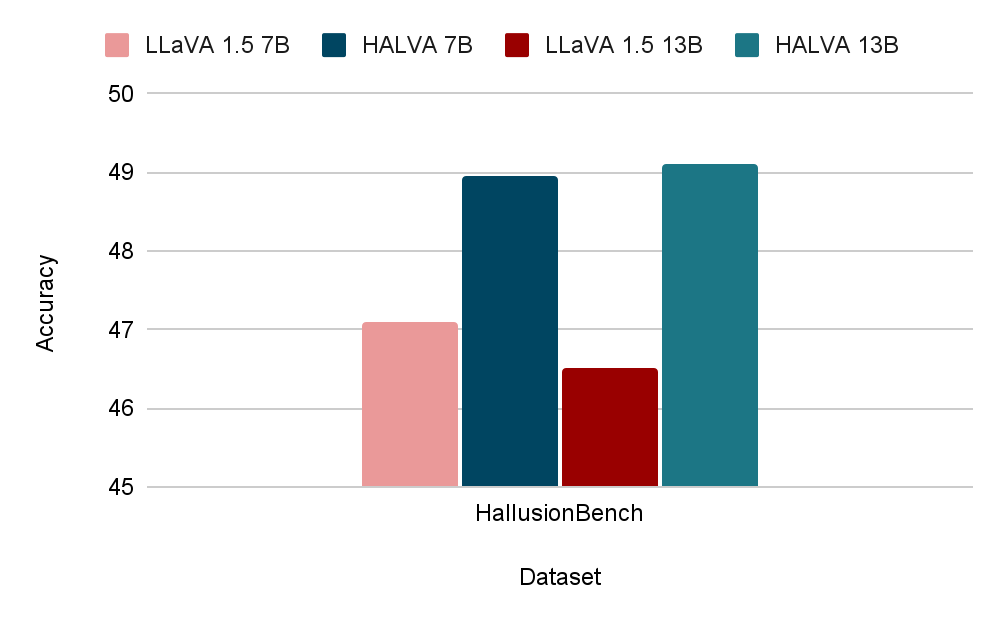
Quantitative results demonstrating reduced hallucination in HALVA compared to the base model LLaVA-v1.5 in mitigating other forms of vision-language hallucinations that are not restricted to objects and may occur due to visual illusions, among others. We report accuracy where higher is better.
We illustrate HALVA’s ability to capture visual hallucinations beyond object hallucination in the qualitative example below:
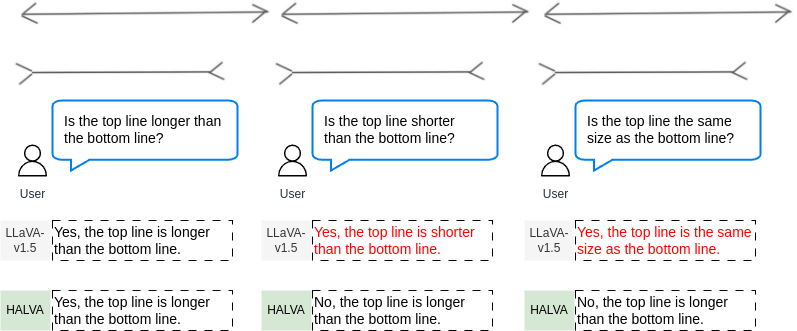
A sample qualitative demonstration of HALVA being effective on visual illusion.
Conclusion
To mitigate object hallucination in MLLMs, we introduce data augmented contrastive tuning. Our proposed method is effective in mitigating object hallucinations and beyond while retaining or even improving their performance on general vision-language tasks. Moreover, the proposed contrastive tuning is simple, fast, and requires minimal training with no additional overhead at inference. We believe that our method may have applications in other areas as well. For example, it might be adapted to mitigate bias and harmful language generation, among others.
Acknowledgements
We gratefully acknowledge the contributions of our co-authors, Ali Etemad, Ahmad Beirami, Sercan Arik and Tomas Pfister. Special thanks to Tom Small for creating the animated figure in this blog post.
-
Labels:
- Generative AI
- Machine Intelligence
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence