Grounding AI in reality with a little help from Data Commons
September 12, 2024
Jennifer Chen, Software Engineer, and Prem Ramaswami, Head of Data Commons, Google Technology & Society, Data Commons Team
Google's DataGemma models bridge the gap between large language models (LLMs) and real-world data by leveraging the Data Commons knowledge graph to improve the factuality and trustworthiness of LLM responses.
Large Language Models (LLMs) have revolutionized how we interact with information, but grounding their responses in verifiable facts remains a fundamental challenge. This is compounded by the fact that real-world knowledge is often scattered across numerous sources, each with its own data formats, schemas, and APIs, making it difficult to access and integrate. Lack of grounding can lead to hallucinations — instances where the model generates incorrect or misleading information. Building responsible and trustworthy AI systems is a core focus of our research, and addressing the challenge of hallucination in LLMs is crucial to achieving this goal.
Today we're excited to announce DataGemma, an experimental set of open models that help address the challenges of hallucination by grounding LLMs in the vast, real-world statistical data of Google's Data Commons. Data Commons already has a natural language interface. Inspired by the ideas of simplicity and universality, DataGemma leverages this pre-existing interface so natural language can act as the “API”. This means one can ask things like, “What industries contribute to California jobs?” or “Are there countries in the world where forest land has increased?” and get a response back without having to write a traditional database query. By using Data Commons, we overcome the difficulty of dealing with data in a variety of schemas and APIs. In a sense, LLMs provide a single “universal” API to external data sources.
Data Commons is a foundation for factual AI
Data Commons is Google’s publicly available knowledge graph that contains over 250 billion global data points across hundreds of thousands of statistical variables, sourced from trusted organizations like the United Nations, the World Health Organization, health ministries, census bureaus, and more, who provide factual data covering a wide range of topics, from economics and climate change to health and demographics
DataGemma connects LLMs to Data Commons’ real-world data
Gemma is a family of lightweight, state-of-the-art, open models built from the same research and technology used to create our Gemini models. DataGemma expands the capabilities of the Gemma family by harnessing the knowledge of Data Commons to enhance LLM factuality and reasoning. By leveraging innovative retrieval techniques, DataGemma helps LLMs access and incorporate into their responses data sourced from trusted institutions (including governmental and intergovernmental organizations and NGOs), mitigating the risk of hallucinations and improving the trustworthiness of their outputs.
Instead of needing knowledge of the specific data schema or API of the underlying datasets, DataGemma utilizes the natural language interface of Data Commons to ask questions. The nuance is in training the LLM to know when to ask. For this, we use two different approaches, Retrieval Interleaved Generation (RIG) and Retrieval Augmented Generation (RAG).
Retrieval Interleaved Generation (RIG)
This approach fine-tunes Gemma 2 to identify statistics within its responses and annotate them with a call to Data Commons, including a relevant query and the model's initial answer for comparison. Think of it as the model double-checking its work against a trusted source.
Here's how RIG works:
- User query: A user submits a query to the LLM.
- Initial response & Data Commons query: The DataGemma model (based on the 27 billion parameter Gemma 2 model and fully fine-tuned for this RIG task) generates a response, which includes a natural language query for Data Commons' existing natural language interface, specifically designed to retrieve relevant data. For example, instead of stating "The population of California is 39 million", the model would produce "The population of California is [DC(What is the population of California?) → "39 million"]", allowing for external verification and increased accuracy.
- Data retrieval & correction: Data Commons is queried, and the data are retrieved. These data, along with source information and a link, are then automatically used to replace potentially inaccurate numbers in the initial response.
- Final response with source link: The final response is presented to the user, including a link to the source data and metadata in Data Commons for transparency and verification.
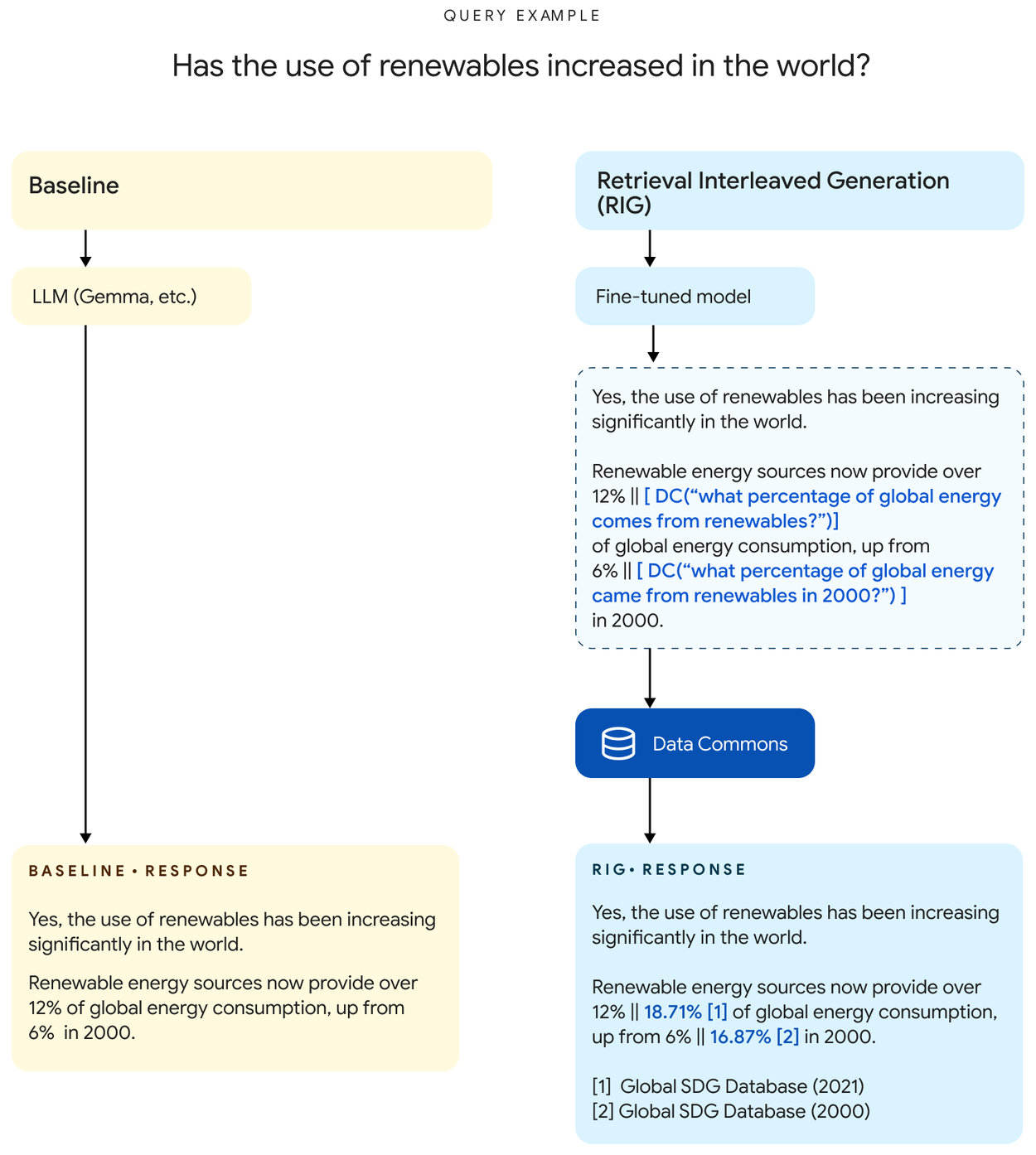
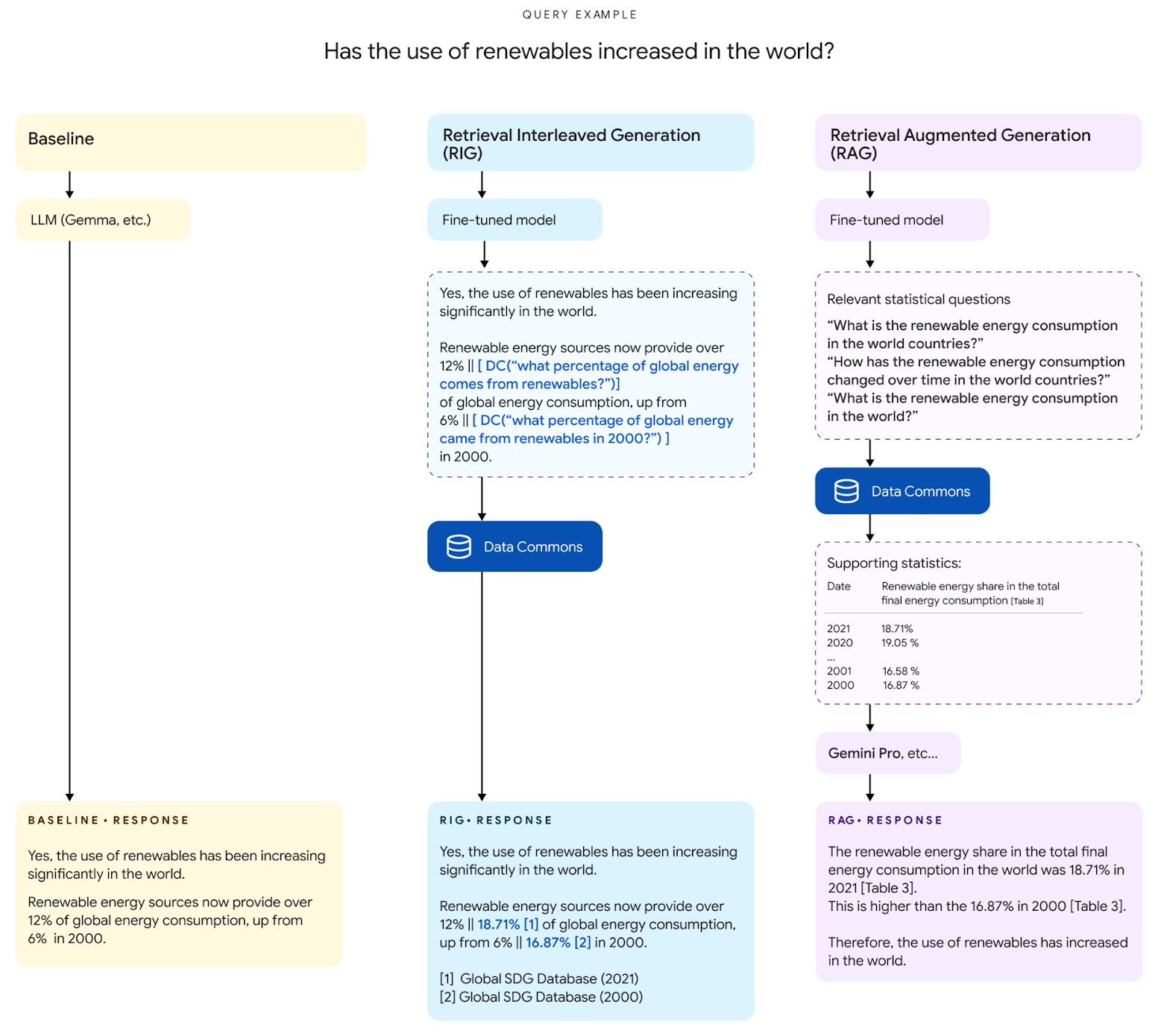
Comparison of Baseline and RIG approaches for generating responses with statistical data. The Baseline approach directly reports statistics without evidence, while RIG leverages Data Commons (DC) for authoritative data. Dotted boxes illustrate intermediary steps: RIG interleaves stat tokens with natural language questions suitable for retrieval from DC.
Trade-offs of the RIG approach
An advantage of this approach is that it doesn’t alter the user query and can work effectively in all contexts. However, the LLM doesn’t inherently learn or retain the updated data from Data Commons, making any secondary reasoning or follow-on queries oblivious to the new information. In addition, fine-tuning the model requires specialized datasets tailored to specific tasks.
Retrieval Augmented Generation (RAG)
This established approach retrieves relevant information from Data Commons before the LLM generates text, providing it with a factual foundation for its response. The challenge here is that the data returned from broad queries may contain a large number of tables that span multiple years of data. In fact, from our synthetic query set, there was an average input length of 38,000 tokens with a max input length of 348,000 tokens. Hence, the implementation of RAG is only possible because of Gemini 1.5 Pro’s long context window, which allows us to append the user query with such extensive Data Commons data.
Here's how RAG works:
- User query: A user submits a query to the LLM.
- Query analysis & Data Commons query generation: The DataGemma model (based on the Gemma 2 (27B) model and fully fine-tuned for this RAG task) analyzes the user's query and generates a corresponding query (or queries) in natural language that can be understood by Data Commons' existing natural language interface.
- Data retrieval from Data Commons: Data Commons is queried using this natural language query, and relevant data tables, source information, and links are retrieved.
- Augmented prompt: The retrieved information is added to the original user query, creating an augmented prompt.
- Final response generation: A larger LLM (e.g., Gemini 1.5 Pro) uses this augmented prompt, including the retrieved data, to generate a comprehensive and grounded response.
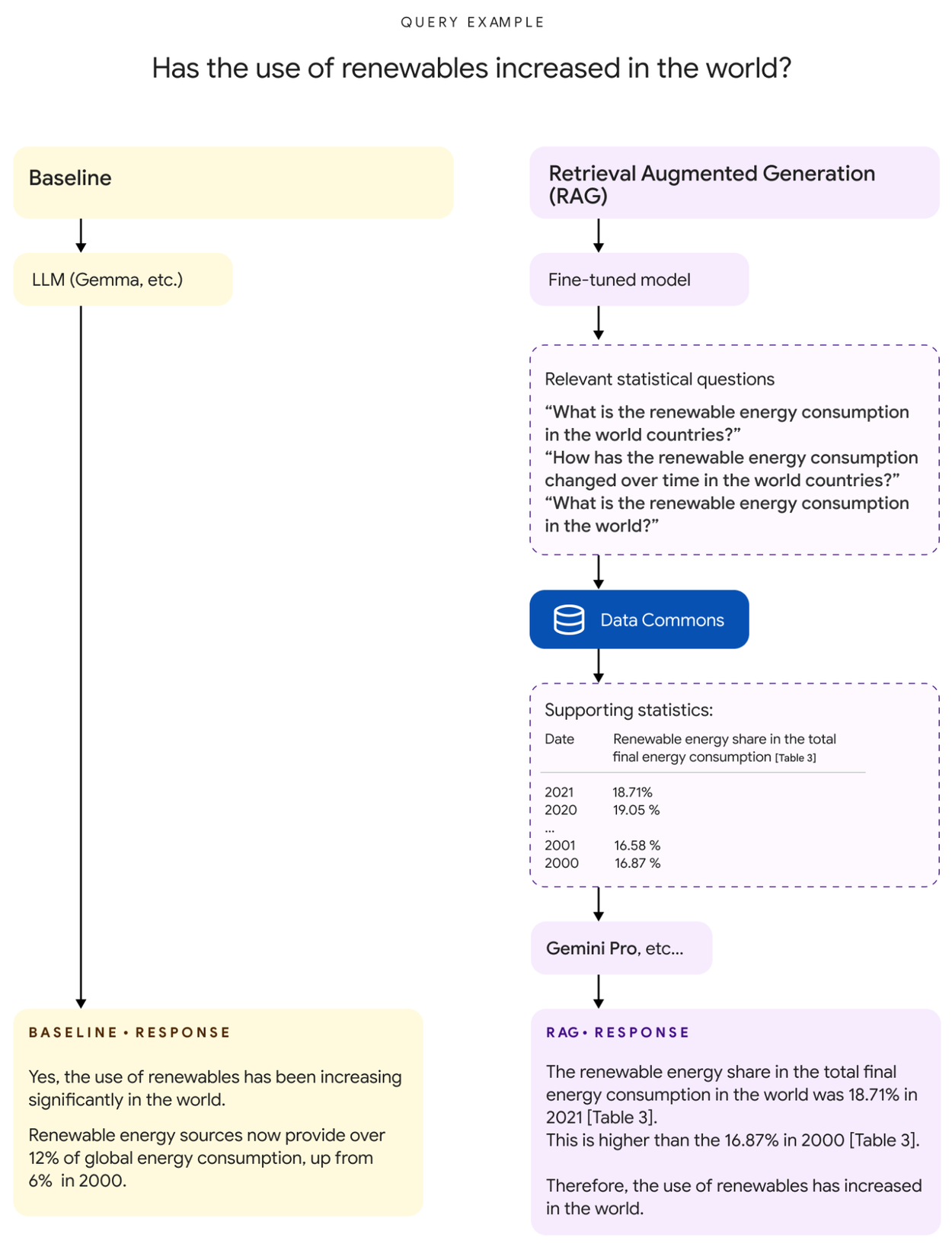
Comparison of Baseline and RAG approaches for generating responses with statistical data. RAG generates fine-grained natural language questions answered by DC, which are then provided in the prompt to produce the final response.

Illustration of a RAG query and response. Supporting ground truth statistics are referenced here as tables served from Data Commons. Partial response shown for brevity.
Trade-offs of the RAG approach
Advantages to using this approach are that RAG automatically benefits from ongoing model evolution, particularly improvements in the LLM generating the final response. As this LLM advances, it can better utilize the context retrieved by RAG, leading to more accurate and insightful outputs even with the same retrieved data generated by the query LLM. A disadvantage is that modifying the user's prompt can sometimes lead to a less intuitive user experience. In addition, the effectiveness of grounding depends on the quality of the generated queries to Data Commons.
Join us in shaping the future of grounded AI
While DataGemma represents a significant step forward, we recognize that it's still early in the development of grounded AI. We invite researchers, developers, and anyone passionate about responsible AI to explore DataGemma and join us in this exciting journey. We believe that by grounding LLMs in the real-world data of Data Commons, we can unlock new possibilities for AI and create a future where information is not only intelligent but also grounded in facts and evidence. To go deeper into the research behind DataGemma, we encourage you to read our research paper.
We also hope researchers extend this work past our specific implementation with Data Commons. Data Commons itself provides ways for third parties to set up their own Data Commons instances. In addition, we believe this work is generally extensible to any knowledge graph format and look forward to further research and exploration in this space.
Ready to get started? Download the DataGemma models from Hugging Face or Kaggle (RIG, RAG). To help you get started quickly, try our quickstart notebooks for both the RIG and RAG approaches. These notebooks provide a hands-on introduction to using DataGemma and exploring its capabilities.
-
Full details on the data sources, datasets, and dataset characteristics available through Data Commons are available on the Data Sources page and references therein.
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Expanding our Heat Resilience data to 50+ global cities- Climate & Sustainability ·
- Earth AI ·
- Open Source Models & Datasets


