Google AI Princeton: Current and Future Research
December 18, 2018
Posted by Elad Hazan and Yoram Singer, Research Scientists, Google AI and Princeton University
Quick links
Google has long partnered with academia to advance research, collaborating with universities all over the world on joint research projects which result in novel developments in Computer Science, Engineering, and related fields. Today we announce the latest of these academic partnerships in the form of a new lab, across the street from Princeton University’s historic Nassau Hall, opening early next year. By fostering closer collaborations with faculty and students at Princeton, the lab aims to broaden research in multiple facets of machine learning, focusing its initial research efforts on optimization methods for large-scale machine learning, control theory and reinforcement learning. Below we give a brief overview of the research progress thus far.
Large-Scale Optimization
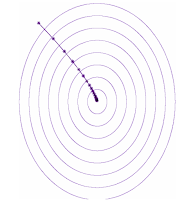
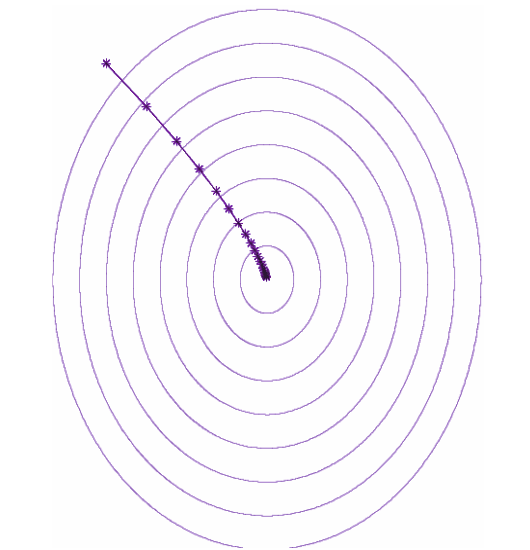
Imagine you have gone for a mountain hike and have run out of water. You need to get to a lake. How can you do so most efficiently? This is a matter of optimizing your route, and the mathematical analogue of this is the gradient descent method. You therefore move in the direction of steepest descent until you find the nearest lake at the bottom of your path. In the language of optimization, the location of the lake is referred to as a (local) minimum. The trajectory of gradient descent resembles the path, shown below, a thirsty yet avid hiker would take in order to get down to a lake as fast as she can.



This simplified diagonal preconditioning imposes only a marginal additional cost to gradient descent. However, oversimplification has its own downside: we are no longer able to rotate our space. Going back to our hiker, if the deep-and-narrow canyon runs from southeast to northwest, she can no longer take large westward leaps. Had we provided her with a “rigged” compass in which the north pole is in the northwest, she could have followed her descent procedure as before. In high dimensions, the analog of compass rigging is full-matrix preconditioning. We thus asked ourselves whether we could devise a preconditioning method that is computationally efficient while allowing for the equivalent of coordinate rotations.
At Google AI Princeton, we developed a new method for full-matrix adaptive preconditioning at roughly the same computational cost as the commonly-used diagonal restriction. Details can be found in the paper, but the key idea behind the method is depicted below. Instead of using a full matrix, we replace the preconditioning matrix by a product of three matrices: a tall & thin matrix, a (small) square matrix, and a short & fat matrix. The vast amount of computation is performed using the smaller matrix. If we have d parameters, instead of a single large d × d matrix, the matrices maintained by GGT (shorthand for the operation Gradient GradientT), the proposed method, are of sizes d × k, k × k, k × d respectively.

For reasonable choices of k, which can be thought of as the “window size” of the algorithm, the computational bottleneck has been mitigated from a single large matrix, to that of a much smaller kkmatrix. In our implementation we typically choose k to be, say, 50, and maintaining the smaller square matrix is significantly less expensive while yielding good empirical performance. When compared to other adaptive methods on standard deep learning tasks, GGT is competitive with AdaGrad and Adam.
Spectral Filtering for Control and Reinforcement Learning
Another broad mission of Google’s research group in Princeton is to develop principled building blocks for decision-making systems. In particular, the group strives to leverage provable guarantees from the field of online learning, which studies the robust (worst-case) guarantees of decision-making algorithms under uncertainty. An online algorithm is said to attain a no-regret guarantee if it learns to make decisions as well as the best "offline" decision in hindsight. Ideas from this field have already enabled many innovations within theoretical computer science, and provide a mathematically elegant framework to study a widely-used technique called boosting. We envision using ideas from online learning to broaden the toolkit of modern reinforcement learning.
With that goal in mind, and in collaboration with researchers and students at Princeton, we developed the algorithmic technique of spectral filtering for estimation and control of linear dynamical systems (see several recent publications). In this setting, noisy observations (e.g., location sensor measurements) are being streamed from an unknown source. The source of the signal is a system whose state evolves over time following a set of linear equations (e.g. Newton's laws). To forecast future signals (prediction), or to perform actions which bring the system to a desired state (control), the usual approach starts with learning the model explicitly (a task termed system identification), which is often slow and inaccurate.
Spectral filtering circumvents the need to model the dynamics explicitly, by reformulating prediction and control as convex programs, enabling provable no-regret guarantees. A major component of the technique is that of a new signal processing transformation. The idea is to summarize the long history of past input signals through convolution with a tailored bank of filters, and then use this representation to predict the dynamical system’s future outputs. Each filter compresses the input signal into a single real number, by taking a weighted combination of the previous inputs.
 |
| A set of filters depicted in a plot of filter amplitude versus time. With our technique of spectral filtering, multiple filters are used to predict the state of a linear dynamical system at any given time. Each filter is a set of weights used to summarize past observations, such that combining them in a weighted fashion, over time allows us to accurately predict the system. |
Looking Forward
We are excited about the progress we have made thus far in partnership with Princeton’s faculty and students, and we look forward to the official opening of the lab in the coming weeks. It has long been Google’s view that both industry and academia benefit significantly from an open research culture, and we look forward to our continued close collaboration.
Acknowledgments
The research and results discussed in this post would not have been possible without contributions from the following researchers: Naman Agarwal, Brian Bullins, Xinyi Chen, Udaya Ghai, Tomer Koren, Karan Singh, Cyril Zhang, Yi Zhang, and visiting professor Sham Kakade. Since joining Google earlier this year, the research team has been working remotely from both the Google NYC office as well as the Princeton University campus, and they look forward to moving into the new Google space across from the Princeton campus in the weeks to come.
-
Labels:
- Algorithms & Theory
Quick links
Other posts of interest
-

July 10, 2025
Graph foundation models for relational data- Algorithms & Theory ·
- Machine Intelligence
-

June 30, 2025
How we created HOV-specific ETAs in Google Maps- Algorithms & Theory ·
- Data Mining & Modeling ·
- Machine Intelligence
-

June 25, 2025
MUVERA: Making multi-vector retrieval as fast as single-vector search- Algorithms & Theory ·
- Machine Intelligence