Genomic Data Processing on Google Cloud Platform
April 6, 2016
Posted by Dr. Stacey Gabriel, Director of the Genomics Platform at the Broad Institute of MIT and Harvard
Quick links
Today we hear from Broad Institute of MIT and Harvard about how their researchers and software engineers are collaborating closely with the Google Genomics team on large-scale genomic data analysis. They’ve already reduced the time and cost for whole genome processing by several fold, helping researchers think even bigger. Broad’s open source tools, developed in close collaboration with Google Genomics, will also be made available to the wider research community.
– Jonathan Bingham, Product Manager, Google Genomics
 |
| Dr. Stacey Gabriel, Director of the Genomics Platform at the Broad Institute |
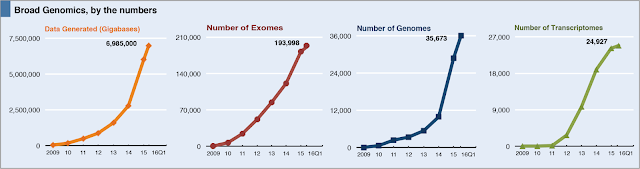
Here at Broad, our team of software engineers and methods developers have spent the last year working to re-architect our production sequencing environment for the cloud. This has been no small feat, especially as we had to build the plane while we flew it! It required an entirely new system for developing and deploying pipelines (which we call Cromwell), as well as a new framework for wet lab quality control that uncouples data generation from data processing.
 |
| Courtesy: Broad Institute of MIT and Harvard |
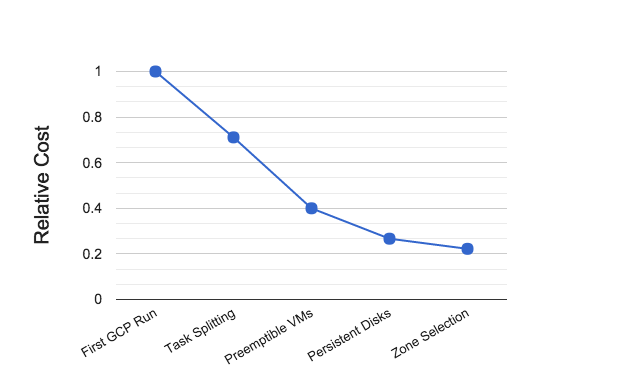
As of today, the largest and most important of our production pipelines, the Whole Genome Sequencing Pipeline, has been completely ported to the Google Cloud Platform (GCP). We are now beginning to run production jobs on GCP and will be switching over entirely this month. This switch has proved to be a very cost-effective decision. While the conventional wisdom is that public clouds can be more expensive, our experience is that cloud is dramatically cheaper. Consider the curve below that my colleague Kristian Cibulskis recently showed at GCP NEXT:

There is a similar story to be told on storage of the input and output data. Google Cloud Storage Nearline is a medium for storing DNA sequence alignments and raw data. Like most people in genomics, we access genetic variants data every day, but raw DNA sequences only a few times per year, such as when there is a new algorithm that requires raw data or a new assembly of the human genome. Nearline’s price/performance tradeoff is well-suited to data that’s infrequently accessed. By using Nearline, along with some compression tricks, we were able to reduce our storage costs by greater than 50%.
Altogether, we estimate that, by using GCP services for both compute and storage, we will be able to lower the total cost of ownership for storing and processing genomic data significantly relative to our on premise costs. Looking forward, we also see advantages for data sharing, particularly for large multi-group genome projects. An environment where the data can be securely stored and analyzed will solve problems of multiple groups copying and paying for transmission and storage of the same data.
Porting the GATK whole genome pipeline to the cloud is just the starting point. During the coming year, we plan to migrate the bulk of our production pipelines to the cloud, including tools for arrays, exomes, cancer genomes, and RNA-seq. Moreover, our non-exclusive relationship with Google is founded on the principle that our groups can leverage complementary skills to make products that can not only serve the needs of Broad, but also help serve the needs of researchers around the world. Therefore, as we migrate each of our pipelines to the cloud to meet our own needs, we also plan to make them available to the greater genomics community through a Software-as-a-Service model.
This is an exciting time for us at Broad. For more than a decade we have served the genomics community by acting as a hub for data generation; now, we are extending this mission to encompass not only sequencing services, but also data services. We believe that by expanding access to our tools and optimizing our pipelines for the cloud, will enable the community to benefit from the enormous effort we have invested. We look forward to expanding the scope of this mission in the years to come.
-
Labels:
- Health & Bioscience
- Product
Quick links
Other posts of interest
-

March 11, 2026
Exploring the feasibility of conversational diagnostic AI in a real-world clinical study- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

February 3, 2026
Collaborating on a nationwide randomized study of AI in real-world virtual care- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-
January 15, 2026
Unlocking health insights: Estimating advanced walking metrics with smartwatches- Health & Bioscience ·
- Human-Computer Interaction and Visualization
×
❮
❯