Generating zero-shot personalized portraits
November 11, 2024
Suraj Kothawade, Software Engineer, Core ML, and Sherry Ben, Staff Software Engineer, Google Research
A new AI model that can transform selfies into different artistic styles while keeping facial features recognizable.
Quick links
Recent advances in text-to-image and image-to-image (I2I) models have led to significant improvements in image quality and prompt adherence. However, existing I2I models often struggle with generating fine-grained details, particularly in challenging domains like human faces where preserving image likeness is crucial.
This post introduces a novel zero-shot I2I model specifically designed for personalized and stylized selfie generation. It effectively addresses the challenge of fine-grained image manipulation by combining two key capabilities: (1) personalization, which accurately preserves the similarity of the facial image in the input selfie, and (2) stylization, which faithfully applies the artistic style specified in the text prompt. This allows users to transform their selfies into a variety of styles while maintaining their unique facial features. We demonstrate the effectiveness of the model by showcasing its ability to generate high-quality, personalized, and stylized selfies.
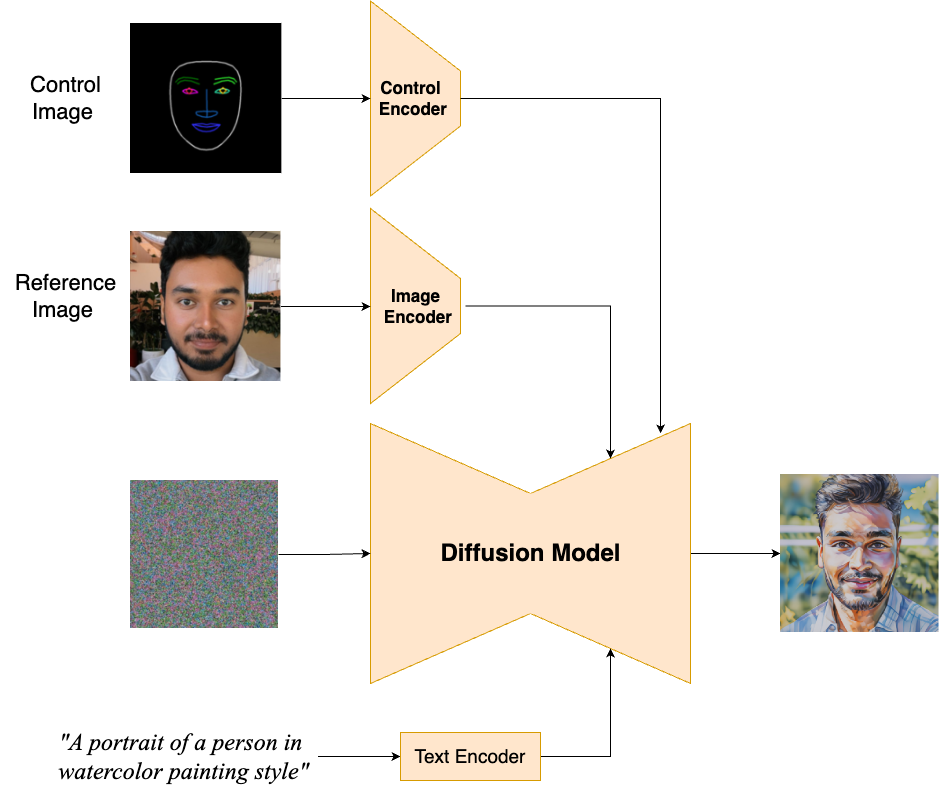
Model process: (a) The input provides the reference image. (b) The text prompt specifies the desired artistic style (e.g., "A portrait of watercolor style using pastel colors"). (c) The generated output image exhibits the specified style while preserving the subject's likeness.
Using adapters to capture face nuances
While text prompts work well for many image generation tasks (like "a cat wearing a hat") they can be limiting when it comes to generating images with specific and nuanced details. This is particularly true for faces, where capturing individual features and expressions with just words is incredibly difficult.
The model takes two inputs: an image of a person’s face, and a text prompt describing the desired style. We then use two kinds of "adapters," which are like mini-AI assistants, to help the foundation model understand the nuances of faces.
- Image adapter: This assistant focuses on unique features of a selfie image. This ensures the generated images truly look like the selfie image.
- Control adapter: This assistant analyzes the face’s pose and expression.
These assistants communicate with the foundation model using a technique called cross-attention, which allows them to blend information from the reference image, the desired style, and any expression seamlessly. This teamwork ensures the creation of a stylized image that's still unmistakably recognizable as the input image.
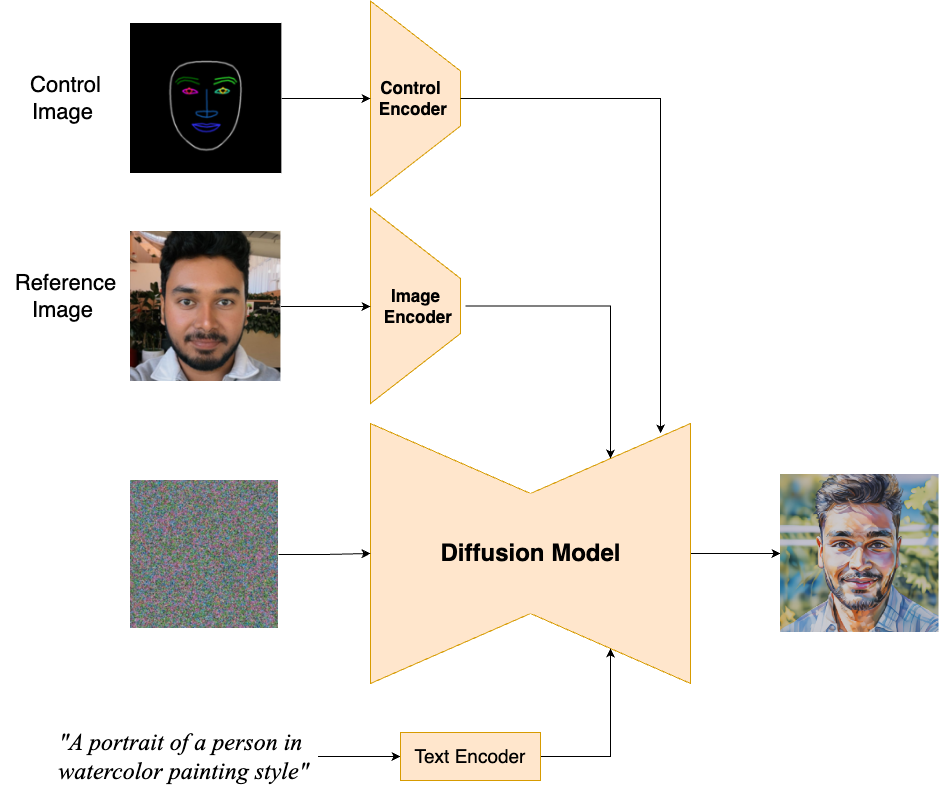
The model encodes two inputs: a reference image and a text prompt; control encoder is generated automatically. This encoded information guides the diffusion process, generating a stylized output image that retains the features depicted in the reference image while adhering to the style specified in the text prompt and incorporating the facial pose and expression analysis from the control adapter.
Creativity with a breadth of styles
Our model can generate faces in a plethora of styles. Below are some examples:
- 3D cartoon: Transform yourself into a 3D animated character.
- Watercolor painting: Capture the delicate beauty of a hand-painted portrait.
- Anime: Become the star of your own anime adventure.
- Pencil sketch: Embrace the classic elegance of a sketched portrait.

Model outputs from left to right: (a) Input portrait with prompt, “A person portrait stylized as 3D cartoon character..” (b-e) Generated outputs with the prompt adherence with minor adjustments to head pose.

Model outputs from left to right: (a) Input portrait with prompt, “A portrait of watercolor style using pastel colors..” (b-e) Generated outputs with the prompt adherence with minor adjustments to head pose.

Model outputs from left to right: (a) Input portrait with prompt, “A person portrait in a detailed anime style.” (b-e) Generated outputs with the prompt adherence with minor adjustments to head pose.

Model outputs from left to right: (a) Input portrait with prompt, “A 4B pencil sketch of a portrait.” (b-e) Generated outputs with the prompt adherence with minor adjustments to head pose.
Additionally, a user can prompt the model to modify the expression — to smiling, crying, or looking angry — while maintaining the image likeness and the chosen style.
Left: Input Image. Right three images: Model outputs (a) top row caption, “An image of smiling face in watercolor painting style”, (b) middle row caption, “An image of crying face in watercolor painting style”, (c) bottom row caption, “An image of angry face in watercolor painting style”.
Applying portrait stylization
This model is accessible on Imagen on Vertex AI. Detailed instructions for utilizing the model can be found in the accompanying user guide and in guidance for using Imagen responsibly. This framework enables personalized image stylization, allowing users to explore diverse artistic expressions while preserving the similarity of input facial images.
What’s next
Personalization of AI-generated images goes beyond generating headshots. Often, users want to personalize the full person, including features like body pose. Stay tuned for additional innovation that will enable further artistic expression.
Acknowledgements
This research has been supported by a large body of contributors, including Suraj Kothawade, Yu-Chuan Su, Xuhui Jia, Sherry Ben, Kelvin Chan, Igor Kibalchich, Chenxia Wu, Ting Yu, Yukun Ma, Nelson Gonzalez, Hexiang Hu, Inbar Mosseri, Sarah Rumbley, Roni Paiss, Yandong Li, Viral Carpenter, Nicole Brichtova, Jess Gallegos, Yang Zhao, Florian Schroff, Dmitry Lagun, Tanmay Shah, Keyang Xu, Hongliang Fei, Yukun Zhu, Yeqing Li, and Lawrence Chan. The authors of this post are now at Google DeepMind.
-
Labels:
- Generative AI
- Machine Intelligence
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence



