
Generating synthetic data with differentially private LLM inference
March 18, 2025
Alex Bie and Umar Syed, Research Scientists, Google Research
We describe an inference-only approach to generating differentially private synthetic data via prompting off-the-shelf large language models with many examples in parallel and aggregating their responses in a privacy-preserving manner.
Quick links
Differential privacy (DP) provides mathematically rigorous guarantees that an algorithm will not reveal details about an individual’s data. However, endowing algorithms with DP guarantees can add complexity to an already complex machine learning (ML) pipeline. This is especially true at the scale of modern ML, where pipelines are maintained and used by many different groups in an organization.
Differentially private synthetic data can help deal with this scaling issue by serving as an interface for model development teams to collaborate without downstream teams needing to understand DP. As described in a previous blog post, a common approach to generating DP synthetic data is to privately fine-tune large language models (LLMs), but this can be costly and has high minimum data requirements. The alternative to private training is differentially private prediction, where only model outputs are released with DP, instead of the model itself. While there is a large fixed cost to conduct private fine-tuning, differentially private prediction trades off quantity for quality, preferring to release a limited number of high-quality outputs rather than an unlimited number of low-quality ones.
In “Private prediction for large-scale synthetic text generation”, we present an inference-only approach for generating DP synthetic data. The approach works by prompting an off-the-shelf LLM with many sensitive examples in parallel, and aggregating their predictions with differential privacy. We address issues related to privacy budget and efficiency, which allow us to generate thousands of high-quality synthetic data points with DP guarantees and therefore greatly expand the set of potential applications.
Method
Our approach builds on pioneering prior work that introduced a method for distributing sensitive examples over independent prompts, running LLM inference (i.e., the mechanism LLMs use to generate realistic responses) on these prompts, and aggregating next-token predictions with differential privacy. Specifically, various prompts (each containing a single piece of sensitive data) are fed into an LLM. Then, predictions from all the prompts are aggregated and the next token is decoded with differential privacy. This ensures the selected token is not influenced strongly by any single piece of sensitive data. Finally, the selected token is appended to all prompts and the process repeats.

How the algorithm works.
Due to challenges in generating text while maintaining DP and computational efficiency, prior work focused on generating a small amount of data points (<10) to be used for in-context learning. We show that it’s possible to generate two to three orders of magnitude more data while preserving quality and privacy by solving issues related to the privacy budget and computational efficiency.
The privacy budget constrains the amount of output the model can release while maintaining a meaningful DP guarantee. DP operates by introducing randomness to mask the contribution of any single data point, enabling plausible deniability. We increase output while maintaining privacy by leveraging the inherent randomness in next-token sampling to ensure privacy.
This connects next-token sampling in language models with a DP technique called the exponential mechanism. This mechanism is used to approximately choose the best token option from a set of options, with each option accompanied by a score computed from sensitive data. It does so by sampling an option with probability proportional to the exponential of its score – this introduces randomness crucial to the DP guarantee. This operation is the same as softmax sampling in language models when viewing the set of all tokens as the options from which the model chooses. Based on this connection, we design a DP token sampling algorithm that is strongly aligned with the standard generation process of large language models.
For computational efficiency, we propose a new privacy analysis that lets us use the same contexts for each generation step and avoid recomputation. Our analysis uses a fixed batch of examples, whereas the DP guarantee of prior work required a fresh batch of sensitive examples to be generated for each token. But using a fresh batch necessitates changing the input prompt for each sampled token, which is incompatible with standard inference efficiency techniques such as KV caching.
Finally, we also introduce a public drafter, a model that bases its next token predictions solely on already generated synthetic text, rather than sensitive data. Via the sparse vector technique, we only pay a privacy cost when the drafter’s proposals disagree with predictions made from sensitive data. Otherwise, we accept the drafter’s suggestion and do not expend any privacy budget. We find this is particularly effective for structured data, where many formatting-related tokens can be predicted by the drafter without looking at sensitive data.
Results
Treating benchmark ML datasets as stand-ins for sensitive data, we ran our algorithm with Gemma models to generate synthetic versions of these datasets. We evaluated how useful the resulting synthetic data is for downstream tasks, namely in-context learning with GPT-3, and for fine-tuning BERT models. The aim is to understand to what extent we can replace real sensitive datasets with our DP synthetic datasets in ML applications.
GPT-3 in-context learning
We prompted GPT-3 with real and synthetic few-shot examples from benchmark datasets (AGNews, DBPedia, TREC, MIT-G, and MIT-D) and evaluated test set accuracy.
We determine the accuracy of classification when GPT-3 is given k examples from the data source as reference before being asked for the answer. Our improvements allow us to generate more synthetic data while preserving privacy and quality. We demonstrate improved in-context learning accuracy at the same privacy level, as a consequence of our method’s ability to generate more high-quality synthetic reference examples. Notably, our synthetic data at 64 shots improves over 4 shots of real data (an approximate upper bound on the performance of prior methods that limited themselves to generating 4 synthetic examples).
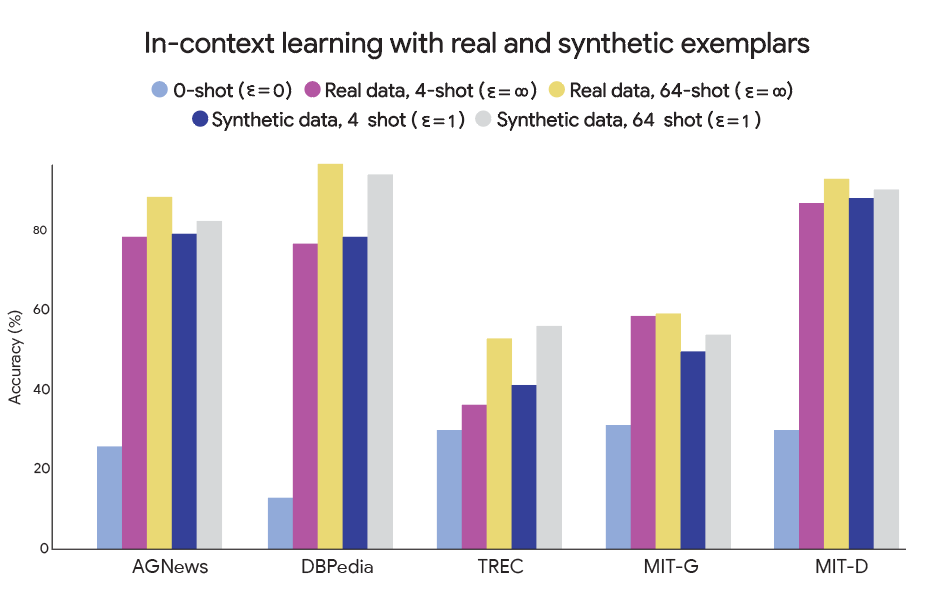
GPT-3 in-context learning results. We compare the accuracy of GPT-3 when given few-shot examples from real and synthetic data. Synthetic data is comparable to real data, and we demonstrate improved accuracies when using more of our synthetic data.
BERT fine-tuning on Yelp synthetic data
Next, we fine-tuned BERT models on synthetic Yelp data generated from DP inference and compared them to the DP fine-tuning results we discussed in a previous blog post. While it’s possible to train reasonable models from data generated from DP inference, our results showed that there remains a large gap between inference and the best fine-tuning approaches.
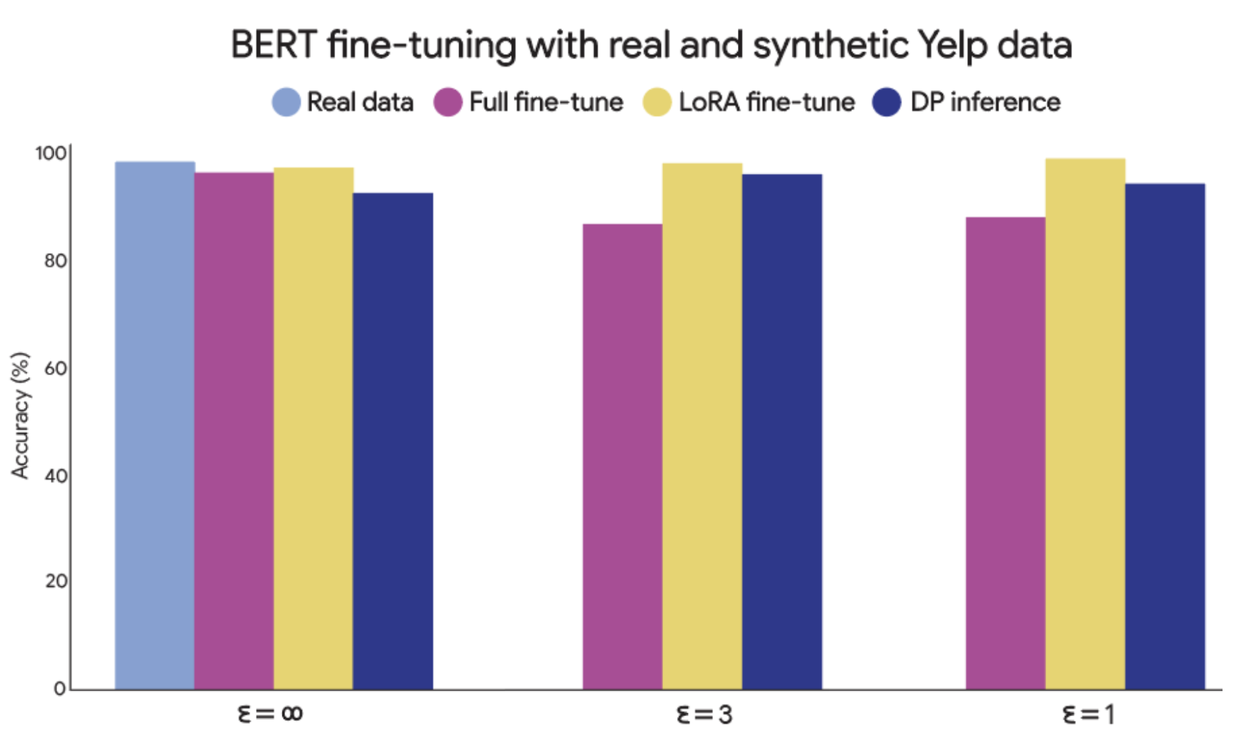
BERT fine-tuning results on Yelp synthetic data. We compared the accuracy of BERT models trained on real and synthetic data. DP inference can generate enough data to finetune BERT classifiers, but accuracy falls short of the best DP fine-tuning method.
Limited data regime
For limited data regimes, DP inference outperforms DP fine-tuning. On a 1K subset of AGNews, the 16-shot GPT-3 in-context learning accuracy was 68.1%, compared to 80.1% for DP inference on the same dataset and at the same privacy level.
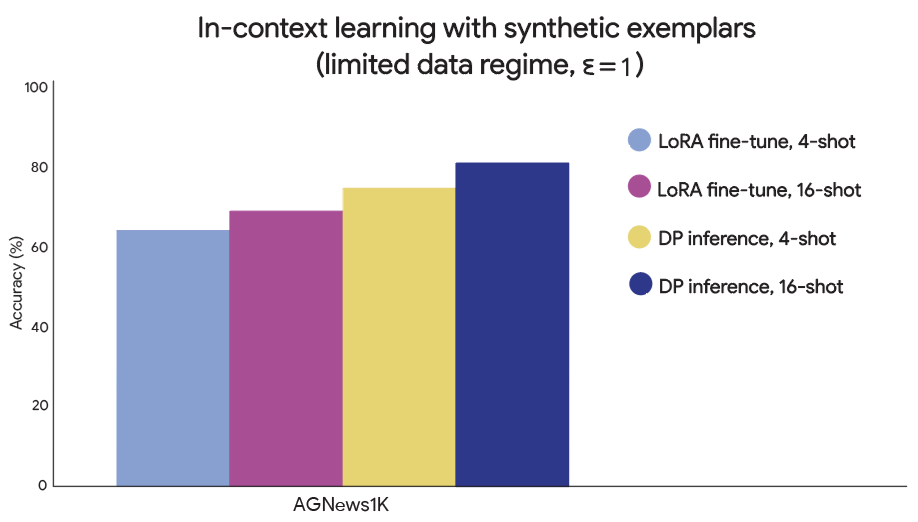
GPT-3 in-context learning results in the limited data regime. We compare the accuracy of GPT-3 when given few-shot examples generated from a small subset of AGNews. DP inference outperforms DP fine-tuning in the limited data regime.
What’s next?
Differentially private language model inference is a flexible and lightweight approach to generating DP synthetic data. Our work has shown that DP inference can be scaled up to generate large synthetic corpora.
At scale, quality falls short of DP fine-tuning. However, analogous to tradeoffs between fine-tuning and prompt engineering, DP inference allows for fast iteration cycles — the time to first synthetic example is minutes as opposed to hours. Another important application is latency-constrained applications (e.g., agents) for which batch generation is unsuitable.
We plan to explore further applications of DP inference and continue to make improvements to the quality and quantity of generated examples.
Acknowledgements
This work is the result of a collaboration between multiple people across Google Research and Google DeepMind, including (in alphabetical order by last name): Kareem Amin, Weiwei Kong, Alexey Kurakin, Natalia Ponomareva, Andreas Terzis, Sergei Vassilvitskii.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 31, 2026
Safeguarding cryptocurrency by disclosing quantum vulnerabilities responsibly- Algorithms & Theory ·
- Quantum ·
- Security, Privacy and Abuse Prevention



