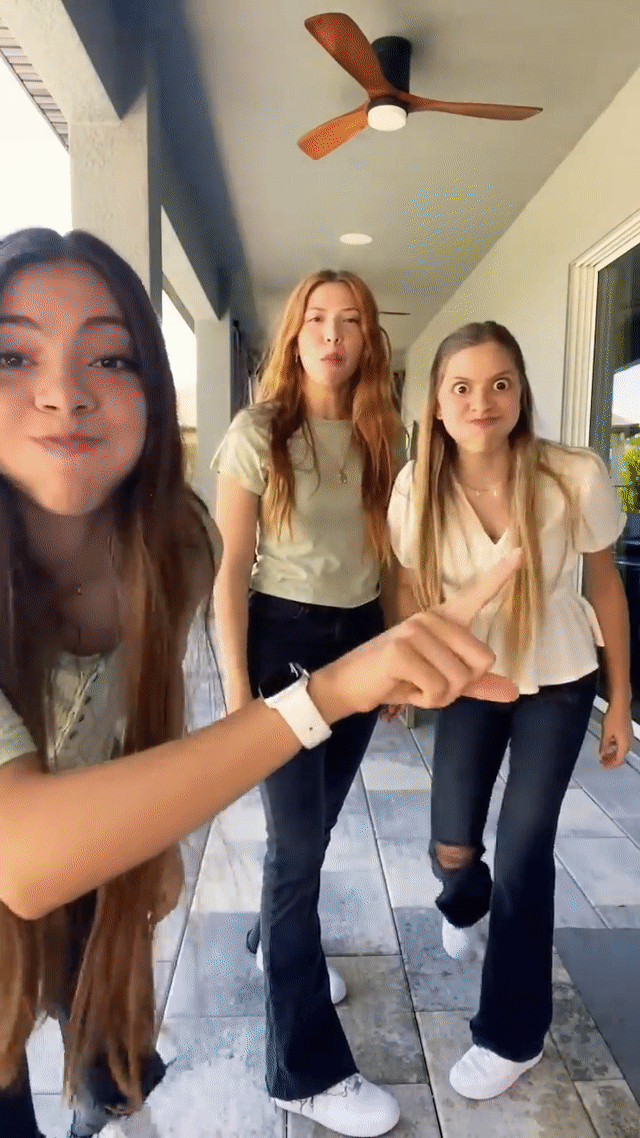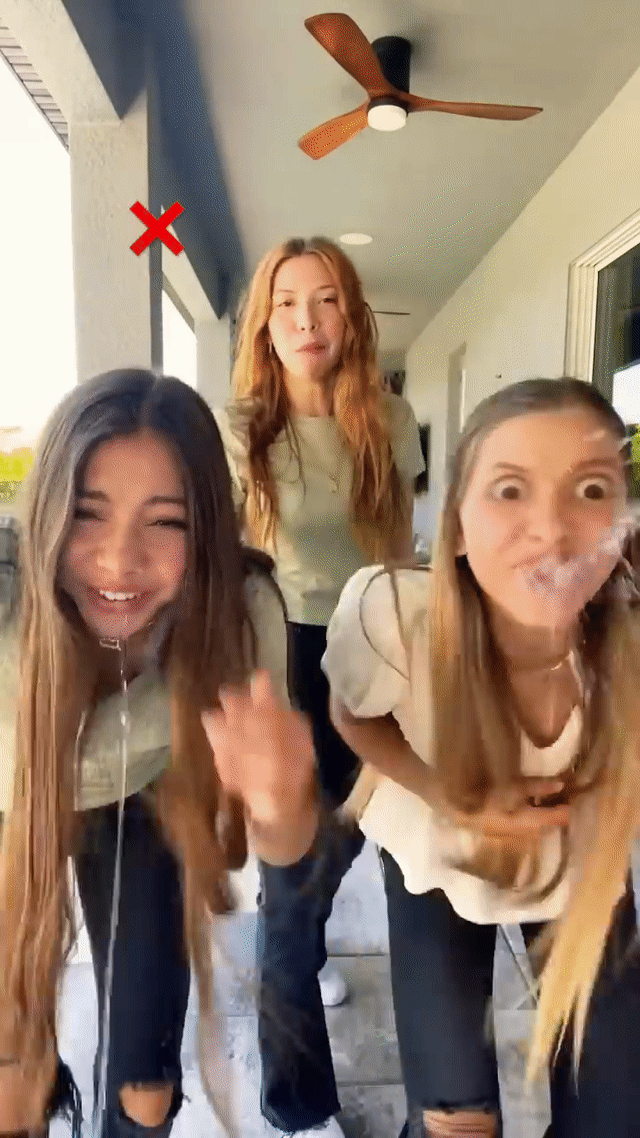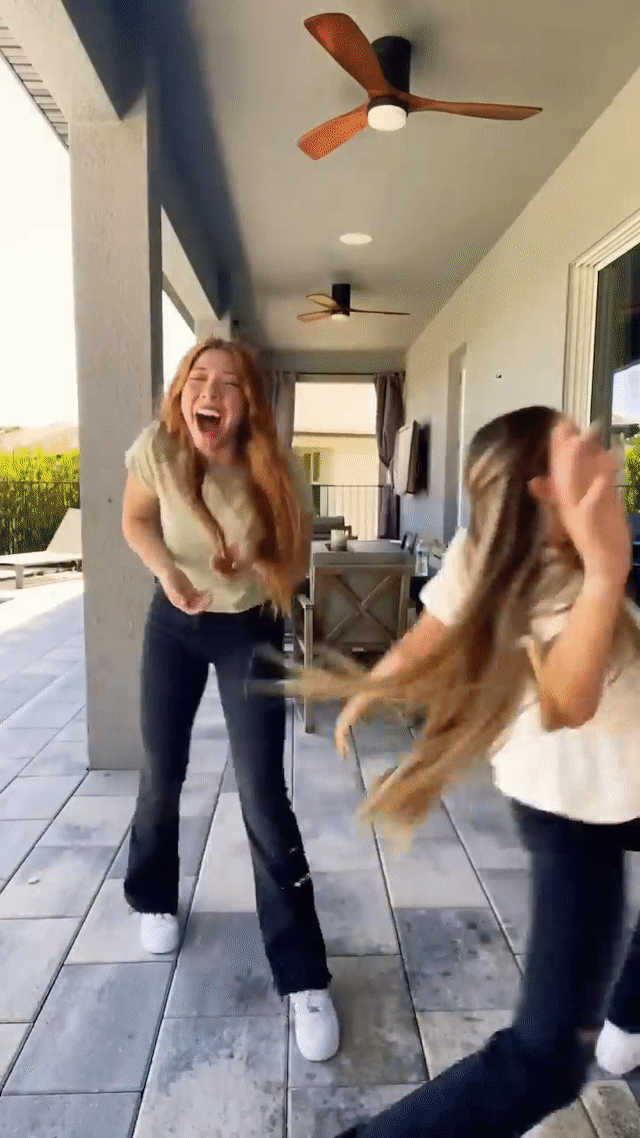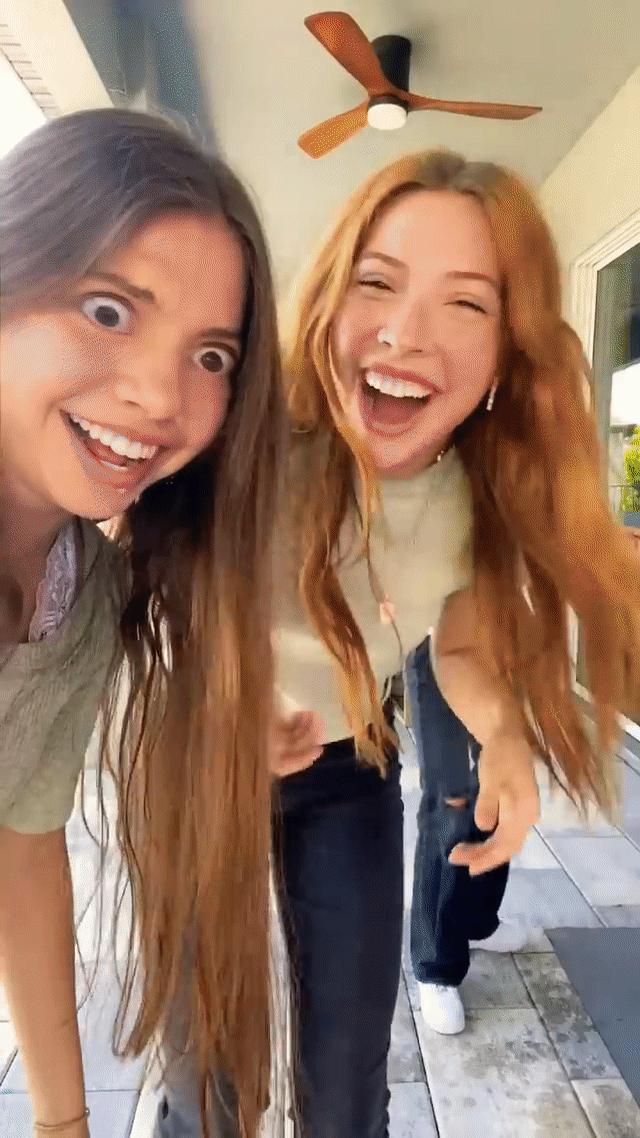From massive models to mobile magic: The tech behind YouTube real-time generative AI effects
August 21, 2025
Andrey Vakunov, Software Engineer, Google Cloud, and Adam Svystun, Software Engineer, YouTube
We detail how YouTube delivers real-time generative AI effects on mobile devices by using knowledge distillation and on-device optimization with MediaPipe to overcome computational limitations while preserving user identity.
Quick links
Effects are a huge part of the fun on YouTube Shorts, but for them to feel magical, they need to work in real-time in the camera as the creator is recording. This presents a challenge: how do we apply the latest capabilities of large generative AI models, such as cartoon style transfer, on creators' phones?
Our solution is a pipeline that distills the capability of a large model into a much smaller one focused on a single task. This narrowing of scope creates a compact, efficient model that can run directly on a phone, processing video frame-by-frame. Using this method, we've launched over 20 real-time effects for YouTube creators on Shorts. In this post, we'll detail how we accomplish this: including data curation, training, and the on-device setup.

It all starts with data
The foundation of our work is high-quality data. We began by building a face dataset using properly licensed images. We meticulously filtered our datasets to ensure they were diverse and uniformly distributed across different genders, ages, and skin tones (as measured by the Monk Skin Tone Scale) to build effects that work well for everyone.
The teacher and the student
Our approach revolves around a concept called knowledge distillation, which uses a "teacher–student" model training method. We start with a "teacher" — a large, powerful, pre-trained generative model that is an expert at creating the desired visual effect but is far too slow for real-time use. The type of teacher model varies depending on the goal. Initially, we used a custom-trained StyleGAN2 model, which was trained on our curated dataset for real-time facial effects. This model could be paired with tools like StyleCLIP, which allowed it to manipulate facial features based on text descriptions. This provided a strong foundation. As our project advanced, we transitioned to more sophisticated generative models like Google DeepMind’s Imagen. This strategic shift significantly enhanced our capabilities, enabling higher-fidelity and more diverse imagery, greater artistic control, and a broader range of styles for our on-device generative AI effects.
The "student" is the model that ultimately runs on the user’s device. It needs to be small, fast, and efficient. We designed a student model with a UNet-based architecture, which is excellent for image-to-image tasks. It uses a MobileNet backbone as its encoder, a design known for its performance on mobile devices, paired with a decoder that utilizes MobileNet blocks.
Distillation: Iteratively teaching the student
To achieve production-ready effects, we developed a robust training methodology that addresses the limitations of synthetic data distillation, which often leads to artifacts and reduced high-frequency details. Our approach leverages real-world data to generate "image pairs" and train student models to enable a more efficient hyperparameter search.
The distillation process for training the smaller student model involves two key steps:
- Data Generation: We process a large dataset of images through the teacher model to create thousands of "before and after" image pairs. During generation, we incorporate augmentations, such as adding AR glasses and sunglasses, and occlusion with synthetic hands. We also use Pivotal Tuning Inversion to preserve user identity.
- Student Training: The student model is then trained on these paired images. We utilize a combination of L1, LPIPS, Adaptive, and Adversarial loss functions to ensure the student's output is not only numerically accurate but also visually realistic and aesthetically pleasing. Furthermore, we employ a neural architecture search to optimize model architecture parameters (like "depth multiplier" and "width multiplier") allowing us to identify efficient architectures tailored to various use cases and effect types.
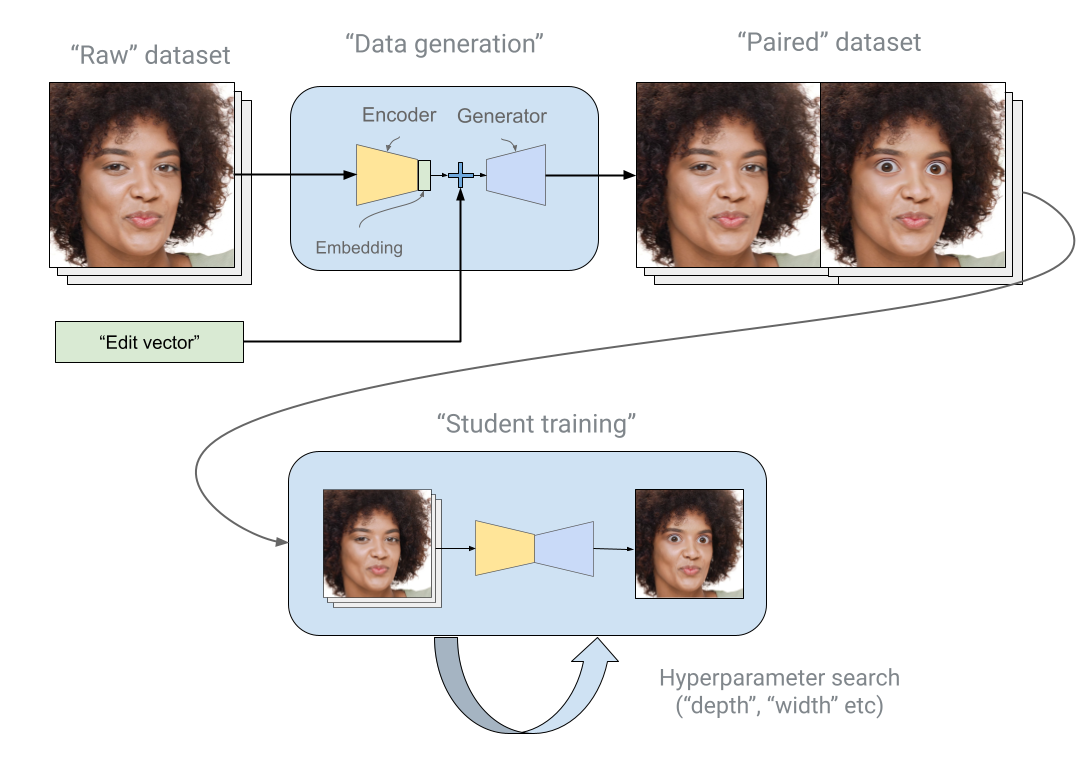
High-level schema of distillation pipeline the “Never Blink” effect.
A critical challenge: Preserving user identity
The "editing" of the image happens in "latent" space, which is a compressed numerical representation of the image where meaningful features are encoded. The process of converting raw pixels to latent representation is called “inversion”. A major challenge in image-to-image generative models for facial effects is preserving a person's identity because the effect regenerates the entire frame. A naïve approach can easily distort key features, changing a person's skin tone, glasses, or clothing, resulting in an output that no longer looks like them. This issue, often called the "inversion problem", happens when a model struggles to accurately represent a real person's face in its latent space.
To solve this, we employ a technique called pivotal tuning inversion (PTI). Here is a simplified version of how it works:
- The original image is transformed into an embedding, referred to as a pivotal code, using an encoder and generating an initial inversion with a generator (see below). This is typically a representation similar to the original image, but not identical (e.g., skin tone and facial details may not be accurate).
- We fine-tune a generator using the PTI iterative process to preserve face identity and details. This results in a new generator that performs better for a specific face and its embedding neighborhood.
- We apply the desired effect by editing the embedding, typically using a prepared vector created with techniques such as StyleCLIP.
- We generate the final output image with an edited face using a fine-tuned generator and an edited embedding.
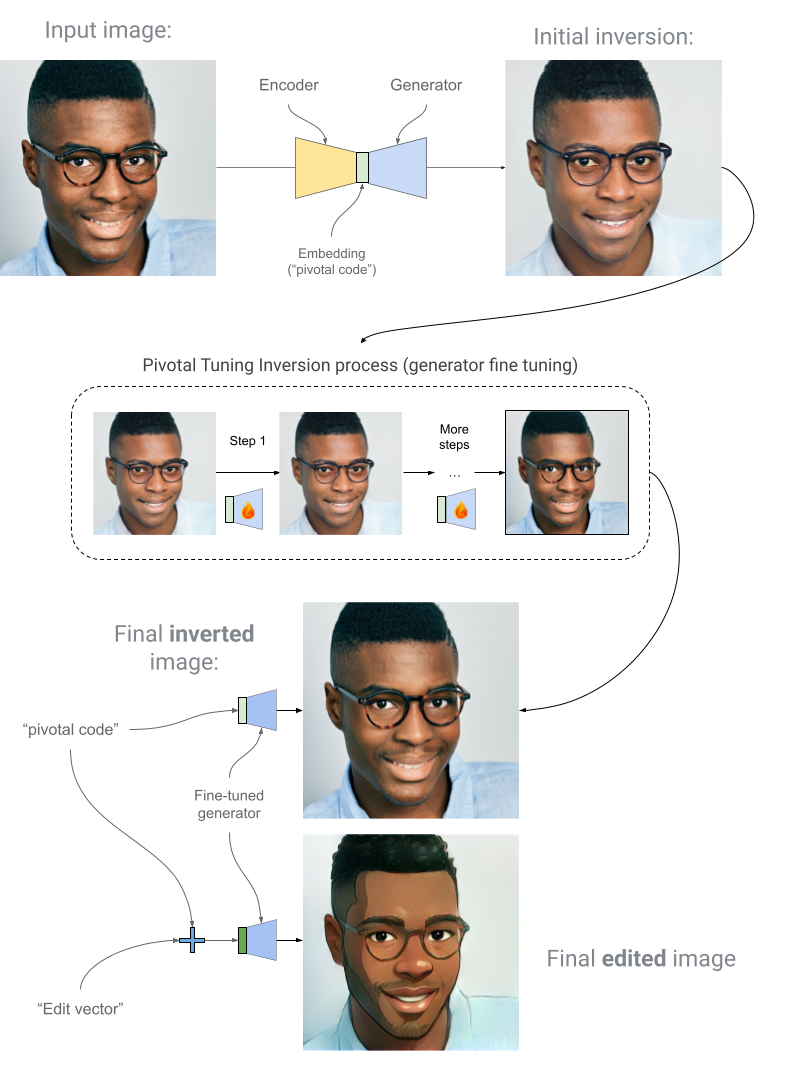
The pipeline fine-tunes a generator to the user's unique face, allowing us to apply edits in the latent space without losing their likeness in the final image. Note that the initial inversion may lack some fine details, resulting in a slightly different appearance.
Running on device with MediaPipe from Google AI Edge
Once the student model is trained, it needs to be integrated into a pipeline that can run efficiently on a phone. We built our on-device solution using MediaPipe, our open-source framework for building cross-platform multimodal ML pipelines, from Google AI Edge. The final inference pipeline works as follows:
- First, the MediaPipe Face Mesh module detects one or more faces in the video stream.
- Because student models are sensitive to face alignment, the pipeline computes a stable, rotated crop of the face to ensure consistency.
- This cropped image is converted into a tensor and fed into our lean student model.
- The student model applies the effect (e.g., a smile or a cartoon style), and the resulting image is warped back and seamlessly composited onto the original video frame in real-time.
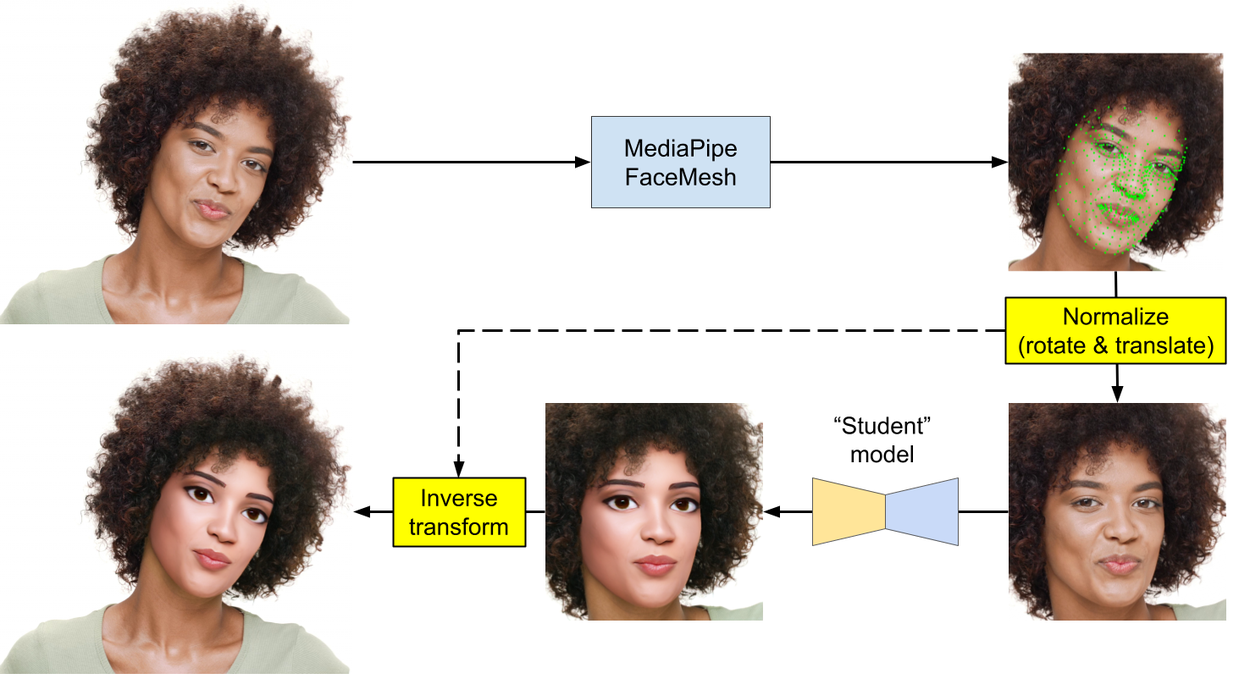
On-device inference pipeline: MediaPipe Face Mesh detects, crops, and aligns faces for the student model.
These experiences need to run at a minimum of 30 frames per second to feel responsive to the user, so the pipeline must execute faster than 33 milliseconds per frame. The model inference latencies are ~6 ms for Pixel 8 Pro on Google Tensor G3 and 10.6 ms for iPhone 13 GPU. We invested heavily in optimizing these pipelines for a wide range of mobile devices, leveraging GPU acceleration to ensure a smooth experience for everyone.
The result: Enhanced mobile creativity
This technology has been a crucial element of YouTube Shorts since 2023, enabling the successful launch of numerous popular features, including expression-based effects (e.g., Never blink), Halloween-themed masks (e.g., Risen zombie), and immersive full-frame effects (e.g., Toon 2). These significantly expanded creative possibilities for YouTube video creators.

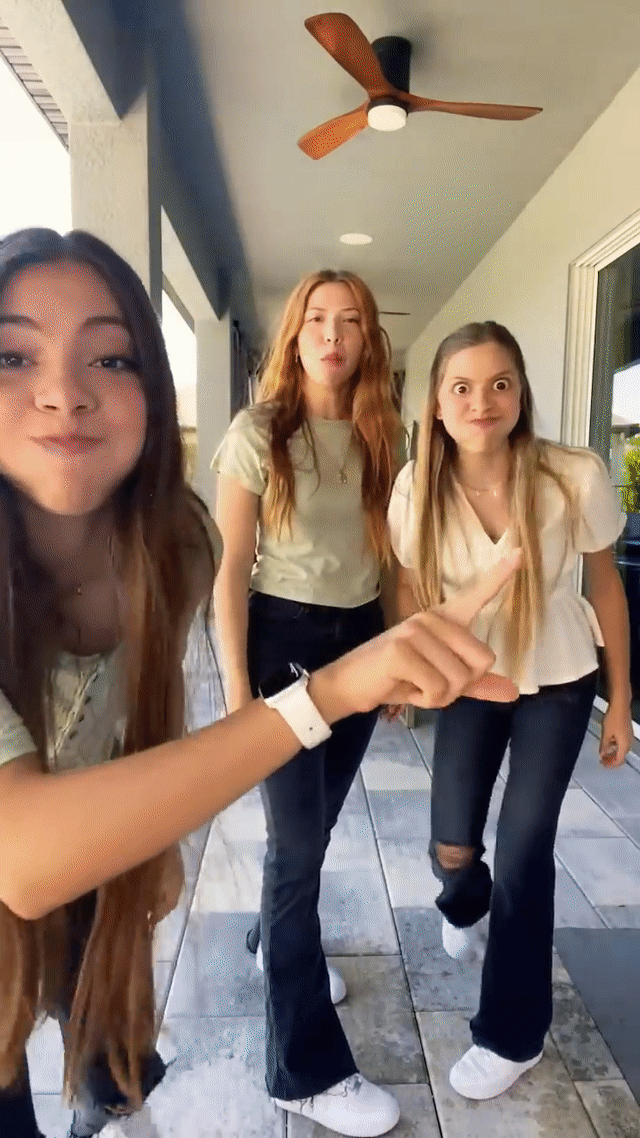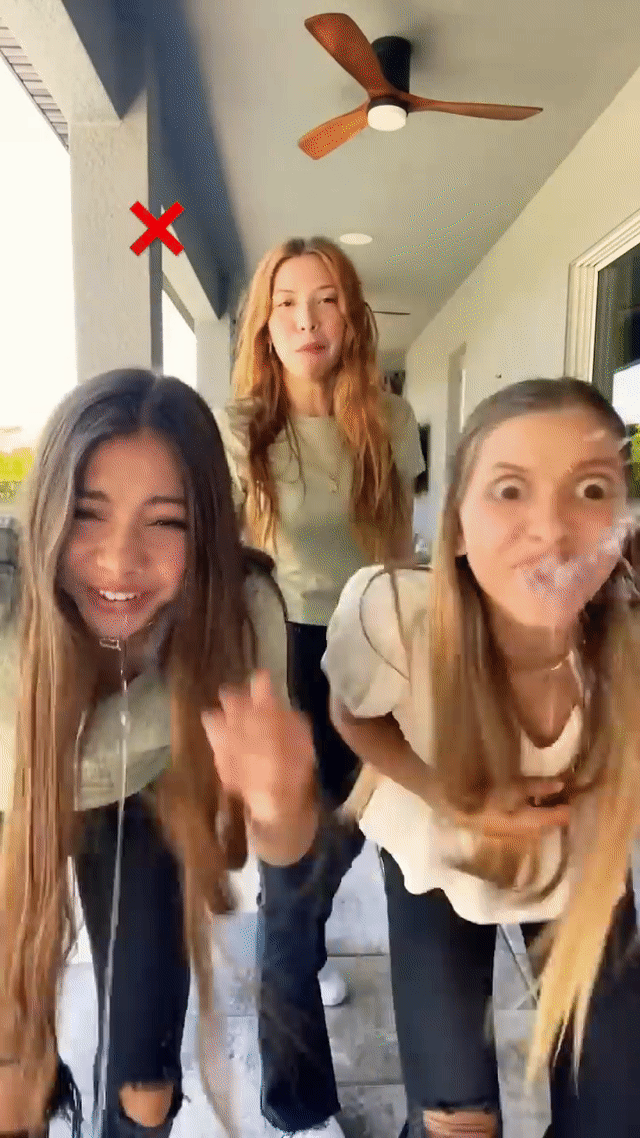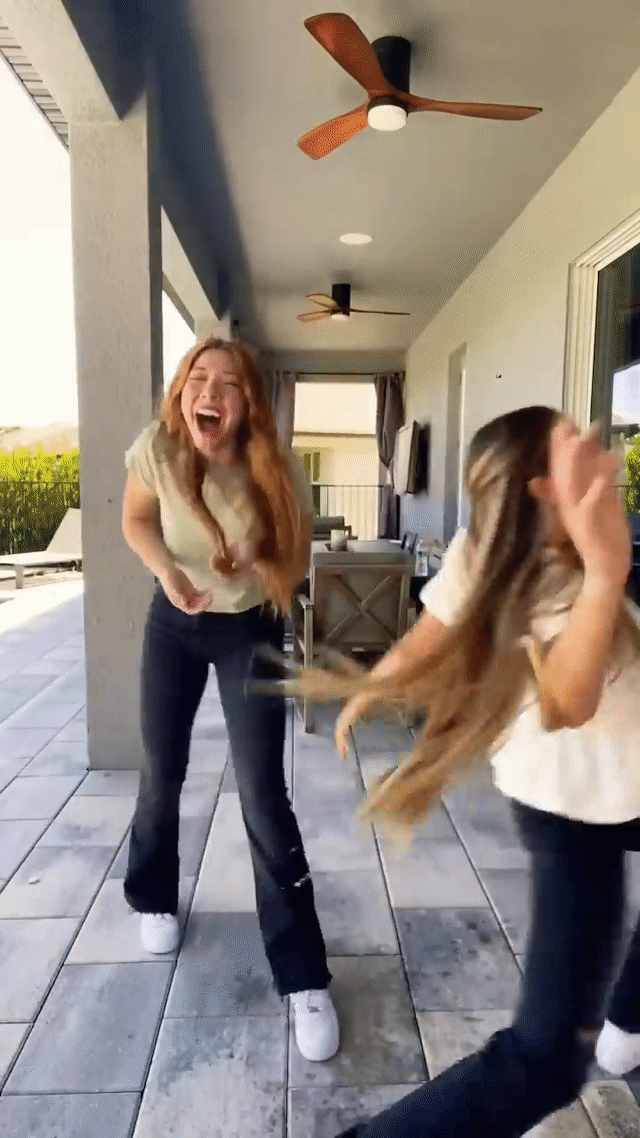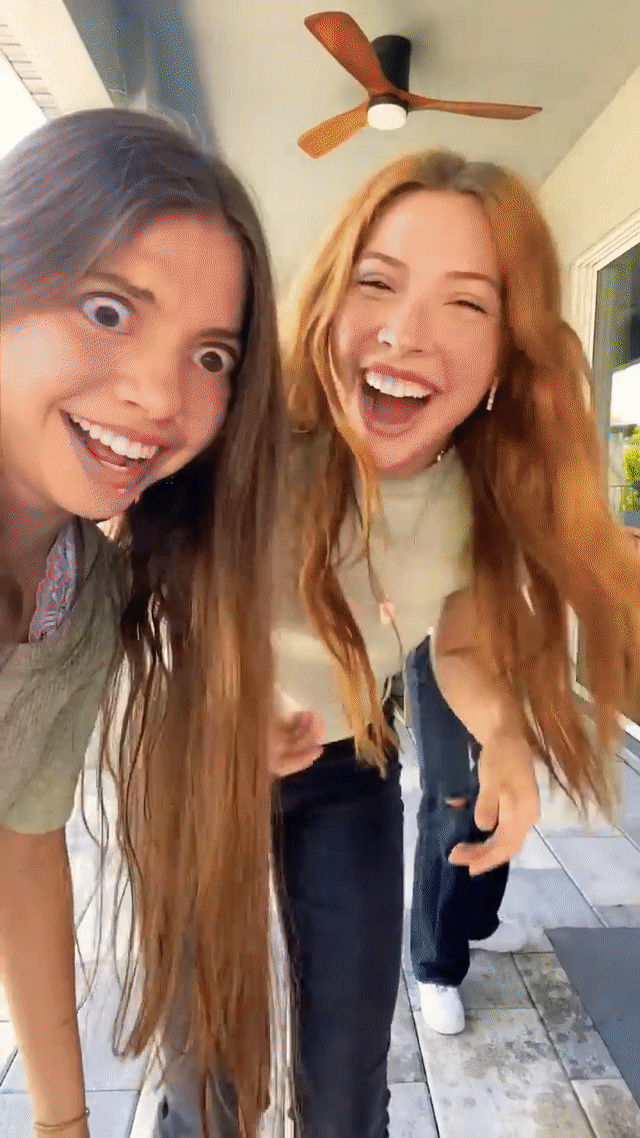

Real-time generative AI effects in action on YouTube Shorts, including expression-based effects like “Always smile” (left) and "Never blink" (middle) and Halloween-themed masks like "Risen zombie" (right).
By bridging the gap between massive generative models and the constraints of mobile hardware, we are defining what is technically possible for real-time, on-device generative effects. This is just the beginning; we are actively working on integrating our newest models, like Veo 3, and significantly reducing latency for entry-level devices, further democratizing access to cutting-edge generative AI in YouTube Shorts.
Acknowledgements
We would like to thank our co-authors and collaborators: Sarah Xu, Maciej Pęśko, Paweł Andruszkiewicz, Jacob Rockwell, Ronny Votel, Robert (Guohui) Wang, Tingbo Hou, Karthik Raveendran, Jianing Wei, Matthias Grundmann, Omer Tov, Ariel Ephrat, Shiran Zada, and Inbar Mosseri.
Quick links
Other posts of interest
-

March 12, 2026
Protecting cities with AI-driven flash flood forecasting- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 11, 2026
Exploring the feasibility of conversational diagnostic AI in a real-world clinical study- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence