Free Language Lessons for Computers
December 3, 2013
Posted by Dave Orr, Google Research Product Manager
Quick links
Not everything that can be counted counts.
Not everything that counts can be counted.
- William Bruce Cameron
50,000 relations from Wikipedia. 100,000 feature vectors from YouTube videos. 1.8 million historical infoboxes. 40 million entities derived from webpages. 11 billion Freebase entities in 800 million web documents. 350 billion words’ worth from books analyzed for syntax.
These are all datasets that we’ve shared with researchers around the world over the last year from Google Research.
But data by itself doesn’t mean much. Data is only valuable in the right context, and only if it leads to increased knowledge. Labeled data is critical to train and evaluate machine-learned systems in many arenas, improving systems that can increase our ability to understand the world. Advances in natural language understanding, information retrieval, information extraction, computer vision, etc. can help us tell stories, mine for valuable insights, or visualize information in beautiful and compelling ways.
That’s why we are pleased to be able to release sets of labeled data from various domains and with various annotations, some automatic and some manual. Our hope is that the research community will use these datasets in ways both straightforward and surprising, to improve systems for annotation or understanding, and perhaps launch new efforts we haven’t thought of.
Here’s a listing of the major datasets we’ve released in the last year, or you can subscribe to our mailing list. Please tell us what you’ve managed to accomplish, or send us pointers to papers that use this data. We want to see what the research world can do with what we’ve created.
50,000 Lessons on How to Read: a Relation Extraction Corpus
What is it: A human-judged dataset of two relations involving public figures on Wikipedia: about 10,000 examples of “place of birth” and 40,000 examples of “attended or graduated from an institution.”
Where can I find it: https://code.google.com/p/relation-extraction-corpus/
I want to know more: Here’s a handy blog post with a broader explanation, descriptions and examples of the data, and plenty of links to learn more.
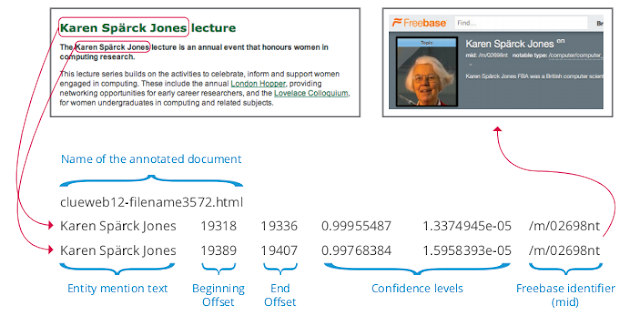
11 Billion Clues in 800 Million Documents
What is it: We took the ClueWeb corpora and automatically labeled concepts and entities with Freebase concept IDs, an example of entity resolution. This dataset is huge: nearly 800 million web pages.
Where can I find it: We released two corpora: ClueWeb09 FACC and ClueWeb12 FACC.
I want to know more: We described the process and results in a recent blog post.

Features Extracted From YouTube Videos for Multiview Learning
What is it: Multiple feature families from a set of public YouTube videos of games. The videos are labeled with one of 30 categories, and each has an associated set of visual, auditory, and and textual features.
Where can I find it: The data and more information can be obtained from the UCI machine learning repository (multiview video dataset), or from Google’s repository.
I want to know more: Read more about the data and uses for it here.
40 Million Entities in Context
What is it: A disambiguation set consisting of pointers to 10 million web pages with 40 million entities that have links to Wikipedia. This is another entity resolution corpus, since the links can be used to disambiguate the mentions, but unlike the ClueWeb example above, the links are inserted by the web page authors and can therefore be considered human annotation.
Where can I find it: Here’s the WikiLinks corpus, and tools can be found to help use this data on our partner’s page: Umass Wiki-links.
I want to know more: Other disambiguation sets, data formats, ideas for uses of this data, and more can be found at our blog post announcing the release.

Distributing the Edit History of Wikipedia Infoboxes
What is it: The edit history of 1.8 million infoboxes in Wikipedia pages in one handy resource. Attributes on Wikipedia change over time, and some of them change more than others. Understanding attribute change is important for extracting accurate and useful information from Wikipedia.
Where can I find it: Download from Google or from Wikimedia Deutschland.
I want to know more: We posted a detailed look at the data, the process for gathering it, and where to find it. You can also read a paper we published on the release.


Note the change in the capital of Palau.
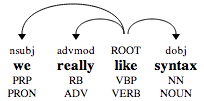
Syntactic Ngrams over Time
What is it: We automatically syntactically analyzed 350 billion words from the 3.5 million English language books in Google Books, and collated and released a set of fragments -- billions of unique tree fragments with counts sorted into types. The underlying corpus is the same one that underlies the recently updated Google Ngram Viewer.
Where can I find it: http://commondatastorage.googleapis.com/books/syntactic-ngrams/index.html
I want to know more: We discussed the nature of dependency parses and describe the data and release in a blog post. We also published a paper about the release.
Dictionaries for linking Text, Entities, and Ideas
What is it: We created a large database of pairs of 175 million strings associated with 7.5 million concepts, annotated with counts, which were mined from Wikipedia. The concepts in this case are Wikipedia articles, and the strings are anchor text spans that link to the concepts in question.
Where can I find it: http://nlp.stanford.edu/pubs/crosswikis-data.tar.bz2
I want to know more: A description of the data, several examples, and ideas for uses for it can be found in a blog post or in the associated paper.
Other datasets
Not every release had its own blog post describing it. Here are some other releases:
- Automatic Freebase annotations of Trec’s Million Query and Web track queries.
- A set of Freebase triples that have been deleted from Freebase over time -- 63 million of them.
-
Labels:
- Natural Language Processing
Quick links
Other posts of interest
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets
×
❮
❯