Fluid Annotation: An Exploratory Machine Learning–Powered Interface for Faster Image Annotation
October 22, 2018
Posted by Jasper Uijlings and Vittorio Ferrari, Research Scientists, Machine Perception
Quick links
The performance of modern deep learning–based computer vision models, such as those implemented by the TensorFlow Object Detection API, depends on the availability of increasingly large, labeled training datasets, such as Open Images. However, obtaining high-quality training data is quickly becoming a major bottleneck in computer vision. This is especially the case for pixel-wise prediction tasks such as semantic segmentation, used in applications such as autonomous driving, robotics, and image search. Indeed, traditional manual labeling tools require an annotator to carefully click on the boundaries to outline each object in the image, which is tedious: labeling a single image in the COCO+Stuff dataset takes 19 minutes, while labeling the whole dataset would take over 53k hours!
 |
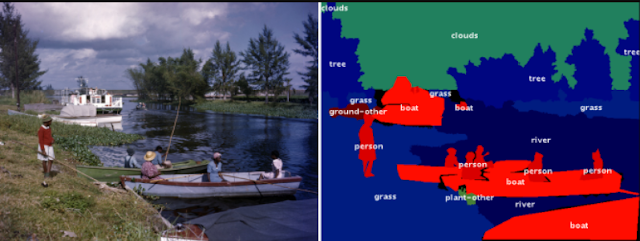
| Example of image in the COCO dataset (left) and its pixel-wise semantic labeling (right). Image credit: Florida Memory, original image. |
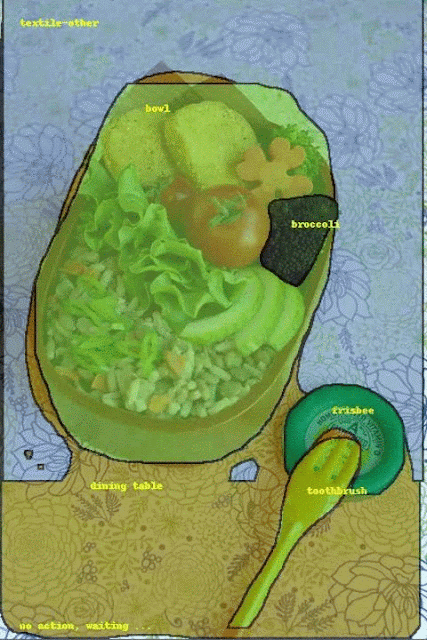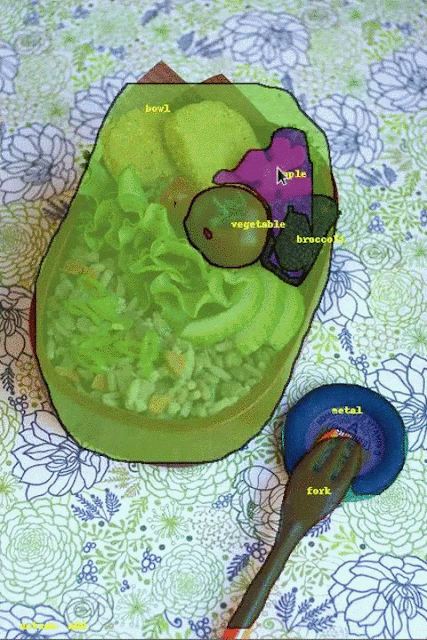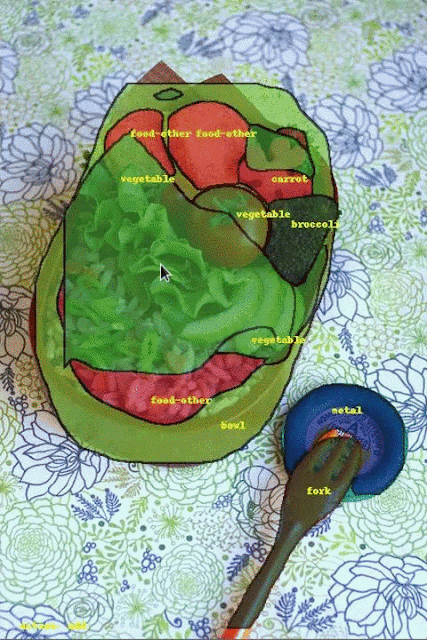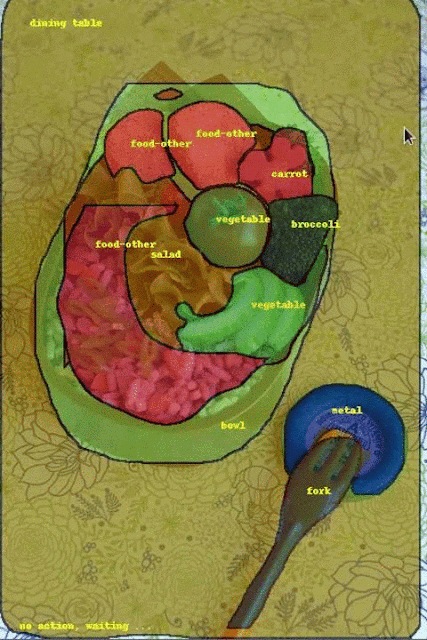
Fluid Annotation starts from the output of a strong semantic segmentation model, which a human annotator can modify through machine-assisted edit operations using a natural user interface. Our interface empowers annotators to choose what to correct and in which order, allowing them to effectively focus their efforts on what the machine does not already know.
 |
| Visualization of the fluid annotation interface in action on image from COCO dataset. Image credit: gamene, original image. |
 |
| Comparison of annotations using traditional manual labeling tools (middle column) and fluid annotation (right) on three COCO images. While object boundaries are often more accurate when using manual labeling tools, the biggest source of annotation differences is because human annotators often disagree on the exact object class. Image Credits: sneaka, original image (top), Dan Hurt, original image (middle), Melodie Mesiano, original image (bottom). |
Acknowledgements
This work was done in collaboration with Misha Andriluka. Special thanks to Christine Sugrue for creating the fluid annotation demo. We also thank Anna Ukhanova and Damien Henry for their valuable input.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
×
❮
❯