FireBench: Using high-performance computing to advance machine learning and wildfire research
July 16, 2024
Qing Wang, Software Engineer, Google Research, Athena Team, and Tyler Russell, Technical Program Manager, Google Research
Quick links
The severity and frequency of large wildfires has increased significantly over recent years due to factors ranging from climate and weather pattern changes to increased human activities in wildland-urban interfaces. While wildfires play an important role in some forest’s natural cycle, extreme fires pose serious threats to communities and ecosystems. Frequent wildfires can disrupt, damage, and destroy infrastructure, livelihoods, lives, and properties. For example, the recent surge in US wildfires has expanded geographically with the annual burned-area estimated to be approaching 7M acres, annual wildfire economic burden to be between $394B and $893B, and annual wildfire CO2 emissions exceeding 50% of combustion emissions. In fact, greenhouse gas emissions from wildfires can wipe out years of emissions savings. This is expected to worsen worldwide, not only in fire-prone areas within the US, Canada, Australia, and southern Europe, but also in regions that haven’t had a history of extensive wildfires.
Firefighters and the research community have been studying paths to better understand and manage wildfire impacts. With rapid machine learning (ML) and high performance computing advancements, Google has explored ways to apply this technology to improve predictions for fire-risk assessment and fire resilience to help communities and authorities manage wildfires. Some examples include using AI for wildfire boundary tracking, using ML to predict fire spread from remote-sensing data, and releasing an efficient and scalable high-fidelity TPU-powered simulation framework that can reduce data scarcity for ML-based fire-prediction model development. However, a key element to effectively leveraging ML technologies for fire management is finding high-quality data, which can be difficult.
To that end, in “FireBench: A High-fidelity Ensemble Simulation Framework for Exploring Wildfire Behavior and Data-driven Modeling” we introduce a high-resolution, simulation dataset designed to advance wildfire research. FireBench enables investigations of wildfire spread behavior and the coupling between atmospheric hydrodynamics and fire physics by extending beyond just fire states to also include a comprehensive list of flow field variables in three dimensions. It also supports the development of robust and interpretable ML models by capturing the underlying dependencies between relevant variables. To provide the research community with the insights needed to mitigate the impact of wildfires, we have released the FireBench dataset on the Google Cloud Platform.
The FireBench dataset
High-fidelity wildfire simulations are computationally expensive, making it challenging to generate a comprehensive dataset for a systematic parametric study. To that end, in fall 2023 we developed and released SWIRL-FIRE, a high-performance computational fluid dynamics framework optimized for TPU architecture. SWIRL-FIRE leverages numerical methods and parallelisation strategies that enable large-scale simulations at a fraction of the cost of common approaches. This framework is integrated with the optimization platform Vizier for automated simulation management and data processing. This approach enabled us to generate the 1.36 PiB FireBench dataset in less than a week using only 200k TPU hours.
The FireBench dataset was generated by considering 117 different wind speeds and slope combinations. These factors are crucial for predicting fire-spread behavior, including eruptive fires, but understanding their combined effects presents experimental challenges due to scale requirements and atmospheric uncertainties. SWIRL-FIRE overcomes these limitations to produce high-fidelity numerical simulations with precisely controlled simulation configurations and physical parameters.
Fire spread over 150 s on a 15° angle slope that is 1.5 km long, with an inlet wind speed of 6 m/s measured from 10 m above the ground.
Results
As a demonstration of the dataset, we plot below the instantaneous flow-field results for nine ensembles out of the 117 in the dataset. The snapshots are taken at a representative time when the fire front reaches the middle of the slope.

3D visualizations of fire propagation for nine ensembles when the mean location of the fire front is at 500 m. The volume renderings are of the potential temperature (indicated by the fire and smoke-like structures in the foreground of each figure) and the projections of axial (x−zplane) and vertical (y−zplane) velocity components. Each row includes simulations at a different wind speed (2, 6, 10 m/s; from the bottom) and each column represents a different slope angle (0,15, 30 degrees; from the left). The color of the ground on the slope shows the fuel density (green for high density and brown for low density).
These results show realistic fire behaviors with good resolution in the turbulent flow field and reproduction of the waveforms in the fires. As the fuel on the ground gets burned, fire rises to tens of meters above the ground and propagates along the direction of the wind. As the fire rises, it interacts with the local wind gusts to form chaotic finger-like structures.
The differences in fire dynamics are well captured by these simulations under different wind and slope conditions. Comparing results across columns reveals insights about the effect of wind speed, indicating that increasing wind speed results in a transition from plume-driven to convective-driven behavior. In contrast, for increasing slope angle the fire tends to keep closer to the surface, resulting in a reduction of flame height (as measured normal to the slope). This observation provides evidence for conclusions made based on theoretical analysis without extensive support from data, and it suggests a transition between plume driven and convection driven fire modes as a function of wind speed and slope angle.
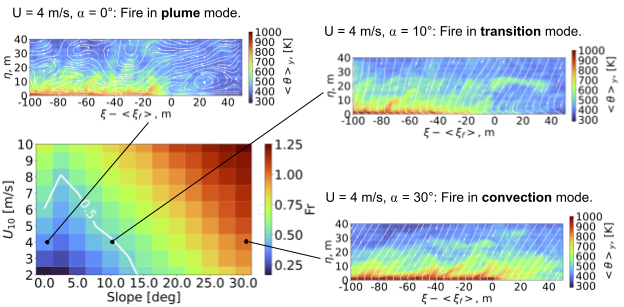
To quantify the fire-dynamics transition between the plume and convection modes, we computed the Froude number, which is a dimensionless number that measures the ratio between the flow inertia and the buoyancy. The figure below shows this regime diagram for the FireBench dataset with an indication of the critical Froude number 0.5 for the transition between plume mode and convection mode (white line).
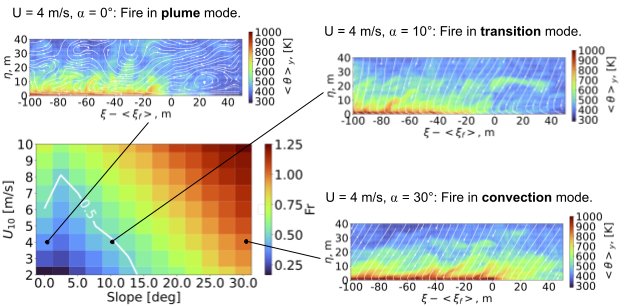
A regime diagram for the transition between the plume mode and convection mode of the fire based on the Froude number. Graphs show the fire front in the plume mode, transition mode, and the convection mode. The white contour lines are the streamlines of the flow field that is specified by the velocity vector in the streamwise and vertical directions.
Flow fields near the fire front in these two modes as well as at the transition point between them are plotted as a direct visualization of the change (subset panels). For fire in the plume mode, we see that flames are almost vertically oriented, with the large-scale fluid motion being perturbed strongly by the fire. In contrast, for fire in the convection mode, the flame attaches close to the ground, and the streamlines align along the vertical direction without large-scale perturbations.
Try it yourself
FireBench is available on Google Cloud Storage, and is organized following a tree structure. The GitHub repo contains a Colab notebook and Apache Beam pipeline that demonstrate how to access and process the dataset. The notebook presents a simple UI to browse the Firebench dataset. The script in the notebook scans the simulations in the public Firebench dataset to populate its UI dropdowns. Additionally, it can plot a simple slice of the data given the selections in the UI. The Apache Beam pipeline demonstrates how to postprocess the Firebench dataset. Each simulation contains several terabytes of data, so we use Apache Beam to run post-processing code in parallel on multiple machines to reduce the execution time. This sample script computes a time series of mean, minimum and maximum of all variables for a given simulation.
Moving forward
FireBench opens up the opportunity for fire propagation model development, fire and atmospheric dynamics investigation, and ML tasks that are related to turbulent multiphase fluid flows. In the near future, FireBench will be employed as a component of a dataset for the construction of the Future Learning Approaches for Modeling and Engineering (FLAME) AI workshop at Stanford University, which fosters a forum for exchanging ideas, data, methods, and models related to ML techniques for fluid dynamics, turbulence, and combustion fields crucial to the development of energy, propulsion, climate, and safety systems.
Google Research is committed to advancing wildfire research through the development and application of innovative technologies like FireBench as well as building technologies pushing state of the art for tracking wildfire spread. By fostering collaboration and knowledge-sharing within the research community, we aim to accelerate progress towards a future where AI-powered tools enhance wildfire prediction, prevention, and management. We believe that open access to high-quality datasets like FireBench will empower researchers to develop more sophisticated models and strategies, ultimately mitigating the devastating impacts of wildfires on communities and ecosystems globally.
Acknowledgements
This dataset is generated by the researchers in Google Research, Athena Team: Cenk Gazen, Yi-Fan Chen, Matthias Ihme, and John Anderson. Special thanks to Carla Bromberg for making it publicly available. Also thanks to Karl Alexander Toepperwien for generating the animation.
Quick links
Other posts of interest
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence

3D visualizations of fire propagation for nine ensembles when the mean location of the fire front is at 500 m. The volume renderings are of the potential temperature (indicated by the fire and smoke-like structures in the foreground of each figure) and the projections of axial (x−zplane) and vertical (y−zplane) velocity components. Each row includes simulations at a different wind speed (2, 6, 10 m/s; from the bottom) and each column represents a different slope angle (0,15, 30 degrees; from the left). The color of the ground on the slope shows the fuel density (green for high density and brown for low density).
A regime diagram for the transition between the plume mode and convection mode of the fire based on the Froude number. Graphs show the fire front in the plume mode, transition mode, and the convection mode. The white contour lines are the streamlines of the flow field that is specified by the velocity vector in the streamwise and vertical directions.