Fine-tuning LLMs with user-level differential privacy
May 23, 2025
Arun Ganesh, and Zachary Charles, Research Scientists, Google Research
We investigate and improve algorithms for fine-tuning large models with user-level differential privacy.
Quick links
The machine learning community has consistently found that while modern machine learning (ML) models are powerful, they often need to be fine-tuned on domain-specific data to maximize performance. This can be problematic or even impossible, as informative data is often privacy-sensitive. Differential privacy (DP) allows us to train ML models while rigorously guaranteeing that the learned model respects the privacy of its training data, by injecting noise into the training process.
Most work on DP focuses on the privacy of individual examples (i.e., example-level DP). This has drawbacks. If a particular user has many examples training the model, attackers may be able to learn something about that user even if they can’t learn about their individual examples.
User-level DP is a stronger form of privacy that guarantees that an attacker who uses a model can’t learn things about the user, like whether or not the user’s data is included in the training dataset. User-level DP better reflects how data is actually owned in today’s society. It’s used frequently in federated learning to train models across distributed devices like cell phones. Those devices often have many examples, all owned by a single user, and require more stringent privacy guarantees.
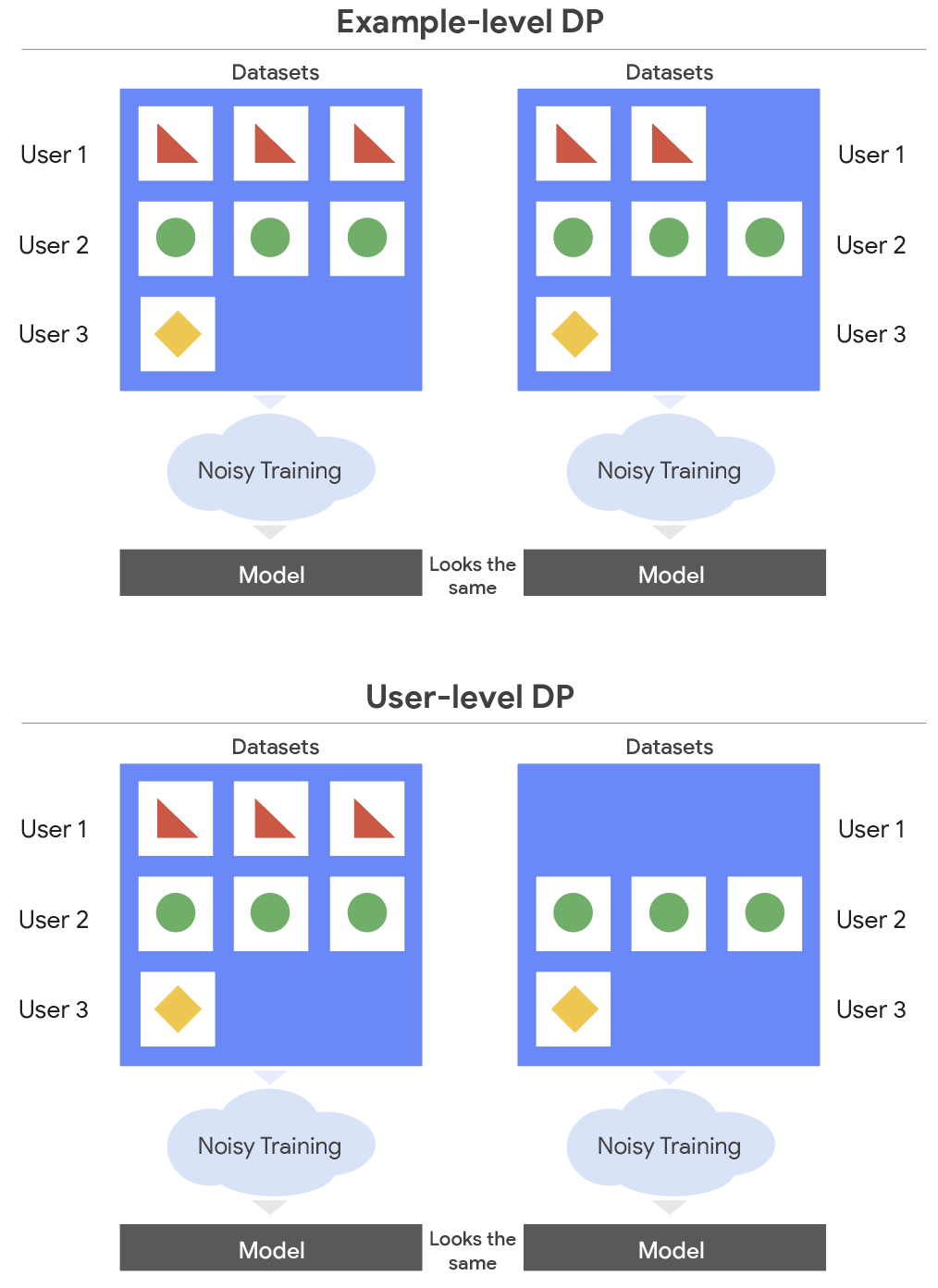
User-level DP makes it so you can’t tell if all of someone’s data was included in training or not, rather than just one piece of their data.
Learning with user-level DP is strictly harder than example-level DP, and requires adding significantly more noise. This is a problem that gets worse as the model gets larger!
In “Learning with User-Level Differential Privacy Under Fixed Compute Budgets”, we set out to scale user-level DP to large language models (LLMs) trained in the datacenter. Datacenter training is much more flexible than federated learning. In federated learning, one can only perform queries on users and not on individual examples, and it is not possible to choose which users are available to query. In datacenter training, one can query both individual examples and whole users, and it is possible to choose which ones to query every round. Our central question is, how can we use this increased flexibility to achieve better training results?
Rather than training the full LLM with DP, we focus on LLM DP fine-tuning as DP requires more computation, which might be unaffordable for full LLM training, and fine-tuning is more likely to require private domain-specific data. We determine which algorithms worked best and how to use the flexibility of datacenter training to further optimize them. This optimization is important for LLMs as even small reductions in noise can result in significant quality gains. We also show that even with the added flexibility in the datacenter, our proposed training strategy looks more like an algorithm for federated learning.
Training models with user-level privacy
Stochastic gradient descent (SGD) is a common model training algorithm that randomly divides training data into small batches, computes model updates, called “gradients”, for each example in the batch, and applies them to the model. To train with DP, we modify this slightly by adding random noise to the gradients, essentially combining DP with SGD in a process referred to as DP-SGD. The noise makes it so the model gets imperfect information about the examples during training, which is good for privacy! But since we are giving the model imperfect information, its ability to learn from the examples is necessarily weaker than if we gave it perfect information. However, DP is a prerequisite for using private data, and imperfect information about the private data is better than no information at all.

Visualizing the steps in (DP-)SGD.
DP-SGD is great for achieving example-level DP because it directly limits how much each example affects the model. It’s been extensively studied at Google, including use cases such as ads modelling and synthetic data generation.
How do we change DP-SGD if we want user-level DP? We need to make sure to limit the effect each user has on the model.
There are two ways to achieve this. For both, we first pre-process the dataset so that each user only contributes a bounded number of examples to the training dataset. Then we either:
- Apply DP-SGD as-is. By adding more noise than before, we can turn our example-level DP guarantee into user-level DP (this is the hard part!).
- Instead of sampling random examples in DP-SGD to form batches, sample random users, and then take all examples from the sampled users to form the batch.
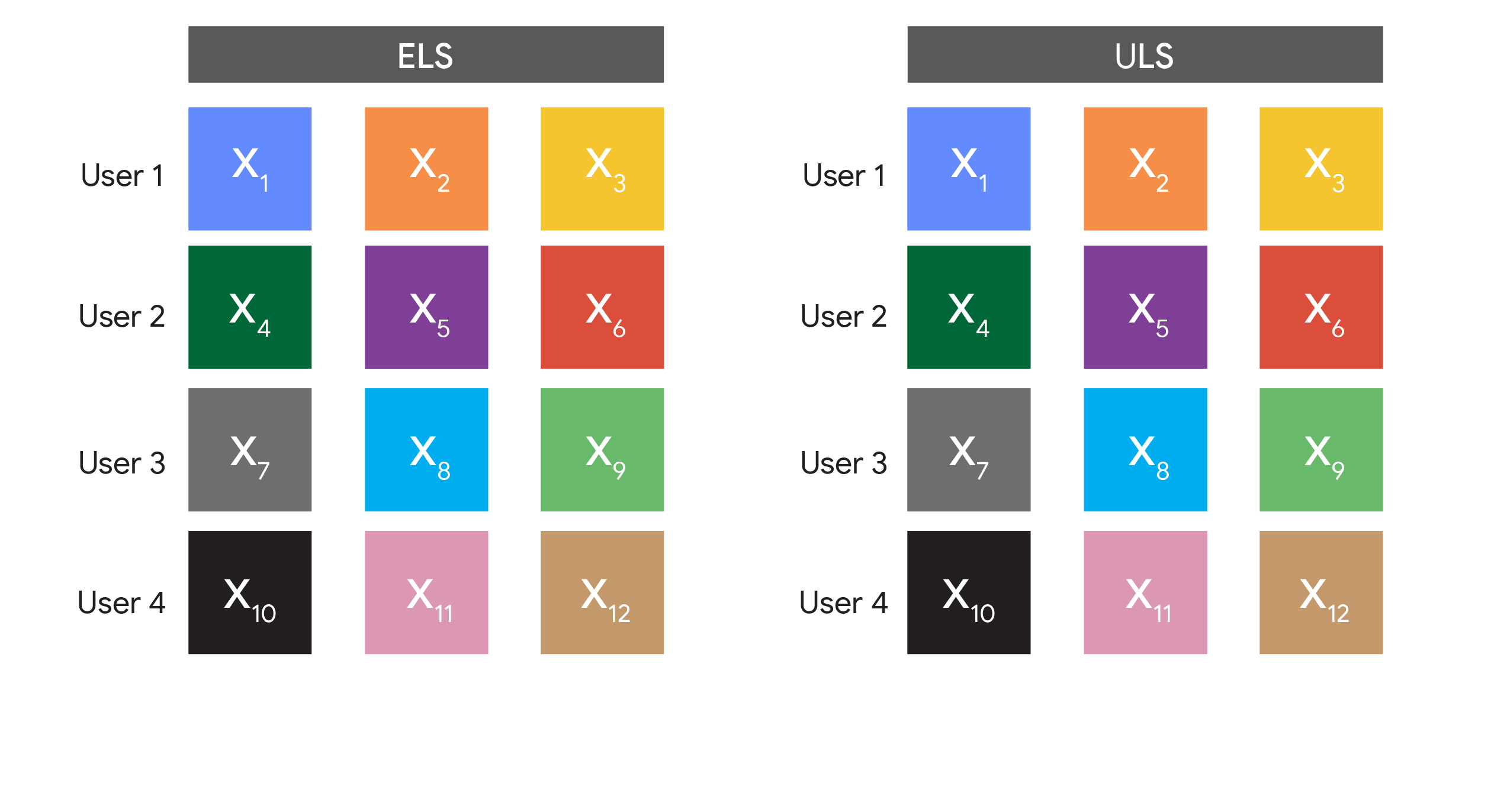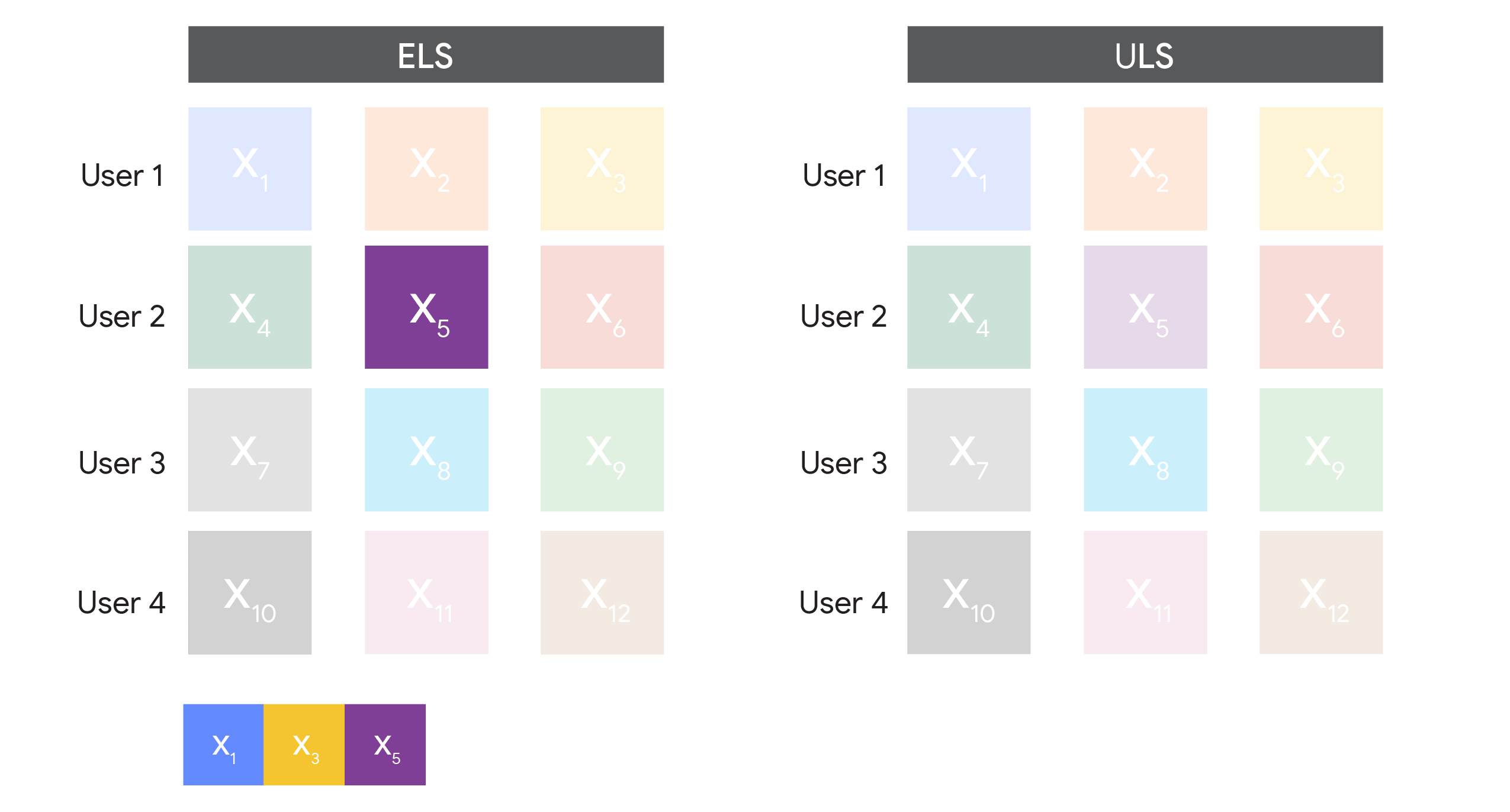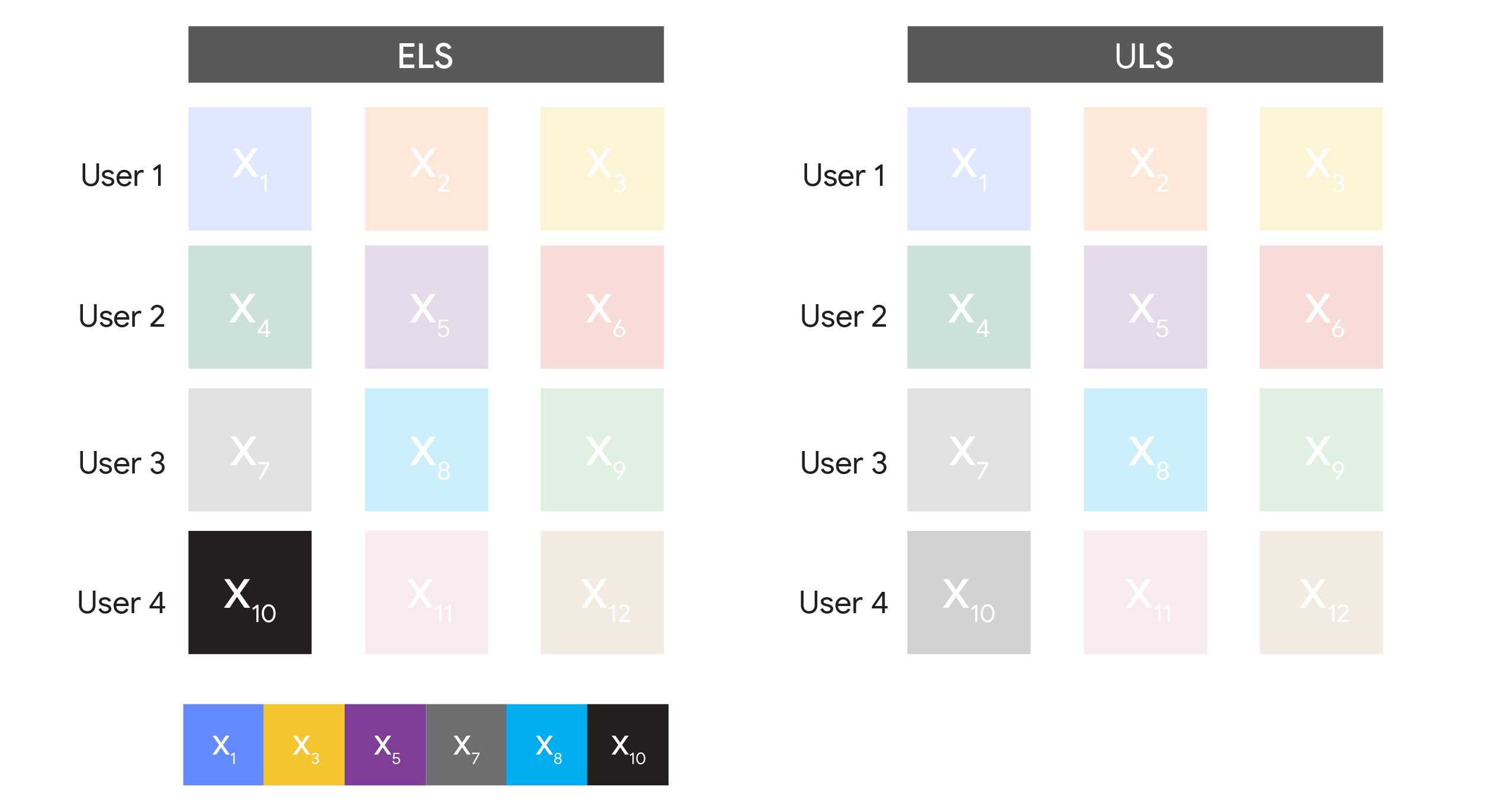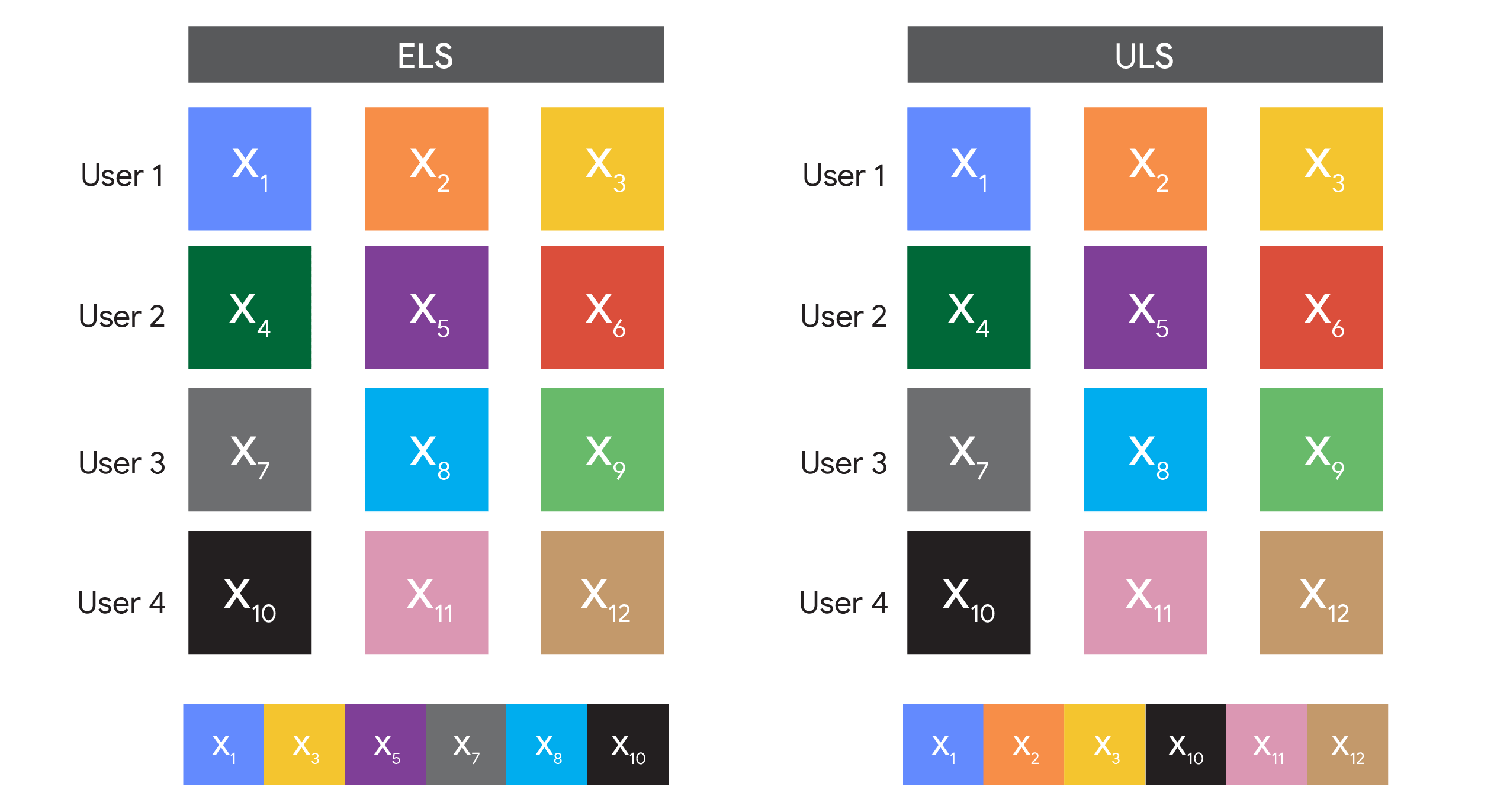
The big difference between these methods is in the data we sample. The first samples random examples, so we call it “Example-Level Sampling” (ELS). The second samples random users, so we call it “User-Level Sampling” (ULS). ULS looks a lot like federated learning in the datacenter (and is actually used in real federated learning settings, but without random sampling). Note that because of the random sampling step, both algorithms are not feasible in federated learning because devices are not necessarily available for every round of training!
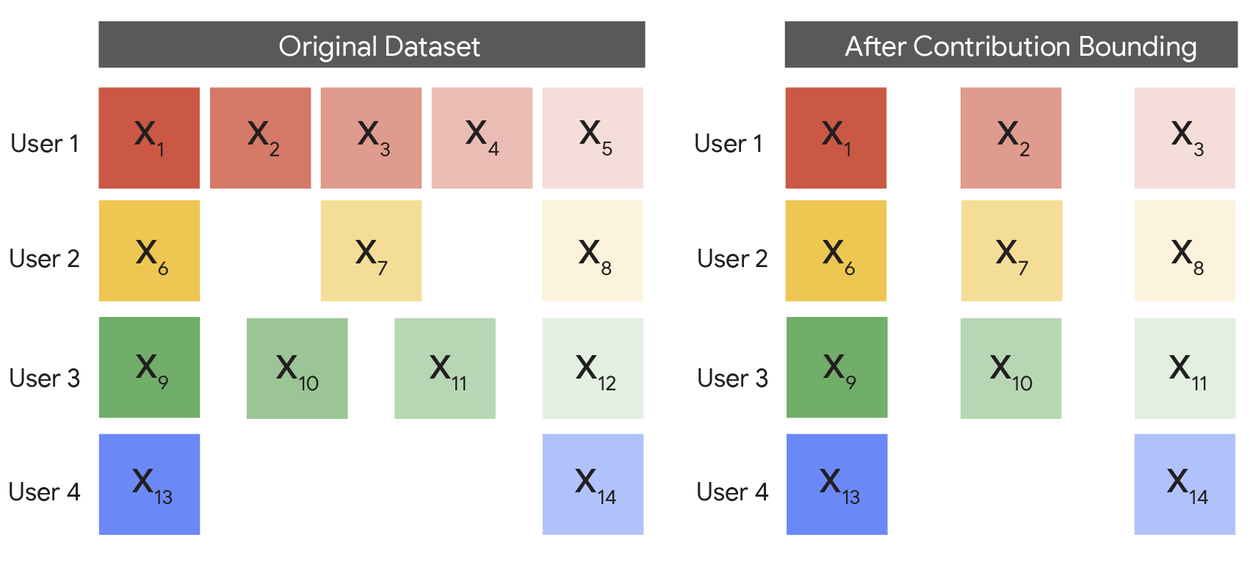
An example dataset before and after we bound the contribution of each user to at most 3.
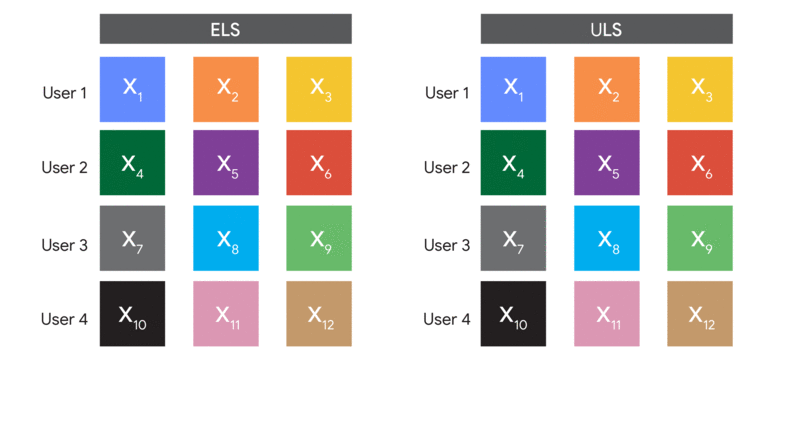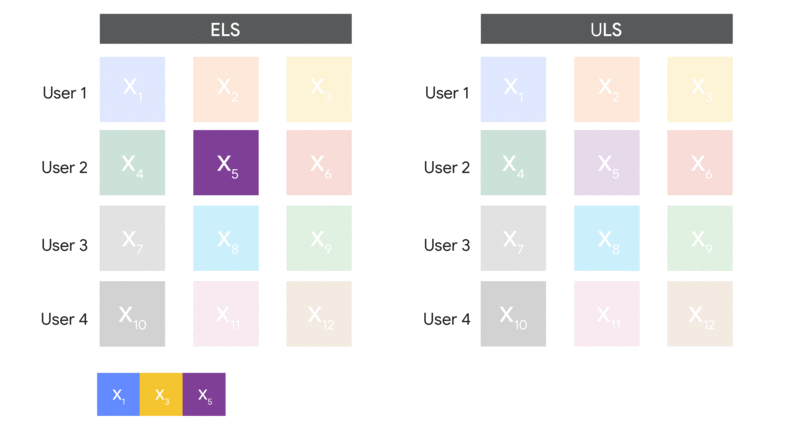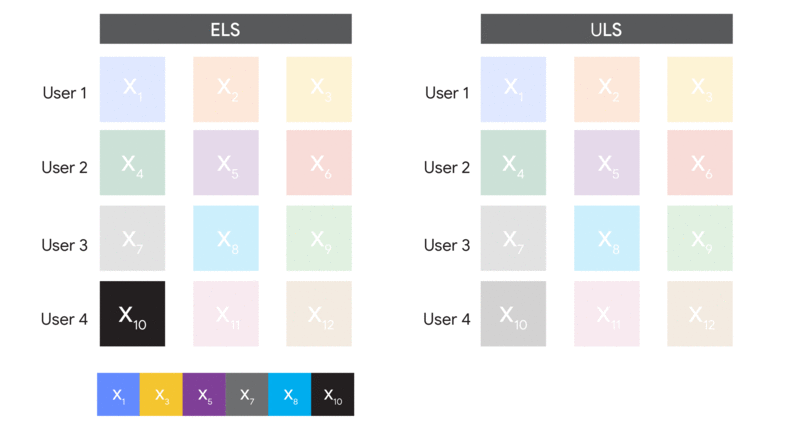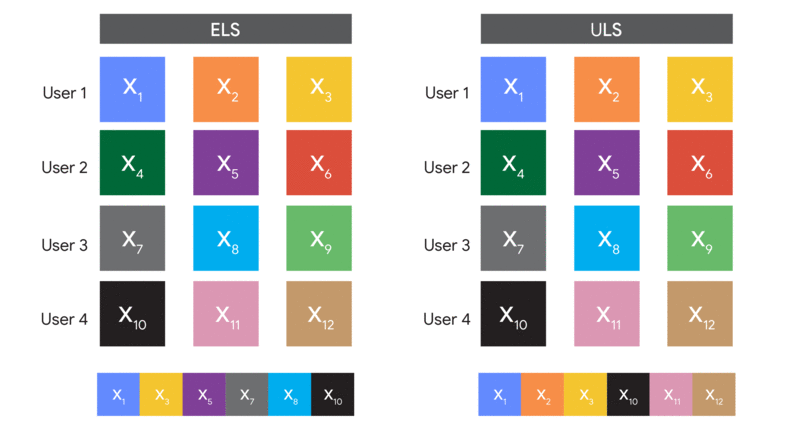
A visual comparison of how ELS and ULS form batches.
Both ELS and ULS have a key parameter to optimize: the bound on the number of examples each user can contribute to the dataset, which we call the “contribution bound”, that we use in pre-processing. As we will discuss later, this parameter needs to be carefully chosen to optimize performance.
Which of these algorithms works better, especially at scale? It’s not obvious, and it isn’t something that we found an answer to in the literature. That’s what we set out to find.
Making these algorithms work for LLMs
If we run these algorithms “out-of-the-box” for LLMs, things go badly. So, we came up with optimizations to the algorithms that fix the key issues with running them “out-of-the-box”.
For ELS, we had to go from example-level DP guarantees to user-level DP guarantees. We found that previous work was adding orders of magnitude more noise than was actually necessary. We were able to prove that we can add significantly less noise, making the model much better while retaining the same privacy guarantees.
For both ELS and ULS, we had to figure out how to optimize the contribution bound. A “default” choice is to choose a contribution bound that every user already satisfies; that is, we don’t do any pre-processing. However, some users may contribute a large amount of data, and we will need to add large amounts of noise to provide privacy to these users. Setting a smaller contribution bound reduces the amount of noise we need to add, but the cost is having to discard a lot of data. Because LLM training runs are expensive, we can’t afford to try training a bunch of models with different contribution bounds and pick the best one — we need an effective strategy to pick the contribution bound before we start training.
After lengthy experimentation at scale, for ELS we found that setting the contribution bound to be the median number of examples held by each user was an effective strategy. For ULS, we give a prediction for the total noise added as a function of the contribution bound, and found that choosing the contribution bound minimizing this prediction was an effective strategy.
Results
We first compared the amount of noise we proved was necessary for ELS to the noise past work suggested was necessary. The noise levels we determined by our analyses reflected an exponential reduction in the noise needed:
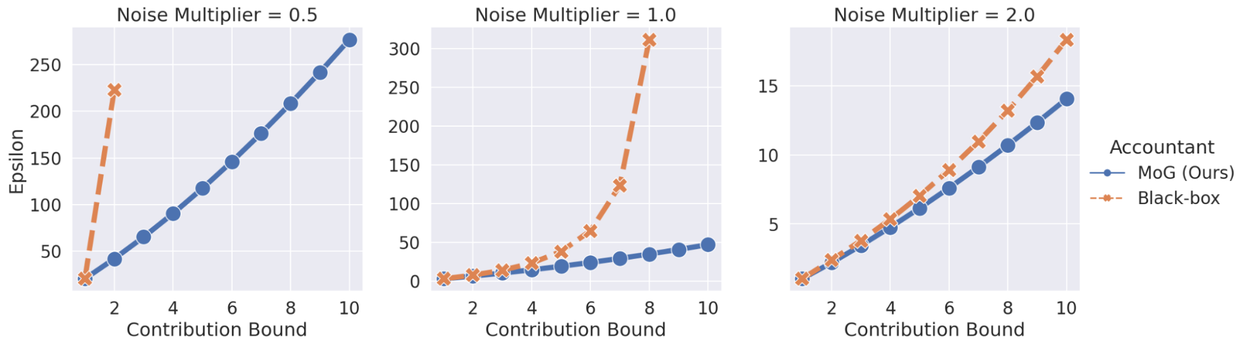
Black-box calculations suggest that privacy guarantees (ε) decay exponentially in the contribution bound. Our new bound shows the privacy guarantee only decays near-linearly in the contribution bound!
We next compared ELS and ULS, both using our optimizations, on language model fine-tuning tasks, where each algorithm saw the same total number of examples per round of training. We fine-tuned a 350 million parameter transformer model on the StackOverflow and CC-News datasets, two standard research datasets for studying user-level DP.
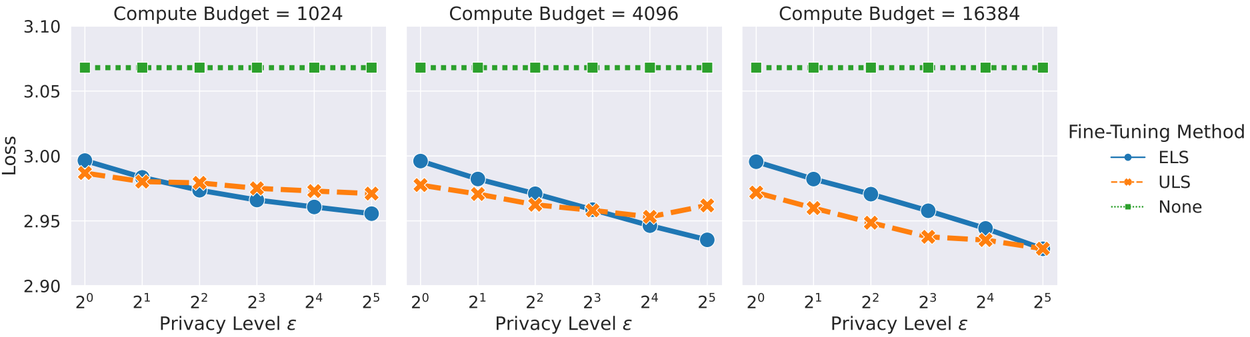
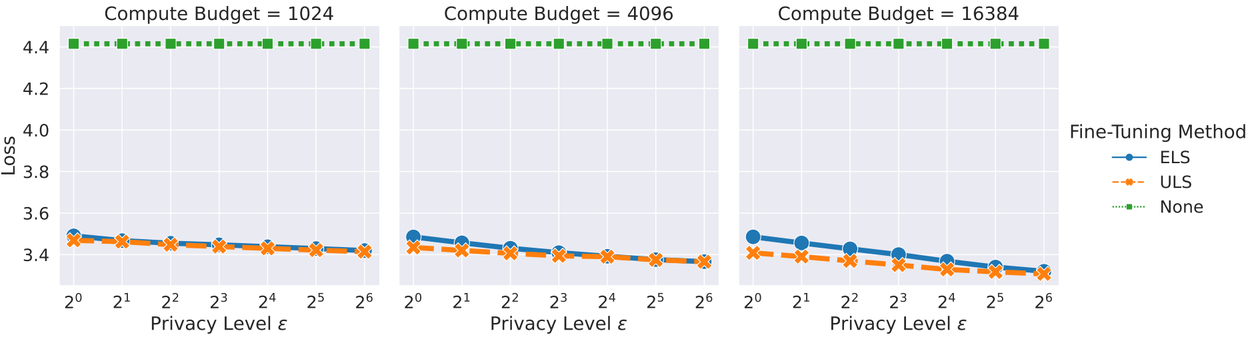
Comparing ELS, ULS, and no fine-tuning on CCNews and StackOverflow.
We found that in most cases, ULS is the better algorithm. The exception (at least for CC-News) was in cases where we wanted more privacy or don’t use much compute. Notably, in part thanks to our optimizations, both methods performed better than the pre-trained model, despite the strict privacy requirement.
Conclusion
In this work, we optimized the performance of ELS and ULS, two variants of DP-SGD that achieve user-level DP and are enabled by training in the datacenter. We optimized ELS by giving new privacy guarantees for it and by developing an heuristic for setting the contribution bound without needing to do multiple training runs. We similarly optimized ULS by developing an heuristic for setting the contribution bound, again without needing to do training runs. Our optimizations provide well-justified choices for important parameters that previously were chosen in an ad hoc manner.
Despite user-level DP being a strict privacy definition and the challenges of training large models with DP, our experiments demonstrated that fine-tuning LLMs with user-level DP is both feasible and advantageous over sticking to pre-trained models thanks to our optimizations. Our work thus enables model trainers to fine-tune their models to sensitive datasets while still providing strong protections to their users.
Quick links
Other posts of interest
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

March 11, 2026
Exploring the feasibility of conversational diagnostic AI in a real-world clinical study- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

March 4, 2026
Teaching LLMs to reason like Bayesians- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing