Few-shot tool-use doesn’t really work (yet)
May 30, 2024
Alon Jacovi, Research Scientist, Google Research
Quick links
Large language models (LLMs) are being used more and more frequently to answer queries requiring up-to-date knowledge or intricate computations (for example, “Who was born earlier: X or Y?” or “What would be my mortgage under these conditions?”). An especially popular strategy to answer such questions is with tool-use, that is, augmenting models with new capabilities (e.g., calculators and code interpreters) and external knowledge (e.g., Wikipedia and search engines) to answer such questions. For a language model to “use tools” means for the model to generate specific words that automatically invoke an external tool with a query, wherein the tool’s output is given back to the model to use as input. For example, by generating “Calculate(1 + 2)” will invoke a calculator on the input “1 + 2” and return its output “3” for further use by the model. In this way, language models can also use retrieval systems (such as retrieval-augmented generation, i.e., RAG). The tools can “make up” for inherent weaknesses of language models (such as outdated parameterized knowledge and lack of symbolic operation ability).
In the few-shot setting, by using in-context learning, the model is augmented with tools by inserting tool-use demonstrations into the prompt. There is a wide variety of proposed methods to instruct models in few-shot settings to use tools. These “tool-use strategies” claim to easily and cheaply improve performance (e.g., Self-Ask, RARR, ReAct, and Art, among others) — they allow us to define and designate tools ad-hoc without additional training, update our tools and tool APIs on the fly, and so on.
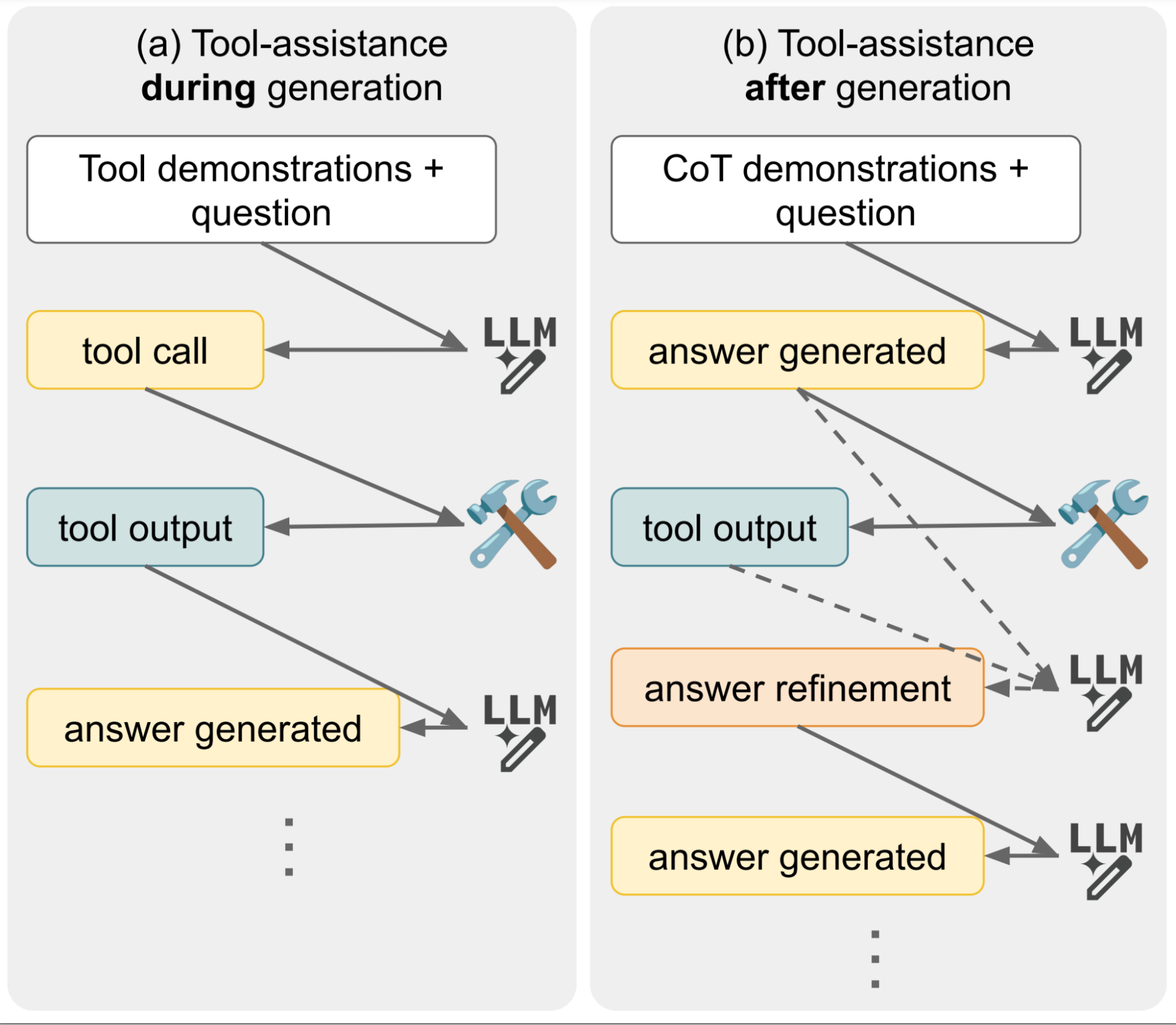
However, there are a variety of methods for achieving this — for one example, it’s possible for a model to call the tool during or after answer generation (visualized below). Since this area of research is very recent, comparisons betweens the various methods have not been studied. Thus, it is unclear which methods are better than others, what are the trade-offs, and how they compare to other strategies that don’t use tools at all.
Illustration of different methods of integrating tools with LMs. It’s possible for the model to call the tool while generating its answer, or after generating its answer, and this choice has different implications for efficiency and performance.
In “A Comprehensive Evaluation of Tool-Assisted Generation Strategies”, we undertake a large-scale evaluation of many different tool-use algorithms. Our main question is: Does few-shot tool assistance work? Surprisingly, we found that it generally does not perform better than an LM operating without tools! Additionally, we found significant differences in efficiency between algorithms and a large variance in results depending on the experiment parameters, suggesting a need to require more thorough evaluation schemes to derive reliable insights. Below we highlight the key analyses, across a variety of settings.
How effective is few-shot tool use in practice?
We ran comprehensive evaluations, conducting over 340 experiments with different tools, models, prompts, demonstrations, strategies, and so on. We took extra care to design representative evaluations with strong but realistic no-tool baselines (such as letting the LM emulate the tool for every strategy).
Below are three examples of some of the tool-use strategies that we evaluated. SelfAsk uses natural-sounding instructions to prompt the model to decompose the question into simpler questions, and each simpler question is then answered using a retrieval tool. Inline (e.g., Toolformer) is more directly inspired by programming, treating tools as functions that are called with a keyword and input in brackets, to accomplish the same goal of decomposing the question into simple sub-questions. Finally, RARR uses an extensive chain of prompts to generate sub-questions, use a tool, validate its output, and rephrase it to give an answer.
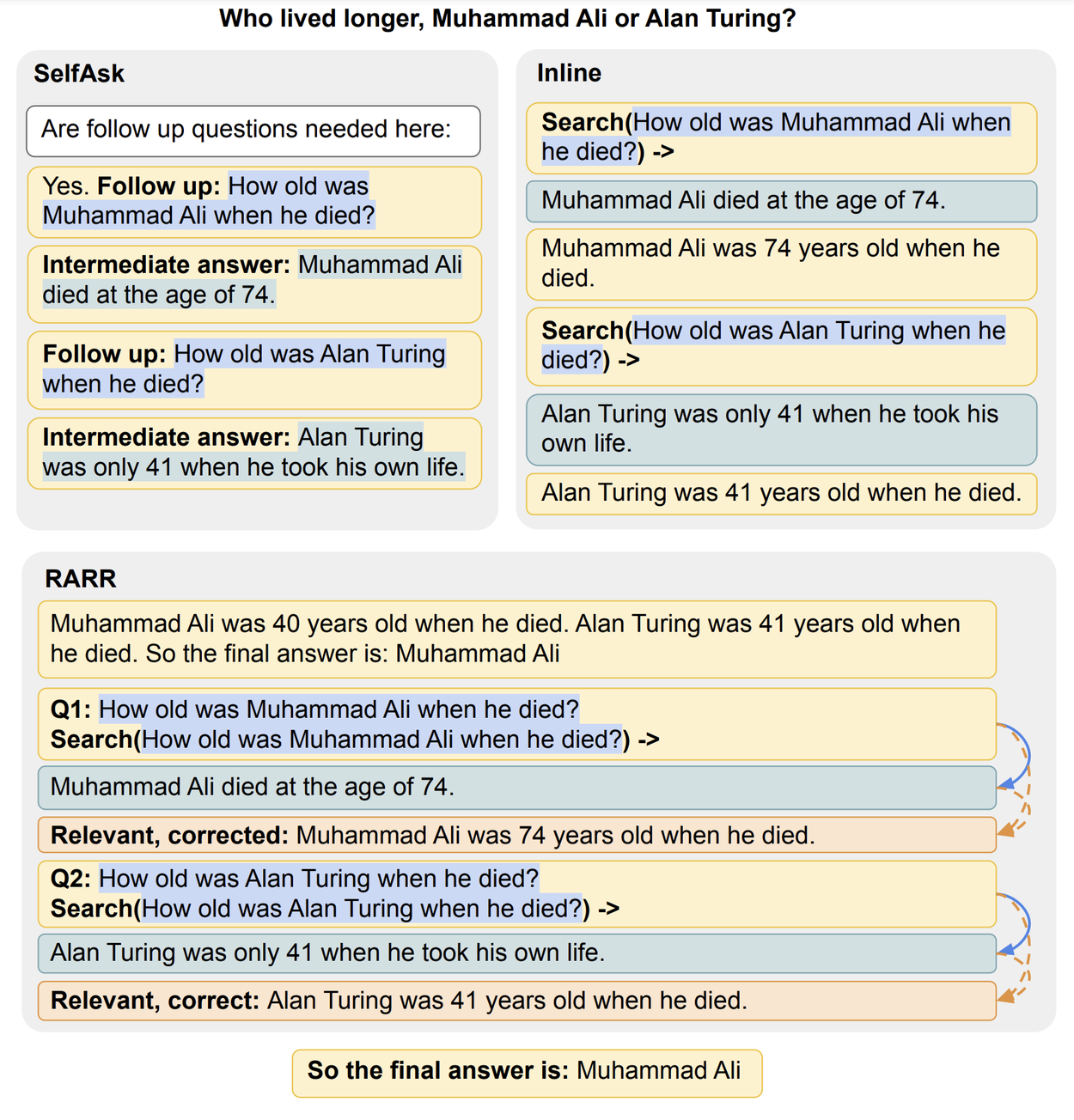
Various strategies for demonstrating tool-use to models with in-context learning. In the examples above, the model is using a question-retrieval system as a tool to retrieve information about Muhammad Ali and Alan Turing. For more examples, see Figure 2 in the paper.
The results were clear: in almost all settings of popular academic question-answering (QA) benchmarks, there was no improvement from using tools compared to not using tools.

A popular hypothesis, or common wisdom, is that tools can help LMs perform better on harder examples, like examples that have rare entities or difficult calculations, since LMs find such cases difficult. We detected such examples by using Wikipedia data and numerical ranges. But we found no significant improvement there, either: in the charts below, scores with tools were higher neither for rarer entities (shown in the top row) nor for difficult calculations (bottom row).
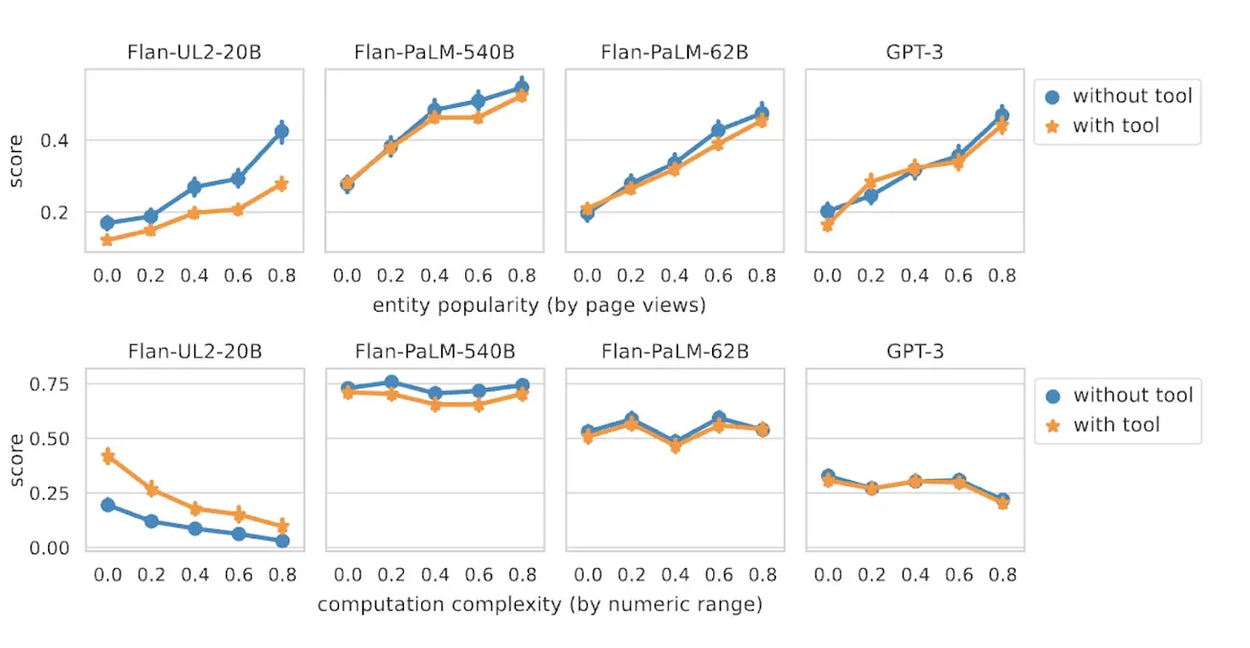
Evaluation results comparing tool-using LMs with standard LMs, for various models and tasks, for different measures of example difficulty.
What’s the best way to use tools?
Next, we ran some additional comparative tests: For example, as mentioned above, is it better to instruct the LM to use tools during its answer generation, or to verify and edit its own answer with tools after it has been generated? We compared the two in a variety of settings.
We found that for mathematical settings with a calculator tool, the two strategies were comparable, but for knowledge-seeking tasks with a retrieval tool (such as a search engine), editing the answer after it was generated was measurably better.
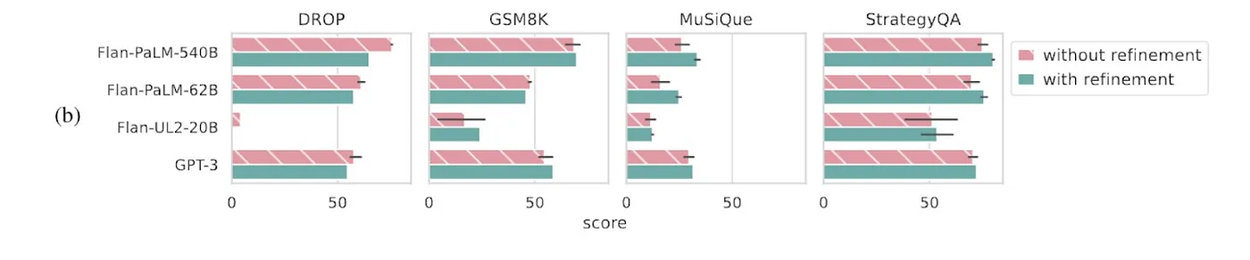
Evaluation results comparing tool-use during generation (“without refinement”), and tool-use to fix generated content (“with refinement”).
Not just performance: What about efficiency?
The final question we examined was about the efficiency of various strategies. Often, different methods of tool-use are evaluated by their performance, but we wanted to know how they compare in terms of their computational efficiency, and measure the trade-off — if it exists — between the two. If all else is equal between two strategies for tool-use, then an easy way to compare their efficiency is to compare how many tokens (pieces of words or characters) they require in the prompt, and how many extra tokens they generate above the baseline. The baseline in this case is the same model without any tool-use strategies. In this way, the efficiency of different tool-use strategies can be directly compared to each other.
We found that overall, there were significant differences in efficiency between various strategies. For example, certain methods cost 2× or 3× as much as others, and as much as 10× more than using no tools at all. These significant multipliers in cost do not necessarily translate into increased performance, which shows just how important it is to also measure efficiency. Please refer to the paper for the full calculations and results for this conclusion.
Call to action: How should we properly evaluate few-shot LMs with tools?
Throughout this large-scale evaluation, we surfaced some lessons about how to more reliably evaluate LMs in few-shot settings, especially for tool-use and RAG comparisons. Here are five key pitfalls and our corresponding recommendations:
- Coupling the tool-use strategy and the tool together — comparisons of tool-use strategies should use the same tools across strategies.
- Forcing no-tool baselines to the framework of the tool-use strategy — the optimal way to solve the task without tools may be different to optimally solving the task with tools: No-tool baselines should include multiple variants of both free-form and structured strategies, to ensure the tool-use variants are not given an advantage.
- Using one model across all comparisons — different models may behave differently when it comes to using tools effectively, based on their training data. Multiple models should be tested.
- Using one prompt and set of demonstrations across all comparisons. Multiple different sets of demonstrations and prompts should be used to get reliable estimates of few-shot performance.
- Not considering tool-use strategy costs — tool-use strategies can be efficient or inefficient with regards to the extra tokens they require to work. The differences can be significant. Comparisons of strategies should factor the computation cost of the strategy.
If you are working on novel few-shot methods, with tool-use, RAG, or otherwise, consider these lessons when designing your evaluations!
Conclusion
Overall, we found that few-shot tool assistance, without explicitly training models to use tools, is a difficult and unsolved problem, with significant costs. This is in contrast to their commonly perceived value as an easy and cheap solution to augment LMs with tools, such as retrieval or calculation. Beyond few-shot strategies, training models to use tools seems to be more promising (and a popular paradigm in recent months — such as with Gemini, GPT-4 and Command-R).
Quick links
Other posts of interest
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 26, 2026
Accelerating Gemini Nano models on Pixel with frozen Multi-Token Prediction- Machine Intelligence ·
- Mobile Systems ·
- Natural Language Processing
-

June 24, 2026
Thinking to recall: How reasoning unlocks parametric knowledge in LLMs- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing

Evaluation results comparing tool-using LMs with standard LMs, for various models and tasks, for different measures of example difficulty.

Evaluation results comparing tool-use during generation (“without refinement”), and tool-use to fix generated content (“with refinement”).
Illustration of different methods of integrating tools with LMs. It’s possible for the model to call the tool while generating its answer, or after generating its answer, and this choice has different implications for efficiency and performance.

Various strategies for demonstrating tool-use to models with in-context learning. In the examples above, the model is using a question-retrieval system as a tool to retrieve information about Muhammad Ali and Alan Turing. For more examples, see Figure 2 in the paper.
