FedJAX: Federated Learning Simulation with JAX
October 4, 2021
Posted by Jae Hun Ro, Software Engineer and Ananda Theertha Suresh, Research Scientist, Google Research
Quick links
Federated learning is a machine learning setting where many clients (i.e., mobile devices or whole organizations, depending on the task at hand) collaboratively train a model under the orchestration of a central server, while keeping the training data decentralized. For example, federated learning makes it possible to train virtual keyboard language models based on user data that never leaves a mobile device.
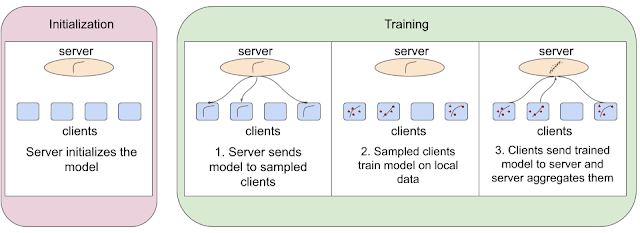
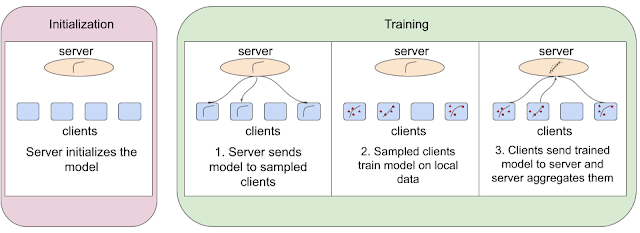
Federated learning algorithms accomplish this by first initializing the model at the server and completing three key steps for each round of training:
- The server sends the model to a set of sampled clients.
- These sampled clients train the model on local data.
- After training, the clients send the updated models to the server and the server aggregates them together.
 |
| An example federated learning algorithm with four clients. |
Federated learning has become a particularly active area of research due to an increased focus on privacy and security. Being able to easily translate ideas into code, iterate quickly, and compare and reproduce existing baselines is important for such a fast growing field.
In light of this, we are excited to introduce FedJAX, a JAX-based open source library for federated learning simulations that emphasizes ease-of-use in research. With its simple building blocks for implementing federated algorithms, prepackaged datasets, models and algorithms, and fast simulation speed, FedJAX aims to make developing and evaluating federated algorithms faster and easier for researchers. In this post we discuss the library structure and contents of FedJAX. We demonstrate that on TPUs FedJAX can be used to train models with federated averaging on the EMNIST dataset in a few minutes, and the Stack Overflow dataset in roughly an hour with standard hyperparameters.
Library Structure
Keeping ease of use in mind, FedJAX introduces only a few new concepts. Code written with FedJAX resembles the pseudo-code used to describe novel algorithms in academic papers, making it easy to get started. Additionally, while FedJAX provides building blocks for federated learning, users can replace these with the most basic implementations using just NumPy and JAX while still keeping the overall training reasonably fast.
Included Dataset and Models
In the current landscape of federated learning research, there are a variety of commonly used datasets and models, such as image recognition, language modeling, and more. A growing number of these datasets and models can be used straight out of the box in FedJAX, so the preprocessed datasets and models do not have to be written from scratch. This not only encourages valid comparisons between different federated algorithms but also accelerates the development of new algorithms.
At present, FedJAX comes packaged with the following datasets and sample models:
- EMNIST-62, a character recognition task
- Shakespeare, a next character prediction task
- Stack Overflow, a next word prediction task
In addition to these standard setups, FedJAX provides tools to create new datasets and models that can be used with the rest of the library. Finally, FedJAX comes with standard implementations of federated averaging and other federated algorithms for training a shared model on decentralized examples, such as adaptive federated optimizers, agnostic federated averaging, and Mime, to make comparing and evaluating against existing algorithms easier.
Performance Evaluation
We benchmarked a standard FedJAX implementation of adaptive federated averaging on two tasks: the image recognition task for the federated EMNIST-62 dataset and the next word prediction task for the Stack Overflow dataset. Federated EMNIST-62 is a smaller dataset that consists of 3400 users and their writing samples, which are one of 62 characters (alphanumeric), while the Stack Overflow dataset is much larger and consists of millions of questions and answers from the Stack Overflow forum for hundreds of thousands of users.
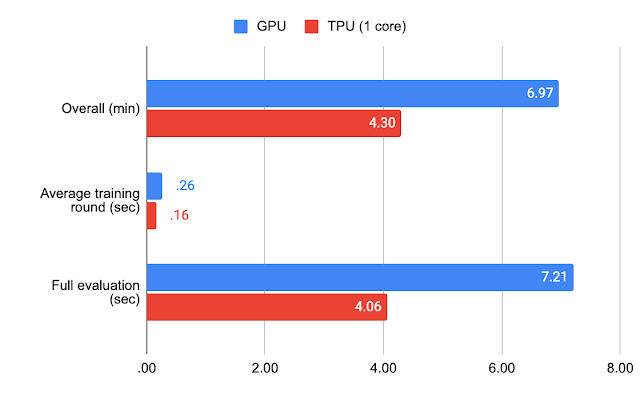
We measured performance on various hardware specialized for machine learning. For federated EMNIST-62, we trained a model for 1500 rounds with 10 clients per round on GPU (NVIDIA V100) and TPU (1 TensorCore on a Google TPU v2) accelerators.
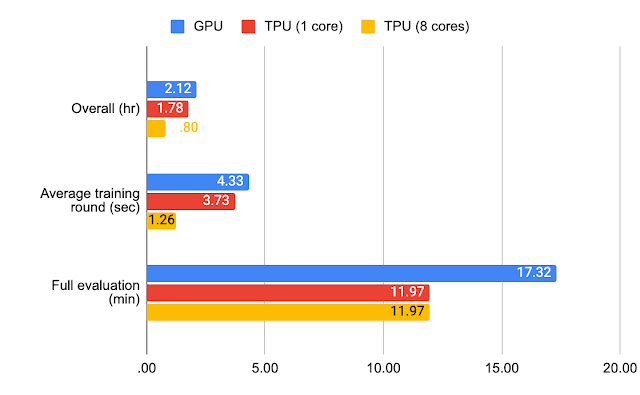
For Stack Overflow, we trained a model for 1500 rounds with 50 clients per round on GPU (NVIDIA V100) using jax.jit, TPU (1 TensorCore on a Google TPU v2) using only jax.jit, and multi-core TPU (8 TensorCores on a Google TPU v2) using jax.pmap. In the charts below, we’ve recorded the average training round completion time, time taken for full evaluation on test data, and time for the overall execution, which includes both training and full evaluation.
 |
| Benchmark results for federated EMNIST-62. |
 |
| Benchmark results for Stack Overflow. |
With standard hyperparameters and TPUs, the full experiments for federated EMNIST-62 can be completed in a few minutes and roughly an hour for Stack Overflow.
 |
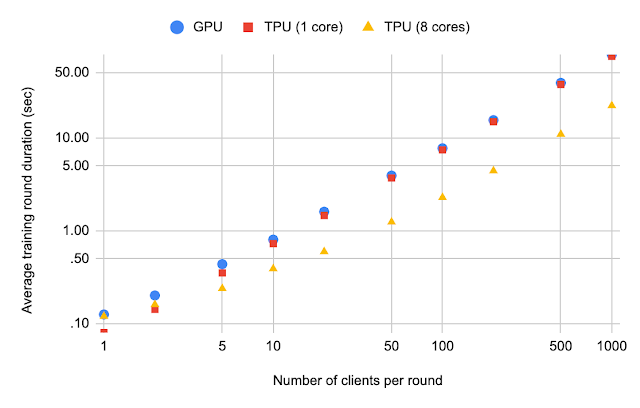
| Stack Overflow average training round duration as the number of clients per round increases. |
We also evaluate the Stack Overflow average training round duration as the number of clients per round increases. By comparing the average training round duration between TPU (8 cores) and TPU (1 core) in the figure, it is evident that using multiple TPU cores results in considerable runtime improvement if the number of clients participating per round is large (useful for applications like differentially private learning).
Conclusions and Future Work
In this post, we introduced FedJAX, a fast and easy-to-use federated learning simulation library for research. We hope that FedJAX will foster even more investigation and interest in federated learning. Moving forward, we plan to continually grow our existing collection of algorithms, aggregation mechanisms, datasets, and models.
Feel free to take a look at some of our tutorial notebooks, or try out FedJAX yourself! For more information about the library and relationship to platforms, such as Tensorflow Federated, see our paper, README, or FAQs.
Acknowledgements
We would like to thank Ke Wu and Sai Praneeth Kamireddy for contributing to the library and various discussions during development.
We would also like to thank Ehsan Amid, Theresa Breiner, Mingqing Chen, Fabio Costa, Roy Frostig, Zachary Garrett, Alex Ingerman, Satyen Kale, Rajiv Mathews, Lara Mcconnaughey, Brendan McMahan, Mehryar Mohri, Krzysztof Ostrowski, Max Rabinovich, Michael Riley, Vlad Schogol, Jane Shapiro, Gary Sivek, Luciana Toledo-Lopez, and Michael Wunder for helpful comments and contributions.
Quick links
Other posts of interest
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence