Extending video masked autoencoders to 128 frames
December 4, 2024
Nitesh Bharadwaj Gundavarapu, Sr. Software Engineer, and Luke Friedman, Staff Software Engineer, Google Research
In this work, we propose to extend masked video modeling to long-videos by adaptively reconstructing only the most important tokens from a powerful tokenizer.
Quick links
Learning robust representations from video that simultaneously capture high-level semantics and fine-grained motion is an important research challenge with applications to many domains ranging from video search to robotics and virtual agents. Recent progress in this field has been fueled by the development of powerful self-supervised learning techniques, especially masked autoencoders (MAEs). For example, VideoMAE achieves impressive results on action recognition benchmarks by reconstructing masked video frames, while video foundation models like VideoPrism and InternVideo use MAEs as a core part of their pipelines. However, traditional MAEs face limitations in processing long videos due to computational bottlenecks and thus only train on short clips as context — they only look at a small snippet of the video at a time
In our new research paper, "Extending Video Masked Autoencoders to 128 Frames", we develop a novel approach for reducing the computational load of training video models on longer contexts and show that doing so significantly improves the quality of the learned representations. By demonstrating the utility of long-context video MAE training and providing the technical tools to make it tractable, we hope to pave the way for significant advancements in long-form video understanding.
The long video challenge
Traditional MAEs for video understanding typically operate on short video clips, usually 16 or 32 frames in length. This constraint arises from the computational demands of the self-attention mechanism used in the decoder, which scales poorly with video length. Consequently, existing methods struggle to capture long-range temporal dependencies that are essential for understanding complex actions and events in longer videos, e.g., gymnastics routines or intricate cooking procedures.
Our solution: Adaptive decoder masking
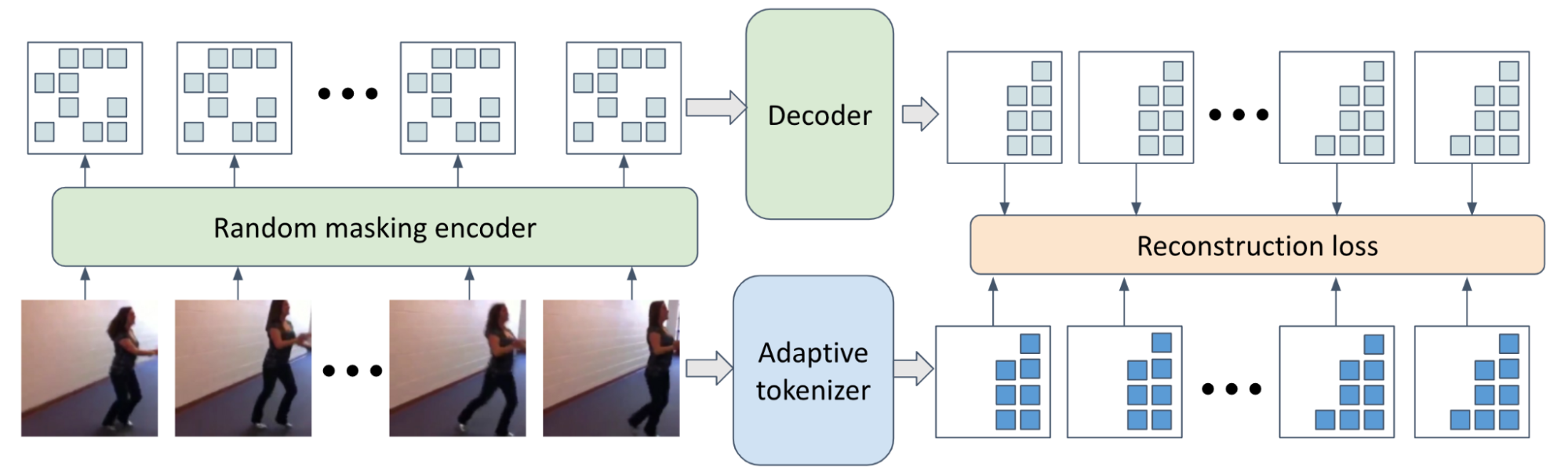
To address the challenge posed by long videos, we introduce a novel approach called "adaptive decoder masking." This technique strategically reconstructs only the most important tokens in the video during the decoding process, reducing computational costs and enabling the processing of videos up to 128 frames in length on a single machine.
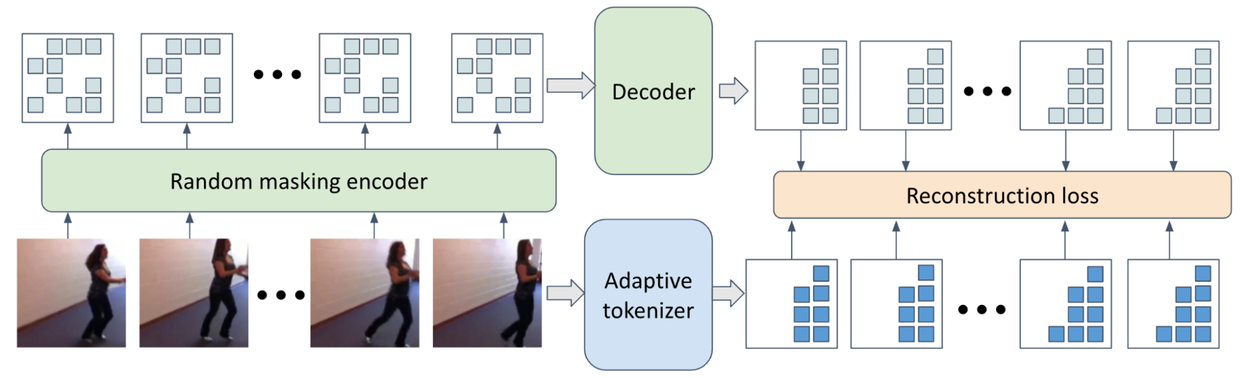
Illustration of adaptive decoder masking during pre-training.
Our adaptive masking strategy leverages a powerful tokenizer based on the MAGVIT architecture. This tokenizer jointly learns the tokens and their importance using a token scorer module, allowing the model to prioritize the most informative tokens for reconstruction. This tokenizer is learned independently of the masked modeling framework.
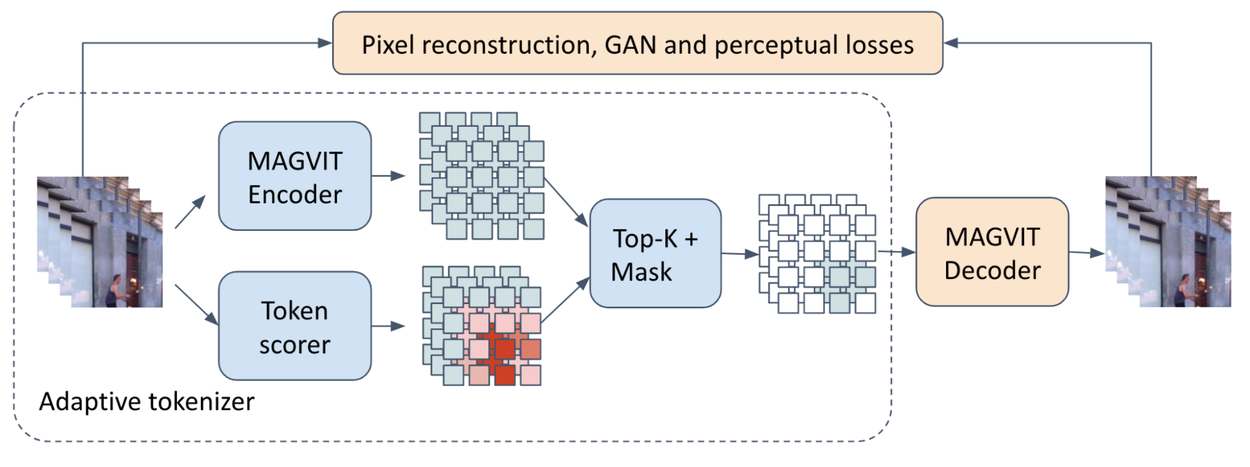
Illustration of the adaptive tokenizer based on MAGVIT encoder.
Key findings
We conducted extensive experiments on benchmark datasets, such as EPIC-Kitchens-100 and Diving-48, to evaluate the effectiveness of our approach. Here are some of our key findings:
- Improved performance: The adaptive decoder masking strategy outperforms traditional uniform and motion-based masking strategies in terms of accuracy.
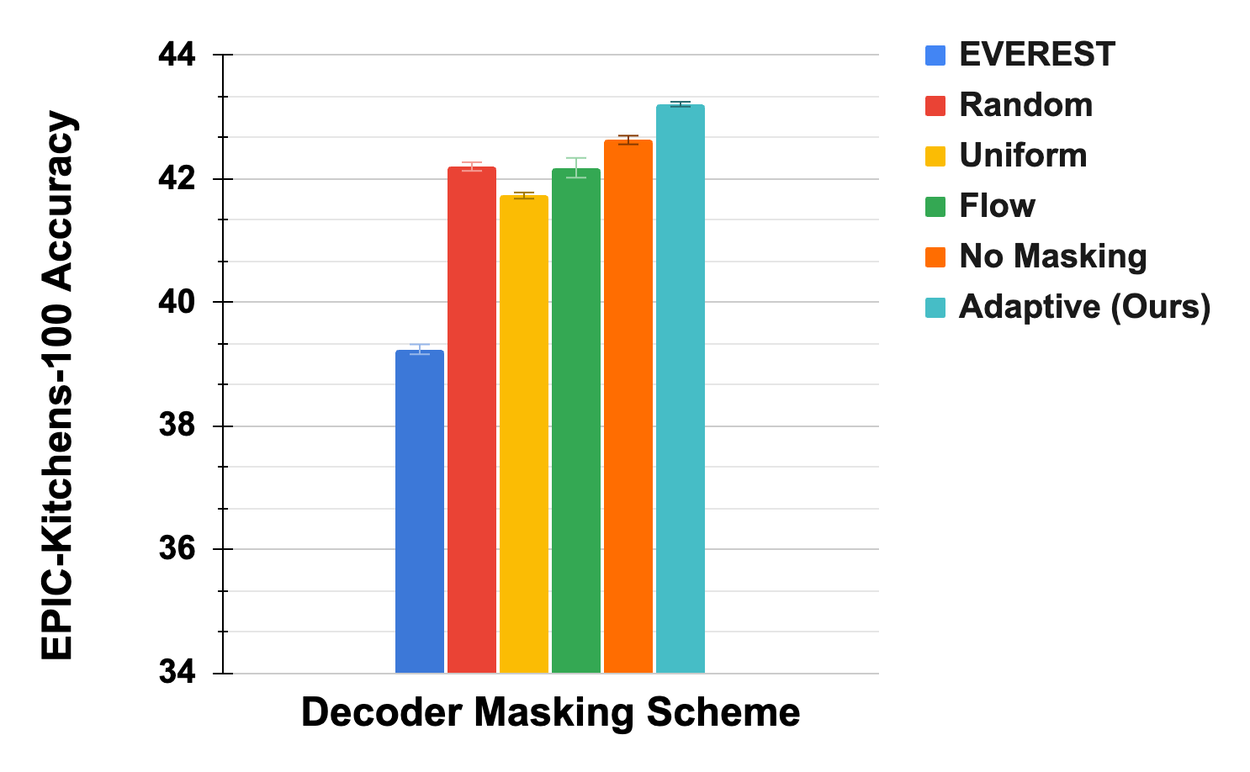
- Long-video pre-training: The memory efficiency gained through adaptive masking enables pre-training on long videos (128 frames), leading to substantial performance gains compared to short-video pre-training.

- State-of-the-art results: Our approach achieves state-of-the-art performance on the Diving-48 dataset, surpassing previous methods by 2.7 points. It also shows competitive results on EPIC-Kitchens-100, particularly excelling in verb classification, which is crucial for understanding actions.
Future directions
Although enabling MAE to learn from 128 frames is a large jump over the previous state of the art, at higher frame rates this still only covers a few seconds of video. Ultimately, we would like to be able to learn from videos many minutes or hours long, while still maintaining the fine-grained understanding needed for applications such as action recognition, video summarization and world modeling. So, in the future we plan to extend our research by evaluating our long video encoder in a larger system that streams videos in chunks, and possibly to augment it with external memory. We believe our research is an important initial step towards realizing the vision of learning from truly long videos and enabling AI systems to better understand and interact with the world through video.
Acknowledgements
This work was conducted by a team of researchers within Google Research
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence


