Expressive Speech Synthesis with Tacotron
March 27, 2018
Posted by Yuxuan Wang, Research Scientist and RJ Skerry-Ryan, Software Engineer, on behalf of the Machine Perception, Google Brain and TTS Research teams
Quick links
At Google, we're excited about the recent rapid progress of neural network-based text-to-speech (TTS) research. In particular, end-to-end architectures, such as the Tacotron systems we announced last year, can both simplify voice building pipelines and produce natural-sounding speech. This will help us build better human-computer interfaces, like conversational assistants, audiobook narration, news readers, or voice design software. To deliver a truly human-like voice, however, a TTS system must learn to model prosody, the collection of expressive factors of speech, such as intonation, stress, and rhythm. Most current end-to-end systems, including Tacotron, don't explicitly model prosody, meaning they can't control exactly how the generated speech should sound. This may lead to monotonous-sounding speech, even when models are trained on very expressive datasets like audiobooks, which often contain character voices with significant variation. Today, we are excited to share two new papers that address these problems.
Our first paper, “Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron”, introduces the concept of a prosody embedding. We augment the Tacotron architecture with an additional prosody encoder that computes a low-dimensional embedding from a clip of human speech (the reference audio).
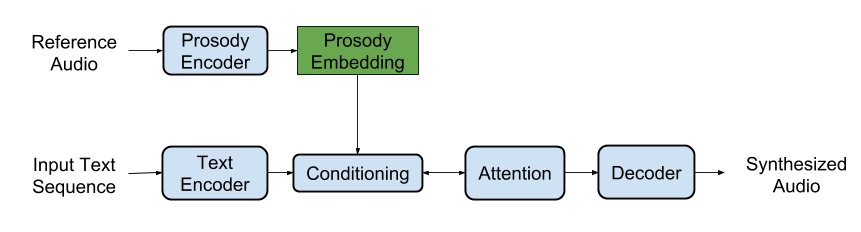 |
| We augment Tacotron with a prosody encoder. The lower half of the image is the original Tacotron sequence-to-sequence model. For technical details, please refer to the paper. |
Text: *Is* that Utah travel agency?
| Reference prosody (Australian) | |
| Synthesized without prosody embedding (American) | |
| Synthesized with prosody embedding (American) |
The embedding can also transfer fine time-aligned prosody from one phrase to a slightly different phrase, though this technique works best when the reference and target phrases are similar in length and structure.
Reference Text: For the first time in her life she had been danced tired.
Synthesized Text: For the last time in his life he had been handily embarrassed.
| Reference prosody (American) | |
| Synthesized without prosody embedding (American) | |
| Synthesized with prosody embedding (American) |
Excitingly, we observe prosody transfer even when the reference audio comes from a speaker whose voice is not in Tacotron's training data.
Text: I've Swallowed a Pollywog.
| Reference prosody (Unseen American Speaker) | |
| Synthesized without prosody embedding (British) | |
| Synthesized with prosody embedding (British) |
This is a promising result, as it paves the way for voice interaction designers to use their own voice to customize speech synthesis. You can listen to the full set of audio demos for “Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron” on this web page.
Despite their ability to transfer prosody with high fidelity, the embeddings from the paper above don't completely disentangle prosody from the content of a reference audio clip. (This explains why they transfer prosody best to phrases of similar structure and length.) Furthermore, they require a clip of reference audio at inference time. A natural question then arises: can we develop a model of expressive speech that alleviates these problems?
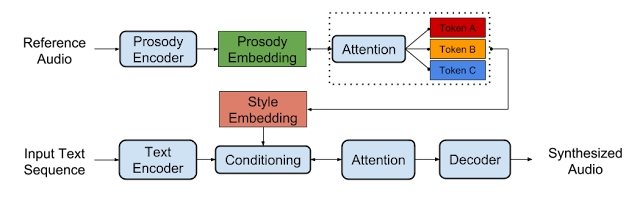
In our second paper, “Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis”, we do just that. Building upon the architecture in our first paper, we propose a new unsupervised method for modeling latent "factors" of speech. The key to this model is that, rather than learning fine time-aligned prosodic elements, it learns higher-level speaking style patterns that can be transferred across arbitrarily different phrases.
The model works by adding an extra attention mechanism to Tacotron, forcing it to represent the prosody embedding of any speech clip as the linear combination of a fixed set of basis embeddings. We call these embeddings Global Style Tokens (GSTs), and find that they learn text-independent variations in a speaker's style (soft, high-pitch, intense, etc.), without the need for explicit style labels.
 |
| Model architecture of Global Style Tokens. The prosody embedding is decomposed into “style tokens” to enable unsupervised style control and transfer. For technical details, please refer to the paper. |
Text: United Airlines five six three from Los Angeles to New Orleans has Landed.
| Style 1 | |
| Style 2 | |
| Style 3 | |
| Style 4 | |
| Style 5 |
Finally, our paper shows that Global Style Tokens can model more than just speaking style. When trained on noisy YouTube audio from unlabeled speakers, a GST-enabled Tacotron learns to represent noise sources and distinct speakers as separate tokens. This means that by selecting the GSTs we use in inference, we can synthesize speech free of background noise, or speech in the voice of a specific unlabeled speaker from the dataset. This exciting result provides a path towards highly scalable but robust speech synthesis. You can listen to the full set of demos for "Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis" on this web page.
We are excited about the potential applications and opportunities that these two bodies of research enable. In the meantime, there are new important research problems to be addressed. We'd like to extend the techniques of the first paper to support prosody transfer in the natural pitch range of the target speaker. We'd also like to develop techniques to select appropriate prosody or speaking style automatically from context, using, for example, the integration of natural language understanding with TTS. Finally, while our first paper proposes an initial set of objective and subjective metrics for prosody transfer, we'd like to develop these further to help establish generally-accepted methods for prosodic evaluation.
Acknowledgements
These projects were done jointly between multiple Google teams. Contributors include RJ Skerry-Ryan, Yuxuan Wang, Daisy Stanton, Eric Battenberg, Ying Xiao, Joel Shor, Rif A. Saurous, Yu Zhang, Ron J. Weiss, Rob Clark, Fei Ren and Ye Jia.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
×
❮
❯